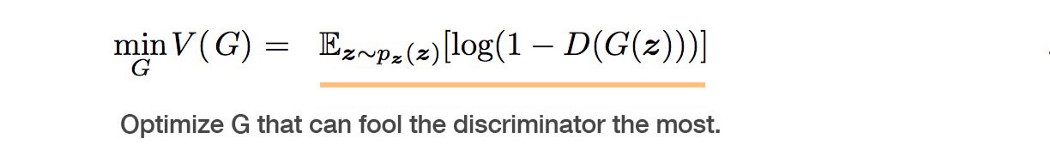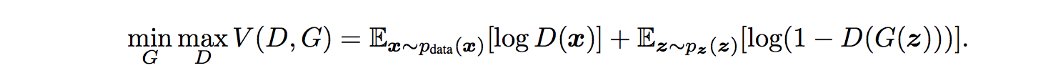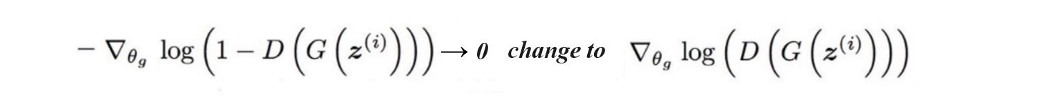|
GAN 是关于创造的,就像画画或创作交音乐一样。 与其他深度学习领域相比,识别画比用计算机或人画一幅画要容易得多,但让计算机理解并画出来这是很难的。 GAN 是做什么的? GAN(生成对抗网络)的主要重点是从头开始生成数据,主要是图像,但包括音乐在内的其他领域也已经完成。 但适用范围远不止于此。 就像下面的例子,它从一匹马生成斑马。 在强化学习中,它可以帮助机器人更快地学习。
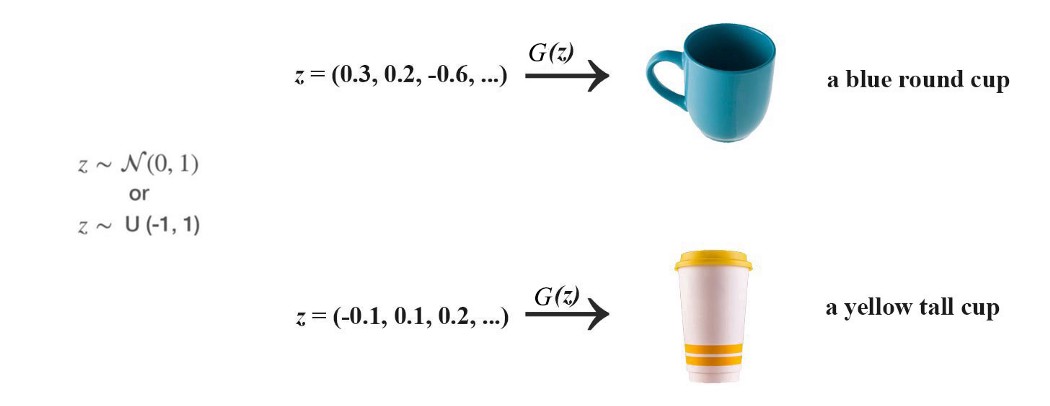
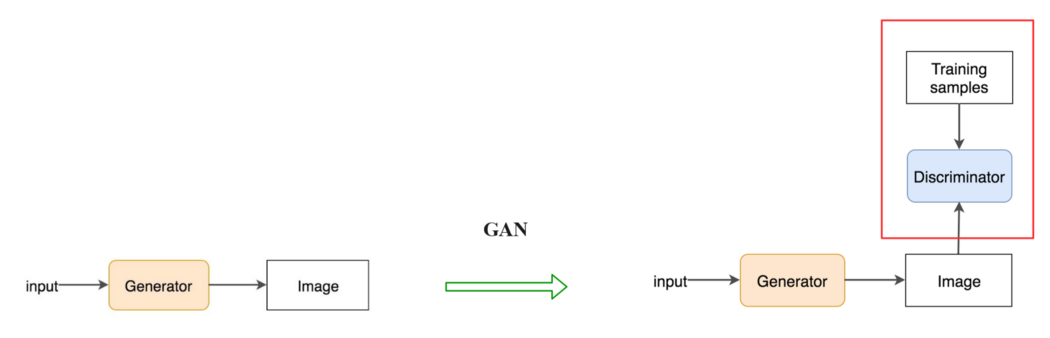
生成器和鉴别器 GAN 由两个深度网络、生成器和鉴别器组成。 在学习如何训练之前,我们将首先知道生成器如何创建图像。 首先,我们使用正态分布或均匀分布对一些噪声 z 进行采样。 以 z 作为输入,我们使用生成器 G 创建图像 x (x=G(z))。
从概念上讲,z 表示生成的图像的潜在特征,例如颜色和形状。 在深度学习分类中,我们不控制模型正在学习的特征。 同样,在 GAN 中,我们不控制 z 的语义。 我们让训练过程来学习它。 即我们不控制 z 中的哪个字节决定头发的颜色。 要发现它的含义,最有效的方法是绘制生成的图像并测试它。 下面的图像是由渐进式 GAN 使用随机噪声 z 生成的!
