|
Keras API 可以使用内置的优化器和损失函数轻松执行反向传播。 但是,在某些情况下,我们想要专门操作或应用渐变。 例如,为了避免爆炸性梯度,我们可能想要裁剪梯度。
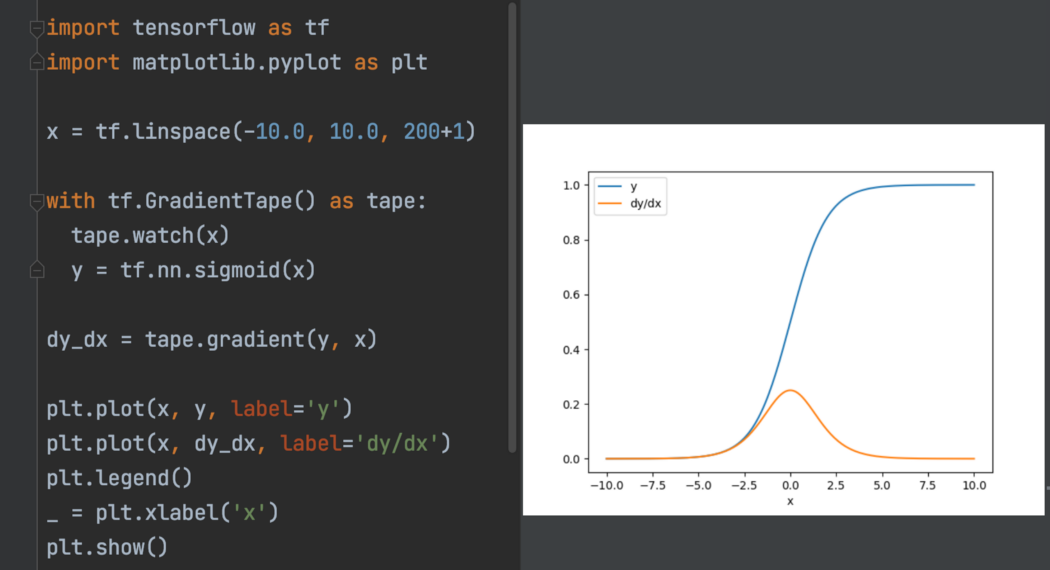
一般来说,TensorFlow AutoDiff 允许我们计算和操作梯度。 在下面的示例中,我们计算并绘制了 sigmoid 函数的导数。 在深度学习中,我们使用 AutoDiff 来执行自定义反向传播。
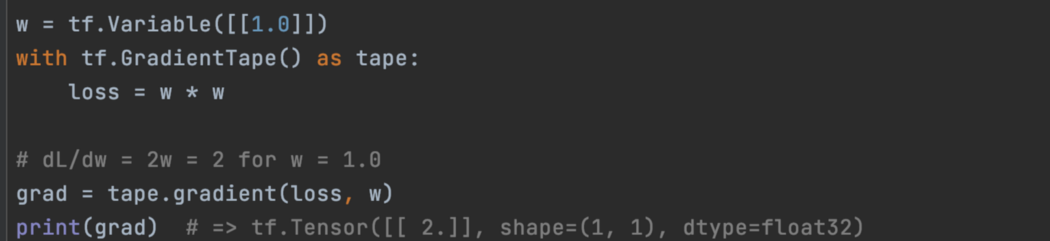
GradientTape 记录前向传播 在 TensorFlow (TF) 中,tf.GradientTape 将其“with”块内的所有前向传递操作记录到“tape”中。 稍后将使用此记录计算 tape.gradient 中的反向传播梯度。 下面的代码记录了操作损失 = w²。 然后,tape.gradient(loss, w) 计算损失梯度 w.r.t。 w(即 dL/dw)。
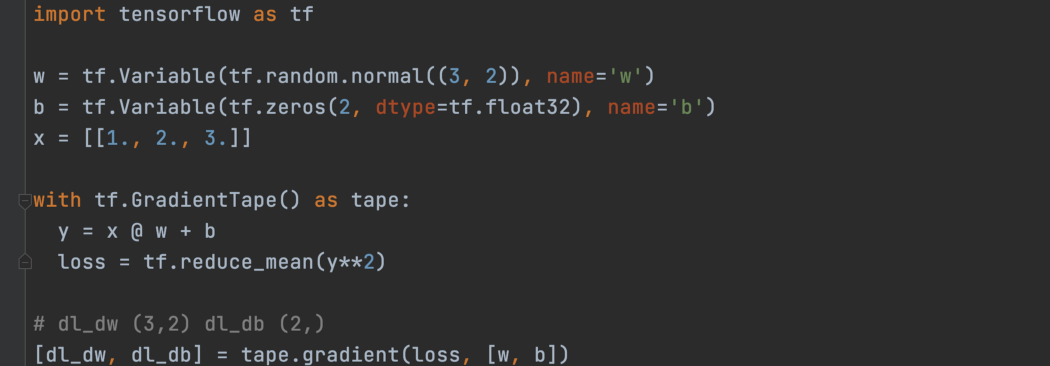
