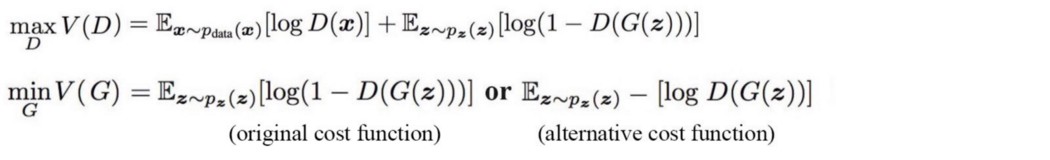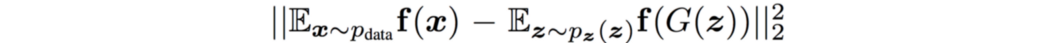|
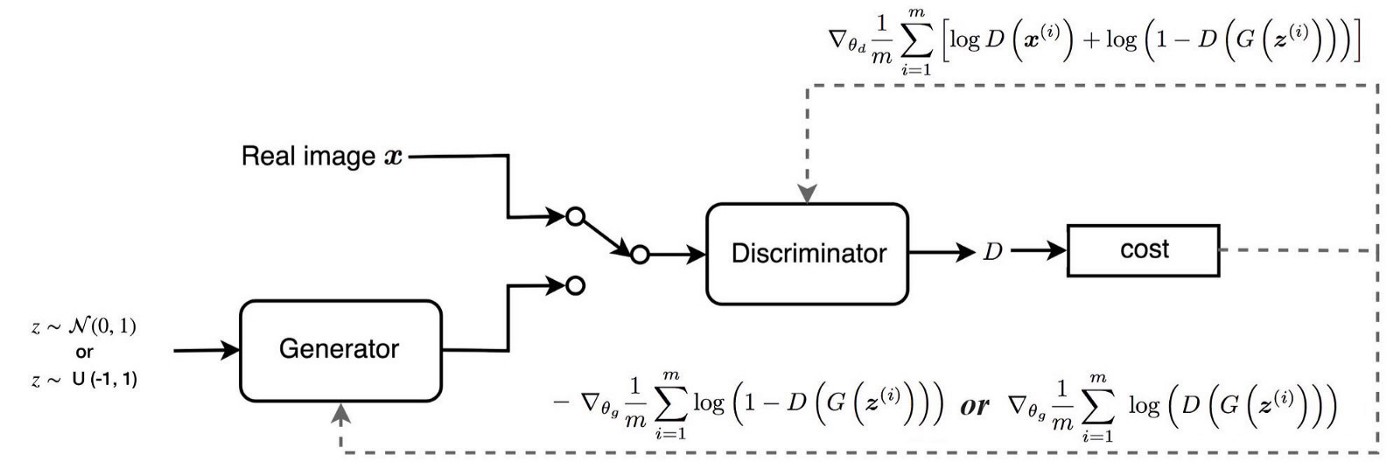
本文主要介绍GAN研究在改进 GAN 方面的动机和方向。 通过在单一上下文中回顾它们,我们了解其思考过程,并使我们对解决方法有自己的判断。 在本文中,我们提供了不同方法的信息以及后续链接。 下图总结了 GAN 的设计。
我们将改进 GAN 训练的方法分为三类:
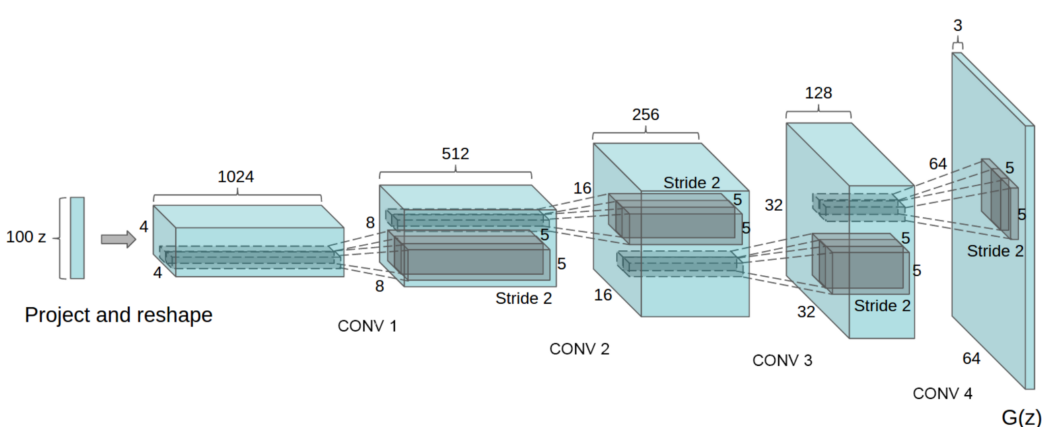
网络设计 GAN最流行的网络设计之一是 DCGAN。
它去掉了破坏空间信息并损害图像质量的max-pooling。 其主要设计包括:
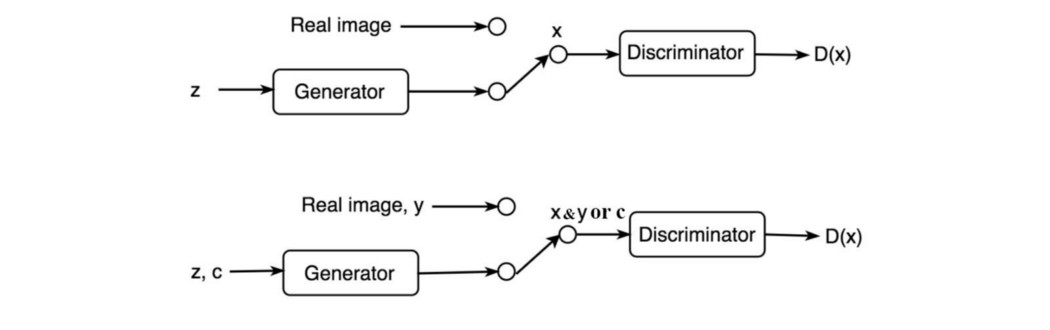
CGAN 我们可以利用任何信息。 Conditional GAN (CGAN) 从样本中获取标签信息,并为生成器提供先机以创建图像。 在第二张图中,生成器和鉴别器都将标签作为输入。 然后标记你的训练样本,它可以创建更好的图像。
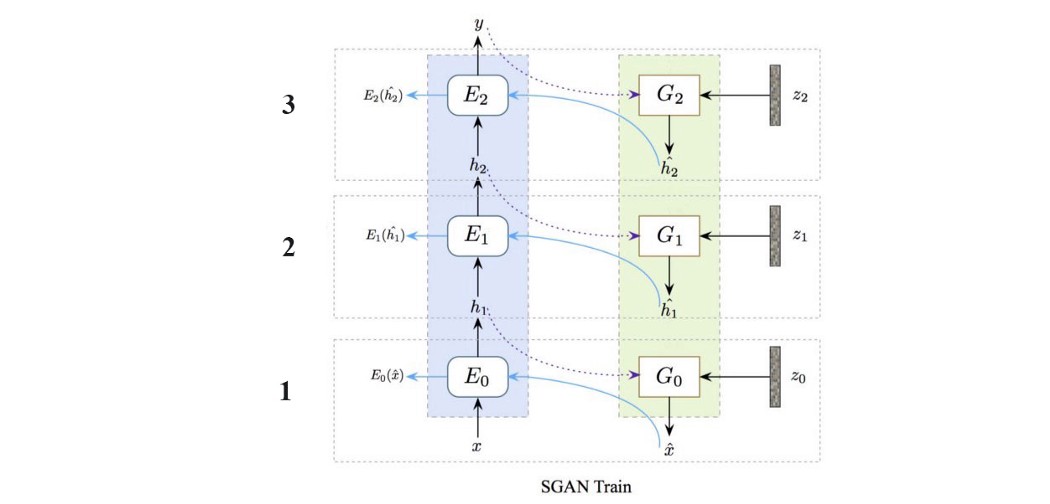
