|
Keras 有 3 个内置的 RNN 层:SimpleRNN、LSTM 和 GRU。 LSTM 从 1000 的词汇量开始,一个词可以用 0 到 999 之间的词索引来表示。例如,单词“side”可以编码为整数 3。
在下面的代码示例中,嵌入层的输入是表示文本的单词索引序列。 该层将文本转换为一系列 64 维向量——每个单词一个向量。
接下来,LSTM 层将此向量序列转换为 128 维向量。 最后,使用密集层将其转换为 10 维向量。 它对每个类进行一个分类预测。
这是模型的摘要。
作为参考,下面的圆角矩形是一个 LSTM 单元。 在上面的代码示例中,LSTM 返回最后一个timestep的隐藏状态(一个 128 维向量)作为输出。
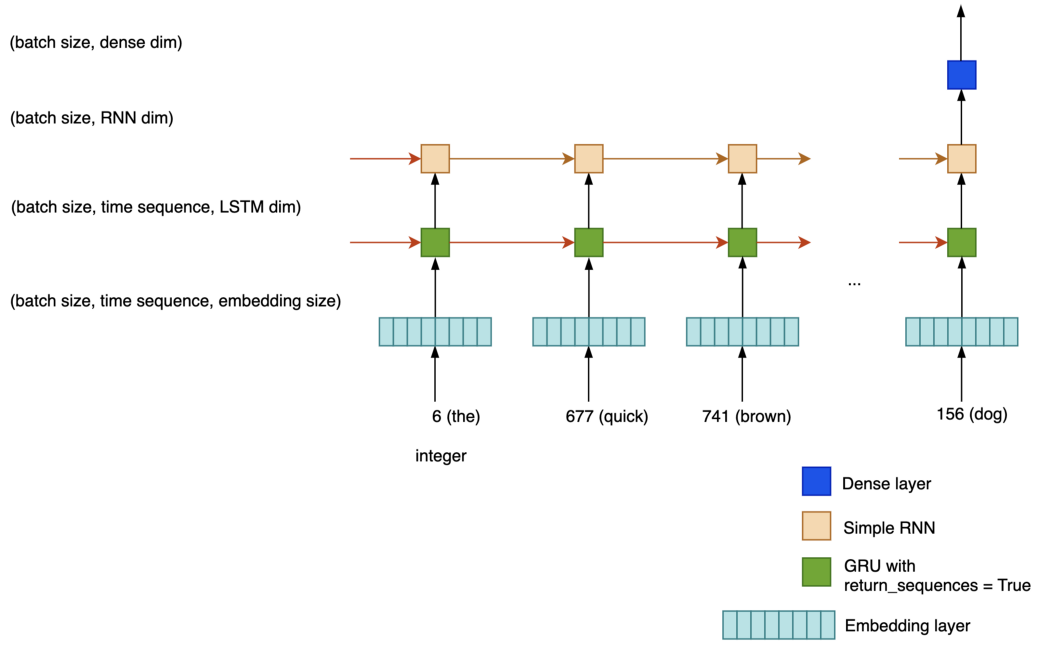
GRU 让我们用 GRU 替换 LSTM 模块,并将 return_sequences 设置为 True,它返回每个时间步的所有隐藏状态,而不是最后一个。 在下图中,GRU 的每个隐藏状态都被输入到 SimpleRNN 层的相应输入中。 我们采用 SimpleRNN 的最后一个隐藏起点,然后将其输入密集层进行分类。
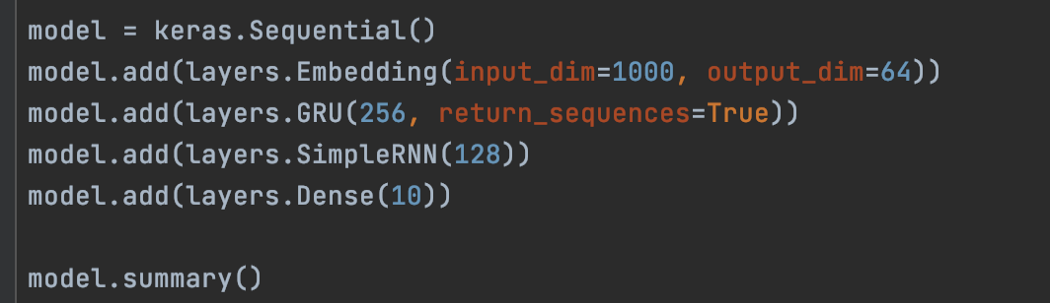
下面是对应的代码:
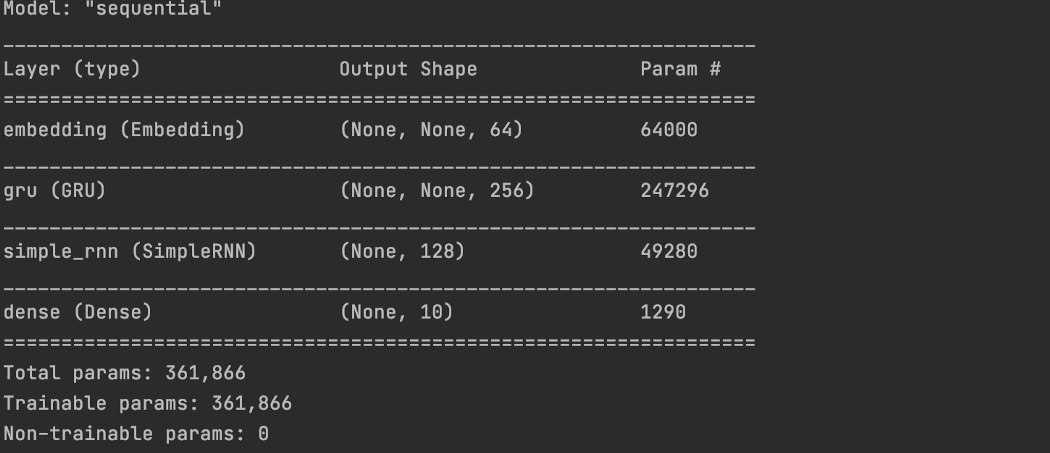
和模型摘要。
return_sequences 如前所示,我们将 GRU 层的 return_sequences 设置为 True 以返回所有隐藏状态。 事实上,LSTM 和 SimpleRNN 也支持这个参数。