这是一个dense层的示例,其中输入 x 是向量而不是标量。 w (dl_dw) 的返回梯度是一个形状为 (3, 2) 的张量。 它具有与 w 相同的形状,因为它包含 w 中每个元素的一个渐变。
为了将梯度下降应用于神经网络,我们根据学习率和梯度改变其权重。
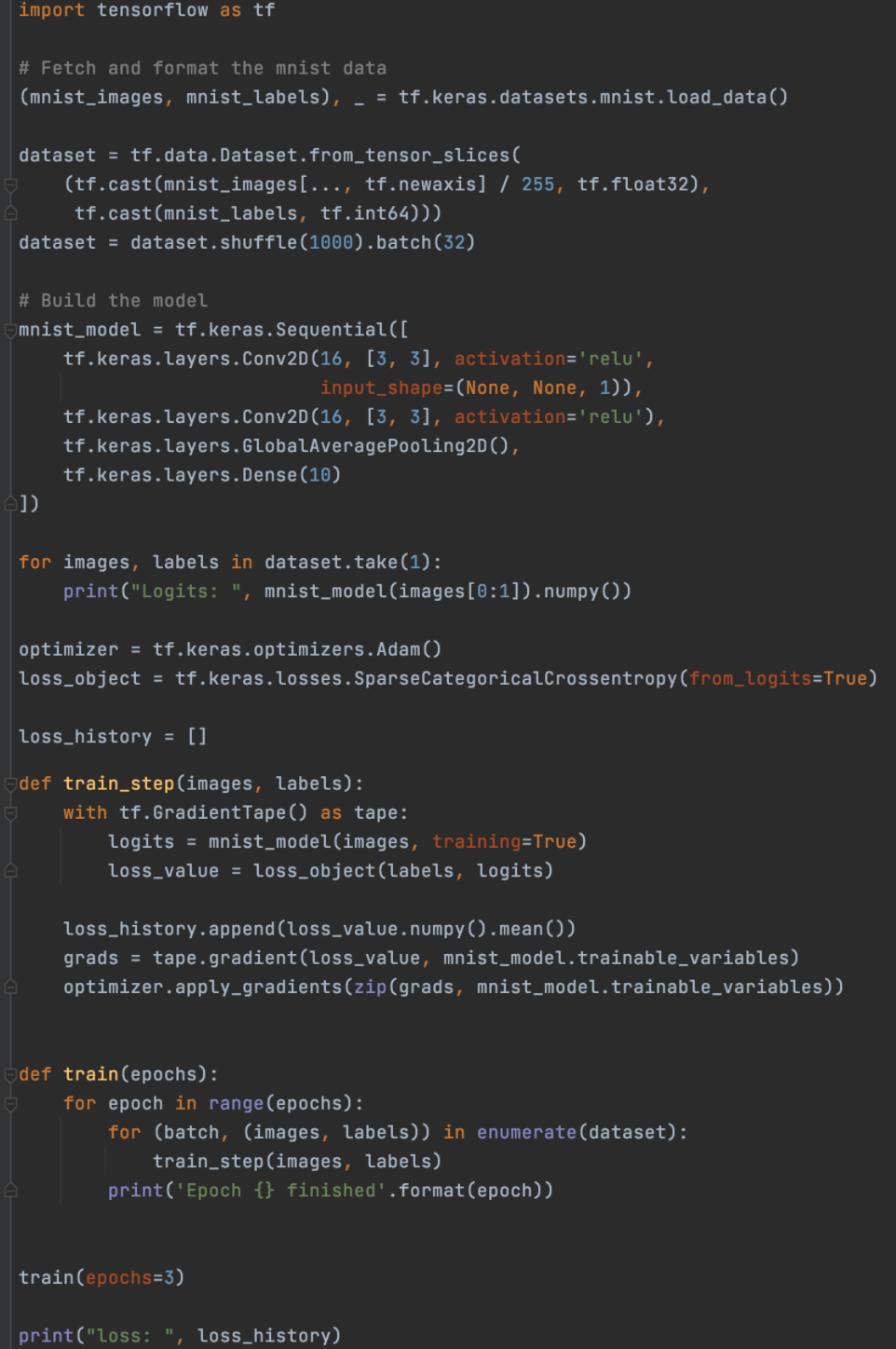
神经网络模型的 AutoDiff 让我们用下面的 MNIST 分类器完成我们的演示。 Keras 模型提供属性 mnist_model.trainable_variables,这样我们就不需要自己跟踪所有可训练变量。
tape.gradient 返回一个列表(grads),其中包含每个可训练变量的梯度张量。 然后我们可以根据我们选择的优化器应用梯度下降。
为了完整起见,这里是完整的代码。
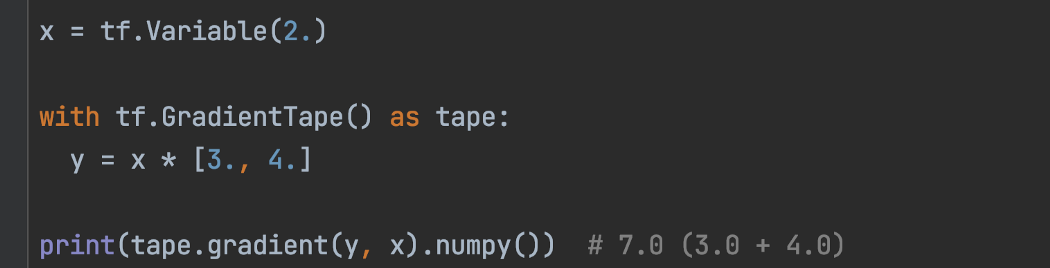
注意:我对代码使用屏幕截图,因为它们的格式更好。 想要源代码的读者,请参考TensorFlow指南,这里大部分代码都出自这里。 随着 TF API 的不断变化,本文中的代码很难保持最新。 读者应始终参考最新的文件。 