我们可以逐渐改变 z 中的一个特定维度,并将其语义可视化。
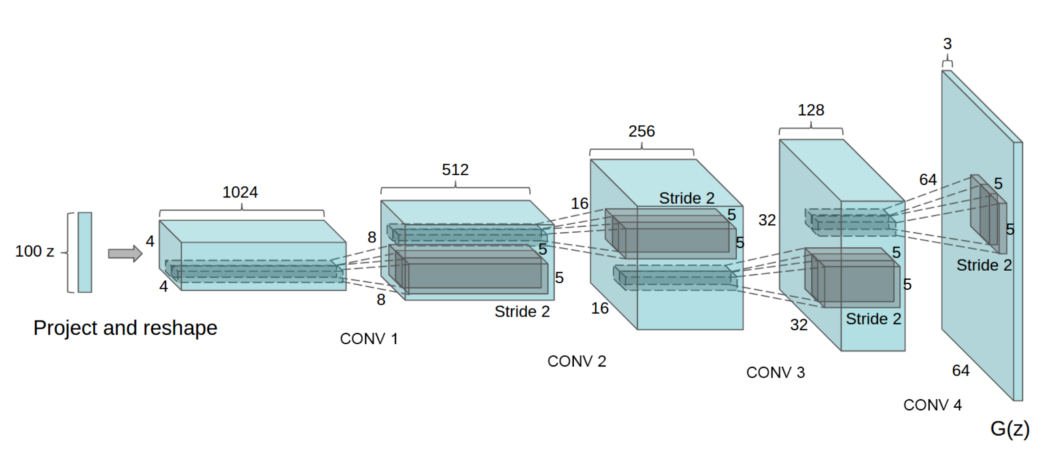
那么这个神奇的generator G是什么? 以下是 DCGAN,它是最流行的生成器网络设计之一。 它执行多个转置卷积以对 z 进行上采样以生成图像 x。 我们可以将其视为反向的深度学习分类器。
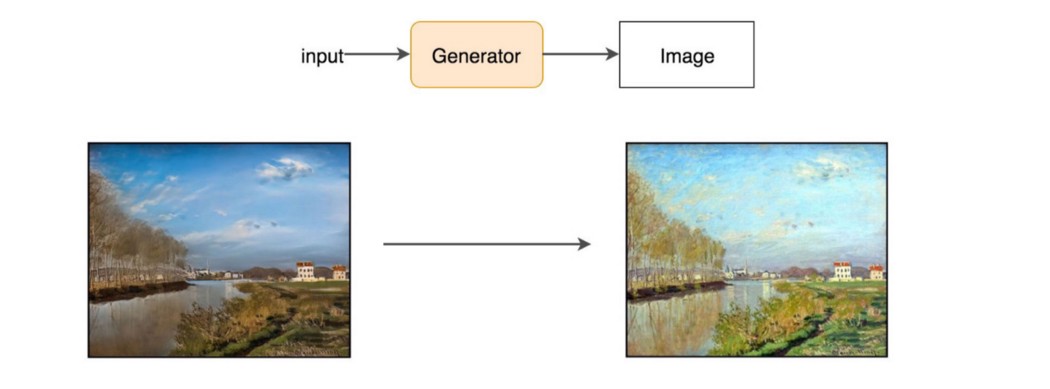
但是单独的生成器只会产生随机噪声。 从概念上讲,GAN 中的鉴别器为生成器提供了创建哪些图像的指导。 让我们考虑 GAN 的应用 CycleGAN,它使用生成器将真实风景转换为莫奈风格的绘画。
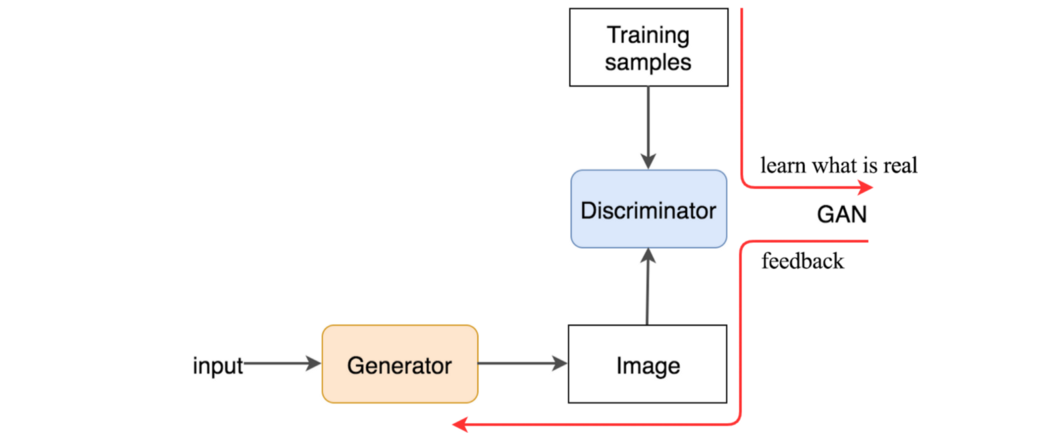
通过使用真实图像和生成图像进行训练,GAN 构建了一个鉴别器来了解哪些特征使图像成为真实。 然后同一个鉴别器将向生成器提供反馈,以创建看起来像真正的莫奈画作的画作。
那么技术上是怎么做的呢? 鉴别器分别查看真实图像(训练样本)和生成的图像。 它区分判别器的输入图像是真实的还是生成的。 输出 D(X) 是输入 x 是真实的概率,即 P(输入类别 = 真实图像)。
我们像深度网络分类器一样训练鉴别器。 如果输入是实数,我们希望 D(x)=1。 如果它被生成,它应该为零。 通过这个过程,鉴别器识别出对真实图像有贡献的特征。 另一方面,我们希望生成器创建 D(x) = 1 的图像(匹配真实图像)。 所以我们可以通过将这个目标值一直反向传播到生成器来训练生成器,即我们训练生成器来创建图像,以识别鉴别器认为它是真实的。
我们以交替的步骤训练这两个网络,并将它们锁定在激烈的竞争中以提高自己。 最终,鉴别器识别出真实和生成之间的微小差异,生成器创建鉴别器无法区分的图像。 GAN 模型最终收敛并生成外观更自然的图像。 这个鉴别器概念也可以应用于许多现有的深度学习应用程序。 GAN 中的鉴别器充当评论家。 我们可以将鉴别器插入现有的深度学习解决方案中,以提供反馈以使其更好。