return_state 通过将 return_state 设置为 True,LSTM/GRU/SimpleRNN 层会返回输出以及最后一个时间步的隐藏状态。 对于 LSTM,它还返回最后一个时间步的单元状态。 在下面的示例中,“输出”与最后一个隐藏状态 state_h 具有相同的值。 这是多余的。 但是如果 return_sequences 等于 True,“输出”包含所有隐藏状态,而不仅仅是最后一个时间步的 state_h。
initial_state initial_state 张量是第一个时间步的输入隐藏状态和单元状态。 默认情况下,LSTM 和 GRU 中的初始状态张量是零填充的。 但是在编码器-解码器架构中,我们可以使用编码器的最后一个隐藏状态和单元状态(state_h 和 state_c)来初始化解码器。
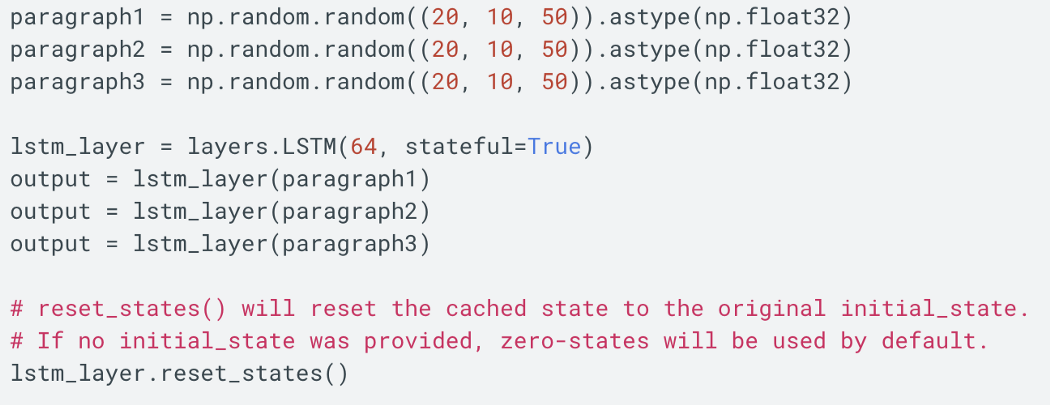
Cross-batch statefulness 默认情况下,每批样本都会重置 RNN 单元的初始状态。 但是,在某些情况下,我们希望保持batch之间的状态。 例如,在元学习中,我们不断地从以前的经验中学习,我们不想重置经验。 在其他情况下,输入序列可能太长,因此,我们可能会在训练期间将其分解为子序列。 在这种情况下,我们不会重置子序列之间的状态。 为了保持样本之间的细胞状态,我们设置 stateful=True。 要重置,我们调用 lstm_layer.reset_states。
这是一个示例,其中我们将 3 个段落视为单个样本。 我们将单元状态保留在进程中,并仅在完成后将其重置。