Vector Output 前面显示的计算出的 y(比如损失函数)是一个标量值。 但 y 可以是向量。 例如, y = x*[3., 4.] 是一个向量。 y 有 2 个分量,dy/dx = [3., 4.]。 但是,tape.gradient 总是返回形状与 x 相同的渐变。 实际上,tape.gradient 在这里返回等于 7 的分量之和。
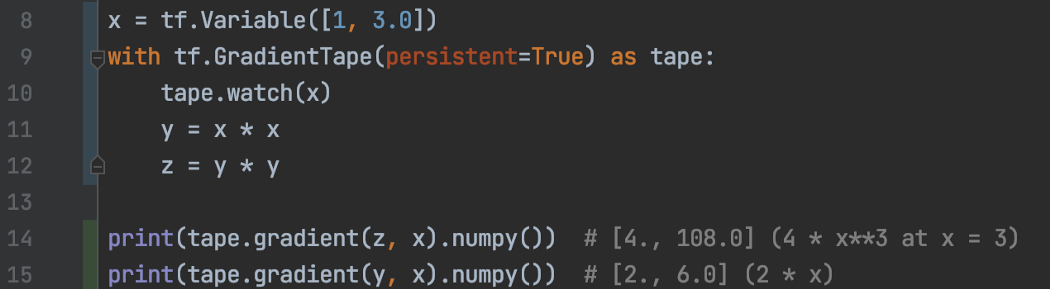
Persistent 调用tape.gradient时释放tape持有的资源。 对于不同变量的导数,我们不能多次调用同一个tape。 要允许多次调用,请确保该tape的持久性为 True。 以后不需要的时候使用del tape释放资源。
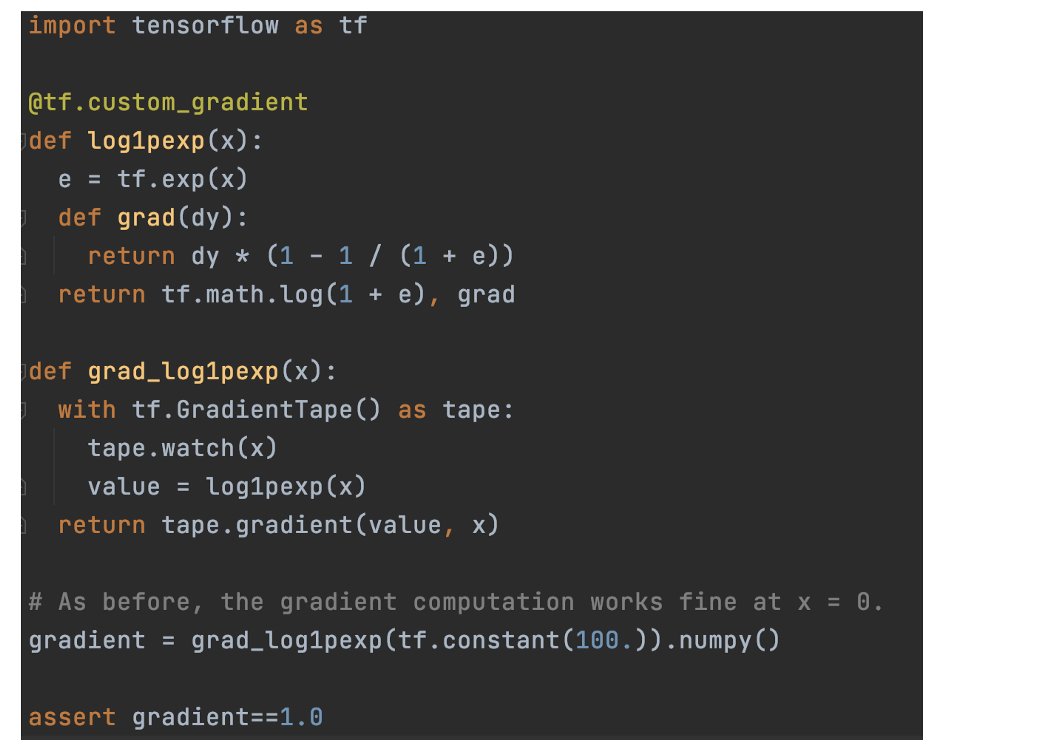
自定义Gradient Tensorflow 自动提供自动梯度计算。 然而,一些梯度计算是不可计算的或数值不稳定的。 对于后一种情况,中间结果可能接近无穷大,即使它最终可能会被抵消。 例如,下面计算的梯度在 x = 100 时返回 NAN(不是数字),即使实际梯度为 1.0。