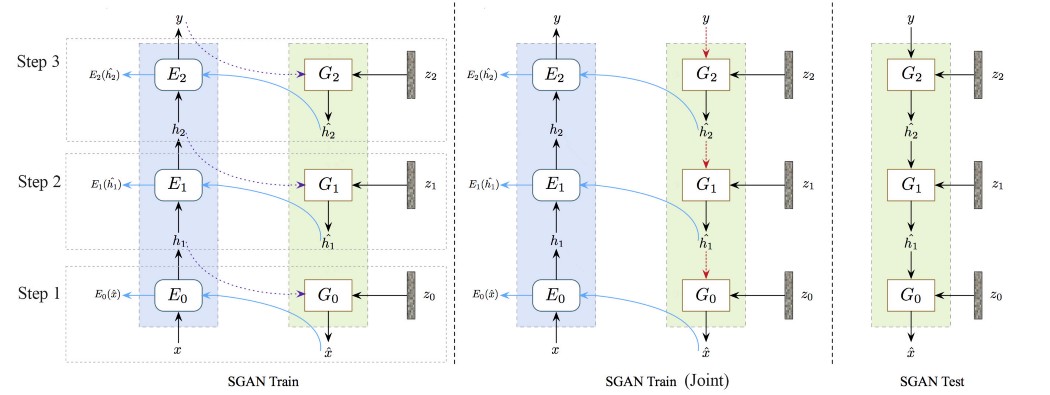
Stacked or progressive GAN 如果你在任何深度网络模型前加上“stack”、“progressive”或“hierarchy”这个词,就保证自己是一篇新的研究论文。 然而,SGAN(Stacked GAN)和progressive GAN 应该有更多的关注。 到目前为止,它们制作了一些最好的图像。 我们可以一次训练一个大模型,也可以将网络分成多个子层,一次训练一个。 对于 GAN,训练很困难,分而治之的方法有效的。 如下所示,网络分为 3 个主要子层,我们在三个不同的阶段从子层 1 到子层 3 进行训练。
在我们分别训练每个主要子层后,然后合并训练整个网络以提高性能(下图中间)。
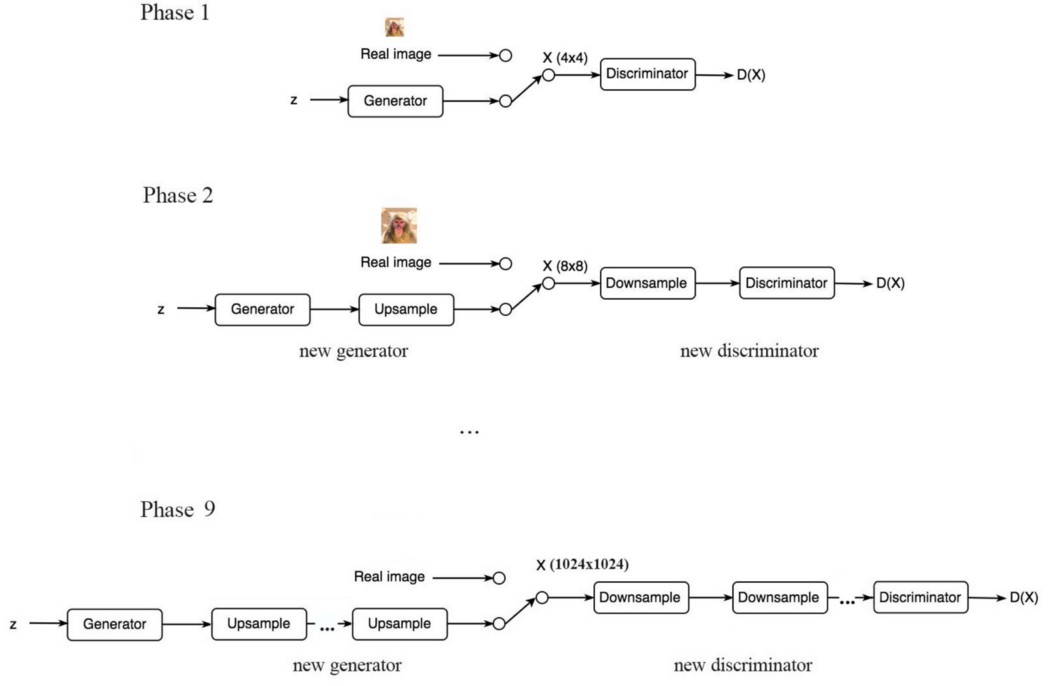
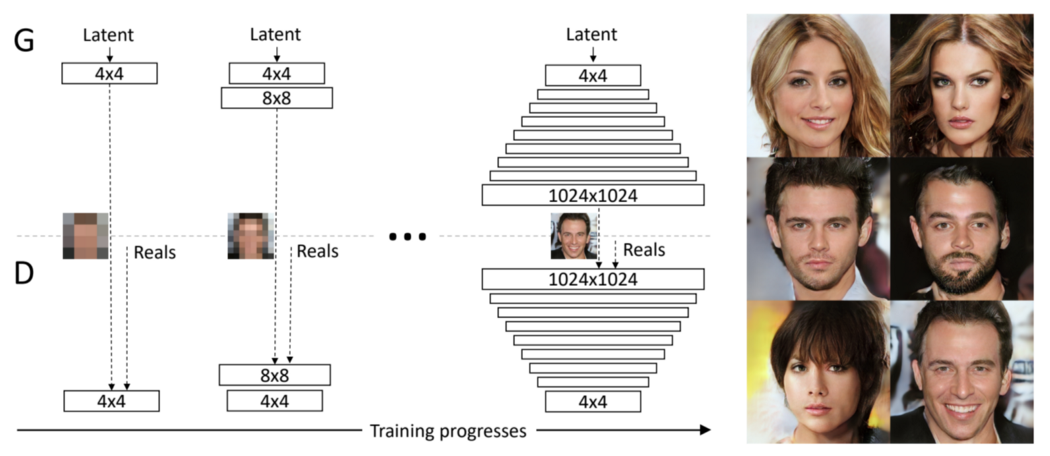
在另一个 GAN 设计中,progressive GAN 在每个子层中将图像上采样或下采样 2。 在第 1 阶段,我们训练生成器生成 4 × 4 的图像。训练完成后,我们添加一个上采样层,将输出分辨率翻倍至 8 × 8。
