|
重建图像的Mask部分如何有益 自编码器在自然语言处理任务中有着成功的历史。 BERT 模型开始在句子的不同部分屏蔽单词,并尝试通过预测要填充到空格中的单词来重建完整的句子。 最近的工作旨在将这一想法转移到计算机视觉领域。 在最近论文中,我们将看看 He 等人最近发表的论文“Masked Autoencoders Are Scalable Vision Learners”。 从 2021 年开始,何凯明是计算机视觉领域最有影响力的研究人员之一,与 Meta AI Research 的其他研究人员一起取得了 ResNet、Faster R-CNN 和 Mask R-CNN 等突破。 在他们最新的论文中,他们提出了一种使用自动编码器进行计算机视觉模型(特别是视觉transformers)自我监督预训练的新方法。
在我们深入研究他们提出的方法之前,重要的是我们快速回顾自我监督的预训练以设置正确的上下文。 如果你已经熟悉自监督预训练,可以跳过这部分。 先决条件:计算机视觉的自我监督预训练 在我们深入研究论文之前,有必要快速回顾一下自监督预训练的全部内容。 如果你熟悉自监督预训练,可以跳过这部分。 传统上,计算机视觉模型一直使用监督学习进行训练。 这意味着人类查看图像并为它们创建各种标签,以便模型可以学习这些标签的模式。 例如,人工注释者会将类标签分配给图像或在图像中的对象周围绘制边界框。 但任何接触过标注任务的人都知道,创建足够的训练数据集的工作量很大。 相比之下,自监督学习不需要任何人工创建的标签。 顾名思义,模型学习自我监督。 在计算机视觉中,对这种自我监督进行建模的最常见方法是对图像进行不同的裁剪或对其应用不同的增强,并将修改后的输入传递给模型。 即使图像包含相同的视觉信息但看起来并不相同,我们让模型学习到这些图像仍然包含相同的视觉信息,即相同的对象。 这导致模型为相同的对象学习类似的潜在表示(输出向量)。 我们稍后可以在这个预训练模型上应用迁移学习。 通常,这些模型随后会在 10% 的带有标签的数据上进行训练,以执行下游任务,例如对象检测和语义分割。 