为了解决这个问题,我们可以添加一个@tf.custom_gradient 注释并实现更稳定和自定义的梯度计算。 这种新方法返回损失函数和自定义梯度函数。 但是这个带注释的方法只会将损失返回给调用者并记录自定义函数来计算tape.gradient中的梯度。 如下所示,log (1 + eˣ) 的梯度被实现为 1–1/(1+eˣ),对于 x = 100 等于 1。
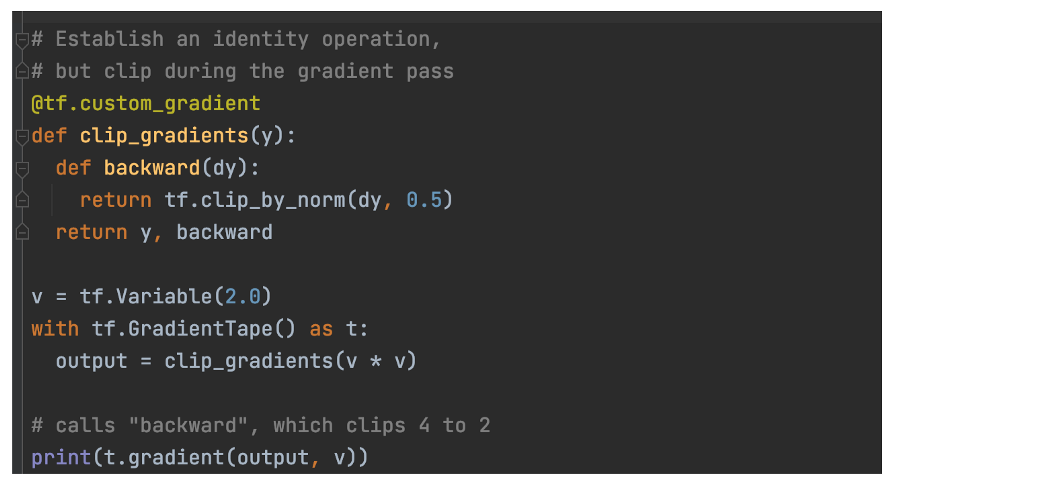
按Norm进行梯度剪裁 显式操作梯度的一个主要应用是按范数裁剪梯度以避免梯度爆炸。 这是演示该想法的示例代码。
获得NAN的梯度 在某些情况下,返回的梯度将为NAN。 在本节中,我们将了解如果这不正确的原因或如何修复它。 不可训练的变量、张量、常数 tf.GradientTape 记录“with”块中的操作并跟踪这些操作涉及的所有可训练的 tf.Variable。 但是,无法自动跟踪不可训练的变量、张量和常量。 它们是下面的 x1(不可训练的 tf.Variables)、x2(张量)和 x3(tf.constant)。 它们相应的计算梯度为NAN。