通过这样做 9 次,我们最终生成了 1024 × 1024 的图像。以下说明我们如何在生成器和鉴别器层中建立分辨率。
对于那些对开发 GAN 应用程序感兴趣的人,值得一看我们系列中的这些文章 SGAN 和progressive GAN。 到目前为止,它产生了最好的图像。 总的来说,基于注意力的深度学习显着提高了准确性。 在自注意力生成对抗网络 (SAGAN) 中,我们定位注意力区域以改进特定区域的渲染。 例如,为了更好地细化眼睛(红点),SAGAN 从注意力区域(中间突出显示的区域)收集信息来细化眼睛。 在 GAN 中,我们经常在创建结构时遇到问题。 例如,狗的腿看起来很奇怪。 基于注意力的 GAN 通过将正确的上下文关联在一起来更好地构建结构。
cost函数 cost函数是 GAN 中研究最多的领域之一。
新的惩罚 在深度学习中,我们向目标函数添加额外成本以强制执行约束。 为了减轻模式崩溃,我们希望在生成的图像中发现的多样性与真实图像的多样性相似。 在 Minibatch 判别中,我们将生成的图像和真实图像分成不同的批次。 对于批次中的每个样本,我们计算其与同一批次中其他样本的相似度,并将此信息提供给鉴别器。 如果生成器中的模式下降,则相似度增加。 