使用掩码让自动编码器理解视觉世界 本文的一个关键新颖之处已经包含在标题中:图像的掩蔽。 在将图像输入编码器transformer之前,会对其应用一组特定的掩码。 这里的想法是从图像中删除像素,从而为模型提供不完整的图片。 该模型的任务是了解完整的原始图像是什么样的。
在左侧,可以看到mask图像。 在右侧,显示原始图像。 中间一列显示了自动编码器重建的图像。 作者发现非常高的掩蔽率是最有效的。 在这些示例中,他们用蒙版覆盖了 75% 的图像。 这带来了两个好处:
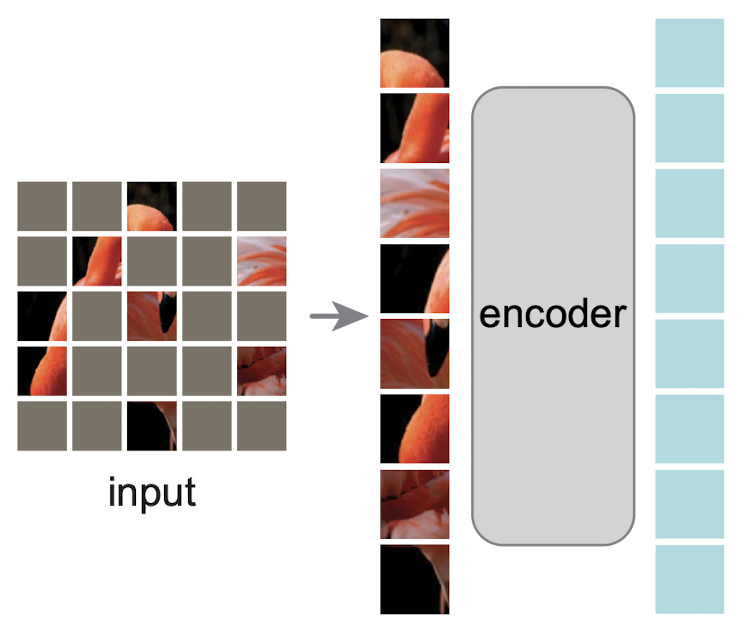
掩码总是随机应用,因此可以将同一图像的多个版本用作输入。 现在图像已经过预处理,让我们看一下模型架构。 在他们的论文中,He 等人。 决定使用非对称编码器设计。 这意味着他们的编码器可以更深,而他们选择了一个相当轻量级的解码器。 编码器将图像划分为分配了位置编码(即上面图像中的正方形)的块,并且仅处理图像的非屏蔽部分。 编码器的输出是输入图像块的潜在向量表示。
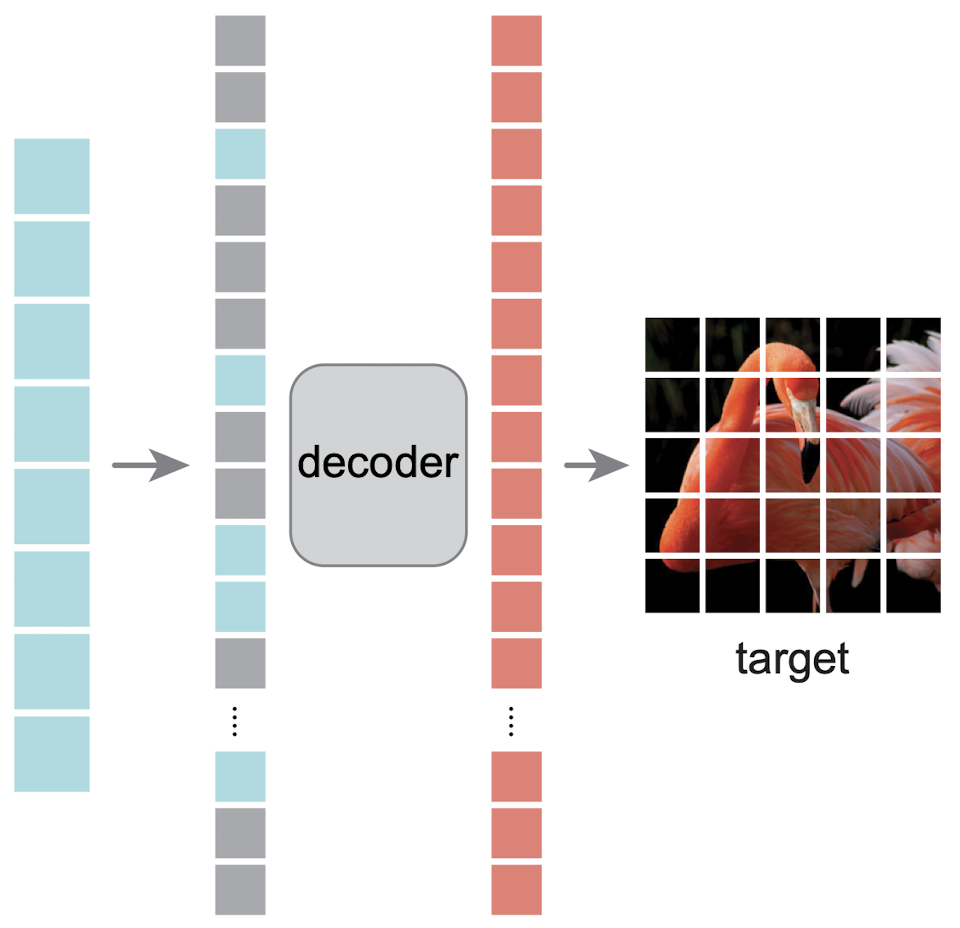
编码器接收非mask图像块并输出潜在向量表示的可视化 在此之后,引入了掩码标记,因为下一步是解码器重建初始图像。 每个掩码标记都是一个共享的学习向量,指示缺失补丁的存在。 位置编码再次应用于与解码器通信,其中各个补丁位于原始图像中。 解码器接收潜在表示以及掩码标记作为输入,并输出每个补丁的像素值,包括掩码。 根据这些信息,可以将原始图像拼凑在一起,从用作输入的mask图像中形成完整图像的预测版本。
从掩码输入图像的潜在表示到重建目标图像的解码过程 在计算蓝色的潜在向量之后添加掩码标记是一个重要的设计决策。 它降低了编码器到达向量输出的计算成本,因为它必须处理更少的补丁。 这使得模型在训练期间更快。 一旦目标图像被重建,它与原始输入图像的差异被测量并用作损失。