watch 如果这不是可取的,我们可以通过使用 tape.watch 显式添加它们来修复它。 在下面的例子中,在观察输入 x 之后,我们可以正确计算它的梯度。
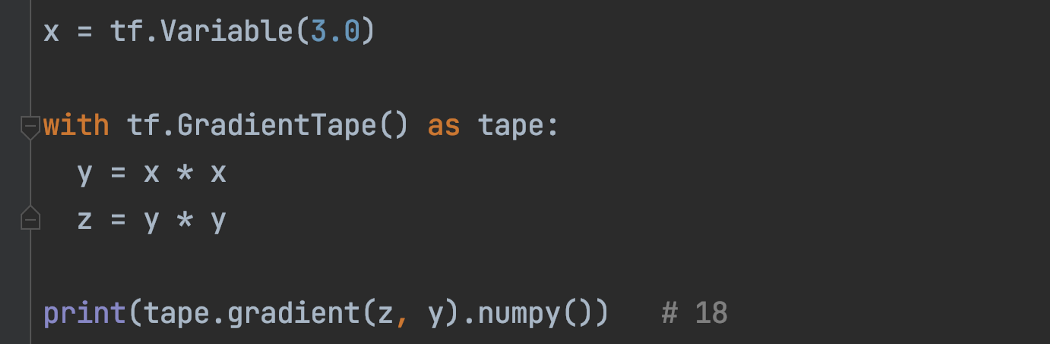
顺便说一句,GradientTape 块中的中间结果(如下面的 y)将被自动记录,即使它是一个张量。 梯度 dz/dy 在下面返回 18。
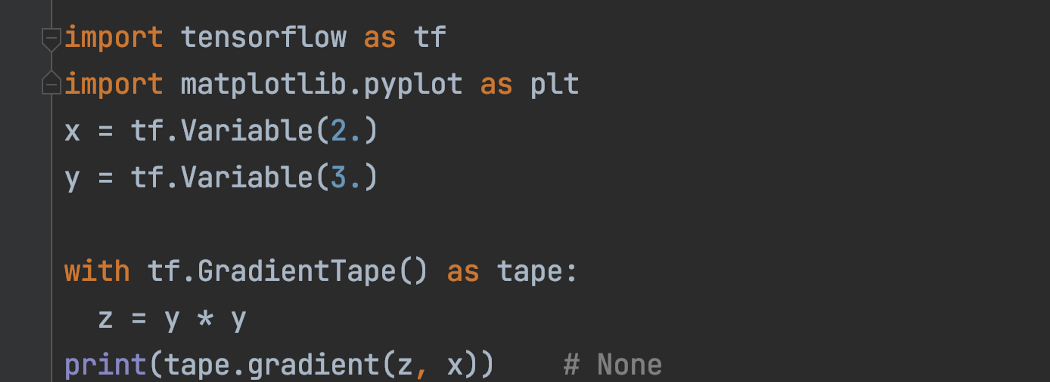
None 正如预期的那样,当梯度是不相关的变量时,tape.gradient 返回 None 。 在下面的代码中,z 与 x 无关,因此返回的梯度为 None。
无法跟踪在 TensorFlow 之外执行的操作,例如 NumPy 操作。 所以无法计算下面用 Numpy 计算的 y 的梯度。 并且操作涉及整数或字符串数据类型是不可区分的。 例如,整数到浮点数的转换是不可微的,相应的梯度是None。
赋值 x = x +1 将 x 转换为张量。 所以当我们开始第二个 epoch 和一个新的录音会话时,x 不会被自动点击。 因此,对于第二个 epoch,梯度 w.r.t. x 是None。