反向传播 现在,我们将通过一些简单的等式。 鉴别器输出一个值 D(x),指示 x 是真实图像的机会。 我们的目标是最大限度地将真实图像识别为真实图像并将生成的图像识别为假图像的机会。 即观察到的数据的最大似然。 为了测量损失,我们像在大多数深度学习中一样使用交叉熵:p log(q)。 对于真实图像,p(真实图像的真实标签)等于 1。对于生成的图像,我们反转标签(即一个减标签)。 所以目标变成了: 在生成器方面,它的目标函数希望模型生成具有尽可能高的 D(x) 值的图像来欺骗鉴别器。
我们经常将 GAN 定义为一个极大极小博弈,G 想要最小化 V 而 D 想要最大化它。
一旦定义了两个目标函数,就可以通过交替梯度下降来联合学习它们。 我们修复生成器模型的参数,并使用真实图像和生成图像对判别器执行梯度下降的单次迭代。 然后我们换边。 修复鉴别器并训练生成器进行另一次迭代。 我们以交替的步骤训练两个网络,直到生成器产生高质量的图像。 下面总结了用于反向传播的数据流和梯度。
下面的伪代码将所有内容放在一起,并展示了 GAN 是如何训练的。
生成器梯度递减 然而,我们遇到了生成器的梯度递减问题。 鉴别器通常会较早地战胜生成器。 在早期训练中,将生成的图像与真实图像区分开来总是更容易。 这使得 V 接近 0。即 - log(1 -D(G(z))) → 0。生成器的梯度也将消失,这使得梯度下降优化非常缓慢。 为了改进这一点,GAN 提供了一个替代函数来将梯度反向传播到生成器。
总的来说,生成数据的概念让我们有很大的潜力,但也很危险。 除了 GAN 之外,还有很多其他的生成模型。 例如,OpenAI 的 GPT-2 生成的段落可能看起来像记者所写的内容。 事实上,OpenAI 决定不放开他们的数据集和训练模型,因为它可能被误用。 |