重建图像与原始图像的比较 模型训练好后,解码器被丢弃,只有编码器,即视觉transformer,被保留以供进一步使用。 它现在能够计算图像的潜在表示以进行进一步处理。 现在我们已经了解了论文介绍的方法,让我们看一些结果。 结果 由于掩码自动编码器使用transformer,因此作者将其性能与其他基于transformer的自监督方法进行比较是有意义的。 他们在第一次比较中的改进显示:
在与其他方法的比较中,当在 ImageNet-1K 上预训练模型然后对其进行端到端的微调时,MAE(掩码自动编码器)与其他方法(如 DINO、MoCov3 或 BEiT)相比表现出优越的性能。 即使模型尺寸增加,改进也保持稳定,ViT-H(Vision Transformer Huge)的性能是最好的。 MAE 达到了令人难以置信的 87.8 精度。 这种性能也适用于下游任务的迁移学习:
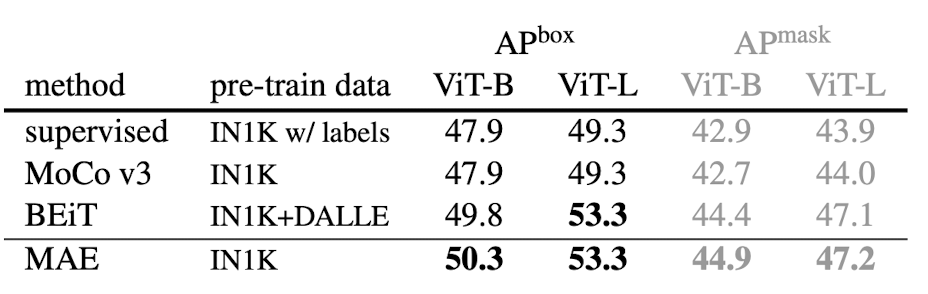
迁移学习应用于不同的基于 Transformer 的预训练方法。 这些结果是针对 COCO 检测和分割数据集的 当使用预训练的transformer作为在 MS COCO 检测和分割数据集上训练的 Mask R-CNN 的主干时,MAE 再次优于所有其他基于transformer的方法。 它为box实现了令人难以置信的 53.3 AP(平均精度)。 Mask R-CNN 还输出对象的分割掩码。 对于本次评估,MAE 再次以高达 47.2 AP 的掩码高于所有其他方法。 该方法甚至优于 Mask R-CNN 的全监督训练,再次显示了自监督预训练的好处。 Wrapping it up 在本文中,您了解了掩码自动编码器 (MAE),这是一篇利用transformer和自动编码器进行自监督预训练的论文,并为自监督预训练工具箱添加了另一个简单但有效的概念。它甚至在某些任务上优于完全监督的方法。这篇文章能让你对这篇论文有一个很好的初步了解,但还有很多东西要发现。因此,希望你自己阅读下这篇论文,即使你是该领域的新手。你必须从某个地方开始 ; |