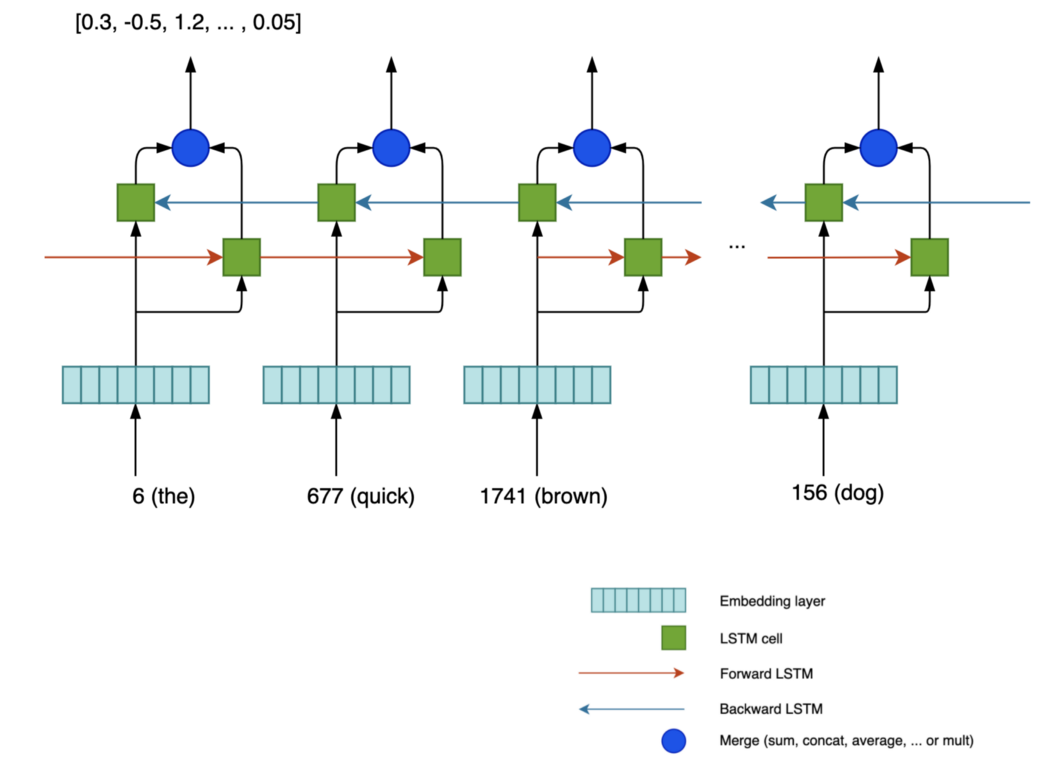
双向 RNN 下图显示了一个双向 RNN,其中包含一个前向 LSTM 和一个后向 LSTM。 对于每个时间步,我们将前向传播和后向传播的结果合并在一起以生成输出。 关于合并的完成方式有不同的选择,例如连接、加法、乘法等……
这是使用双向层构建分类器的代码。
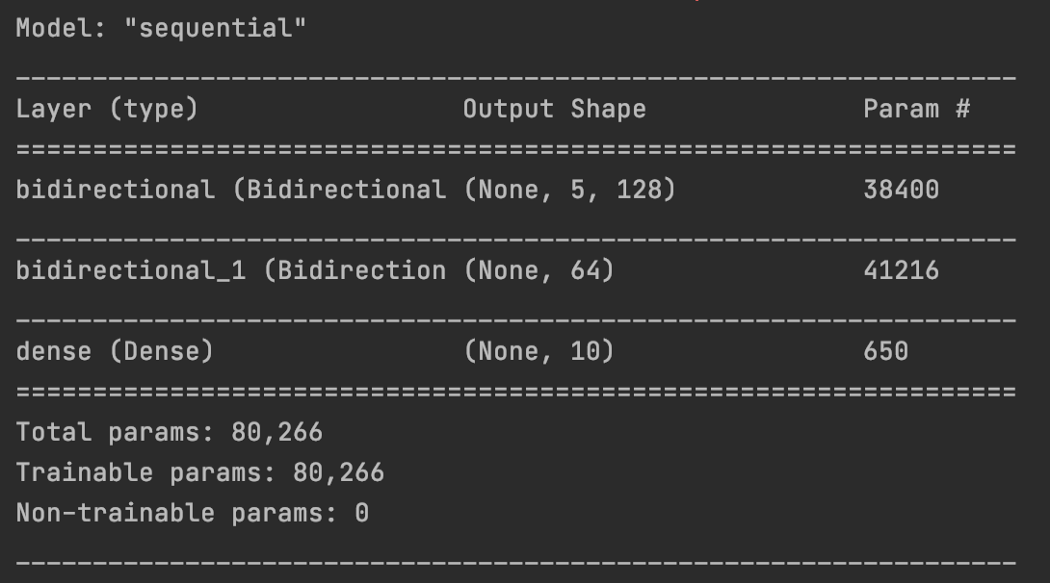
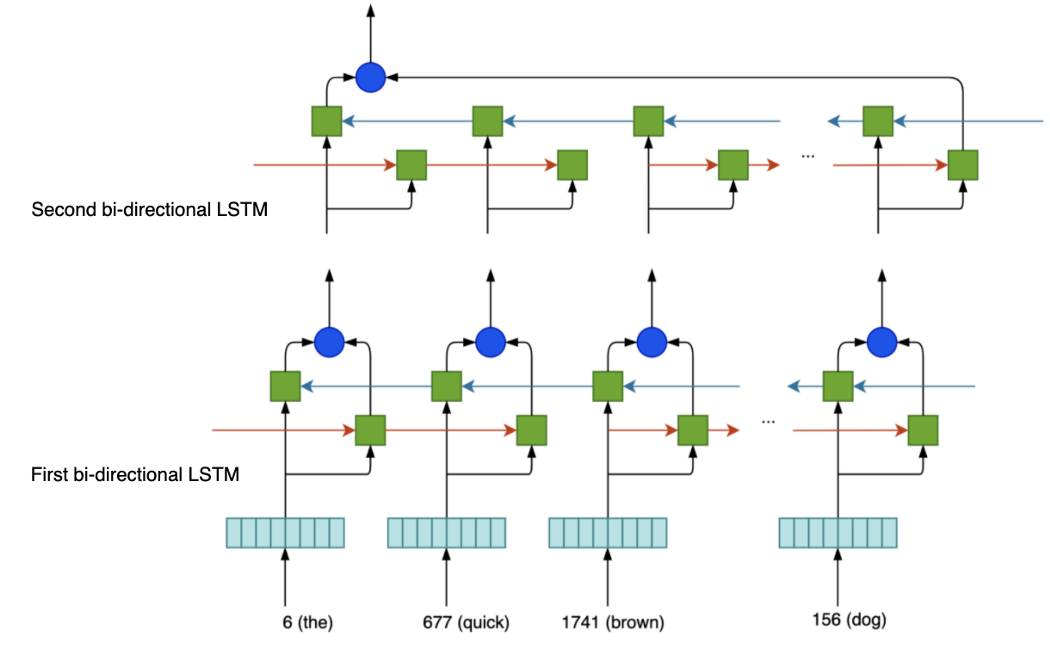
第一个双向 LSTM 的输入形状为 (None, 5, 10)。 当 return_sequences=True 时,它输出 5 个隐藏状态。 默认情况下,双向 LSTM 将前向和后向传播结果连接在一起(merge_mode='concat')。 因此,第一层的输出是 (None, 5, 128),它是前向 LSTM 层输出维度的两倍。
对于第二个双向层,它只输出一个向量(默认情况下, return_sequences=False )。 双向层的输出是前向传播和后向传播的最后一个输出的合并结果。 同样,默认情况下,它是串联。 所以输出形状是 (None, 64),因为前向和后向 LSTM 都输出一个 32 维向量。
例子 这是一个使用 TextVectorization、Embedding、Bidirectional LSTM 和 Dense 层对电影评论的情绪(正面或负面)进行分类的模型示例。