当 TF 从像 tf.Variable 这样的有状态对象读取时,磁带只能看到当前状态,而不是导致它的历史记录。 改变变量状态的操作将阻止梯度传播。 因此,左侧的 assign_add 操作将导致梯度计算为 None。 (似乎赋值记录了更改的状态,但没有记录操作。)为了解决这个问题,我们将变量加在一起并将结果分配给张量。 这显示在右下方。
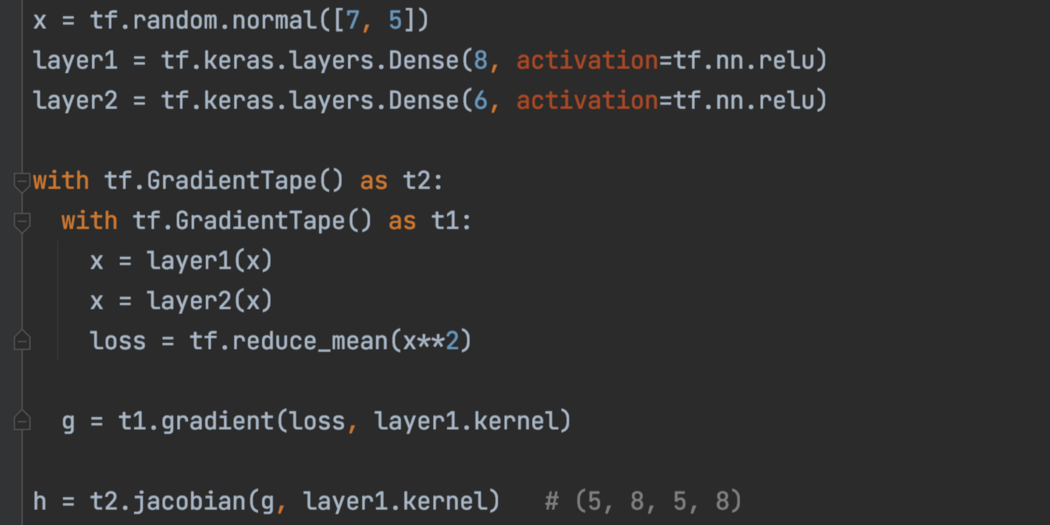
高阶梯度 tap.gradient 可以看作是另一个 TensorFlow 算子。 因此,我们可以使用嵌套的 GradientTape 来计算高阶梯度。 在下面的内部“with”循环中,我们计算一阶导数,而另一个循环跟踪 dy/dx 并计算其导数,即 y w.r.t 的二阶导数。 X。
Jacobian & Hessian TensorFlow 还提供 API 来计算雅可比矩阵 J。
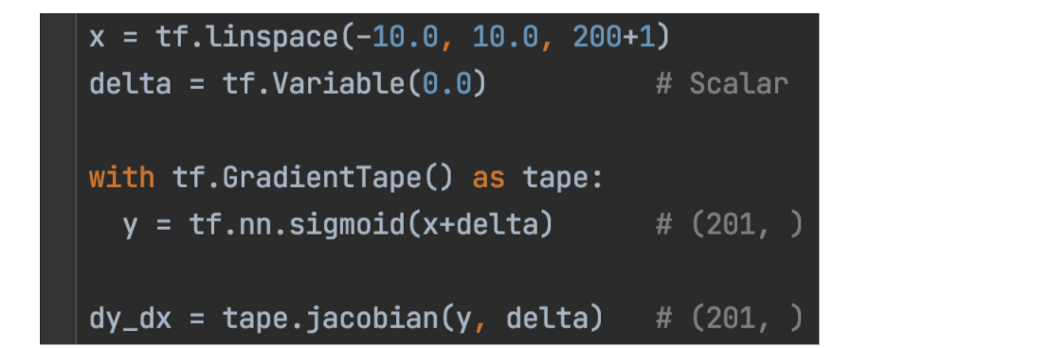
下面的代码计算雅可比 w.r.t。 为一个标量变量。
这个计算Hessian。
|