鉴别器可以从这个附加参数中发现生成的图像,并相应地惩罚生成器。 避免过度自信 过度自信会造成伤害,尤其是对于任何深度学习训练。 当鉴别器对任何真实图像的预测超过 0.9 时,单边标签平滑会惩罚鉴别器。 新的cost函数和新的目标 鉴别器不想被生成器欺骗。 然而,这个目标可能过于狭窄。 理论上,判别器可以通过检测生成图像缺失的一小组特征来达到 100% 的准确度。 这可能会变成一个贪婪的优化过程,导致模式下降和模型不稳定。 虽然我们希望生成图像的数据分布收敛到真实图像的数据分布,但如何到达那里很重要。 如果梯度消失或不稳定,则训练将失败。 GAN 接下来,我们将讨论一些被大量研究的新cost函数。 但让我们先回顾一下原始 GAN 论文中的cost函数。
在 GAN 中,提出了两个目标函数。 原始cost函数存在梯度消失问题,并提出了替代成本函数。 这表明,即使研究人员可能从一个健全的数学模型开始,他们可能会退回到实证研究和直觉来完善他们的模型。 特征匹配 特征匹配为生成器提出了一个新的cost函数,其目标是生成的图像应该与真实图像的统计数据相匹配。 例如,我们分别计算包含真实图像和生成图像的小批量中特征 f(x) 的均值。 然后我们使用它们的 L2 距离来训练生成器。 这确保生成的图像具有与真实相似的特征。
|