CuDNN 性能 在 TensorFlow 2 中,当 Nvidia GPU 可用时,内置的 LSTM 和 GRU 层将默认利用 CuDNN 内核。 但是,如果更改以下任何默认配置,则不会使用 CuDNN。 因此,请注意选择非标准配置对性能的影响。
如果使用masking,则从右填充更改(稍后讨论)。 可变大小 RNN/LSTM/GRU 时间序列 TF 中的 RNN、LSTM 或 GRU 可以很好地处理可变大小的时间序列,而无需额外编码。 您可以使用具有不同时间步数(序列长度)的“输入”将数据输入模型(输入)。 真正的问题在于训练。 训练采用输入张量 (None, None, embedding_dim),其第一维是批量大小,第二维是序列长度。 填充 除非在训练中的批量大小为 1,否则您需要将输入填充为固定长度,如下面的代码。
Embedding 中的 mask_zero 标志指示层将零值视为填充并忽略相应的输入。
如果 mask_zero 为真,Embedding 层也会为对应的输入生成一个单独的掩码张量 masked_output._keras_mask。
而这个被masked的张量将被传播到下一层。
这是在序列模型中设置带有masking的嵌入层的代码。
自定义层 mask信息将作为“call”中的“mask”传递给层。 在下面的代码中,在计算 softmax 值之前,它将与填充输入对应的所有分数屏蔽为零。
但是,默认情况下,mask只会传递一次,并且在该层之后将被销毁。 要将mask传递到下一层,请将 supports_masking 设置为 True。
在自定义图层中生成mask 图层可以使用mask,但也可以创建mask。 这是通过实现“compute_mask”来完成的。
|