|
在本文中,我们将介绍 TensorFlow 2.x (TF 2.x) 中的一些关键扩展和库。 这将包括 TF Datasets、TF Hub、XLA、模型优化、TensorBoard、TF Probability、神经结构化学习、TF Serving、TF Federated、TF Graphics 和 MLIR。 TensorFlow 数据集 它支持加载许多流行的数据集。 如需完整列表,请查看 TF 数据集类别。 这是加载 MINST 数据的代码示例。
TensorFlow Hub TensorFlow Hub 是训练有素的机器学习模型(如 BERT)的存储库,用于微调和可部署模型。 如需完整列表,请查看 TF hub。 在下面的代码中,我们加载了一个模型,用于在英语 Google News 200B 语料库上训练的基于标记的文本嵌入。
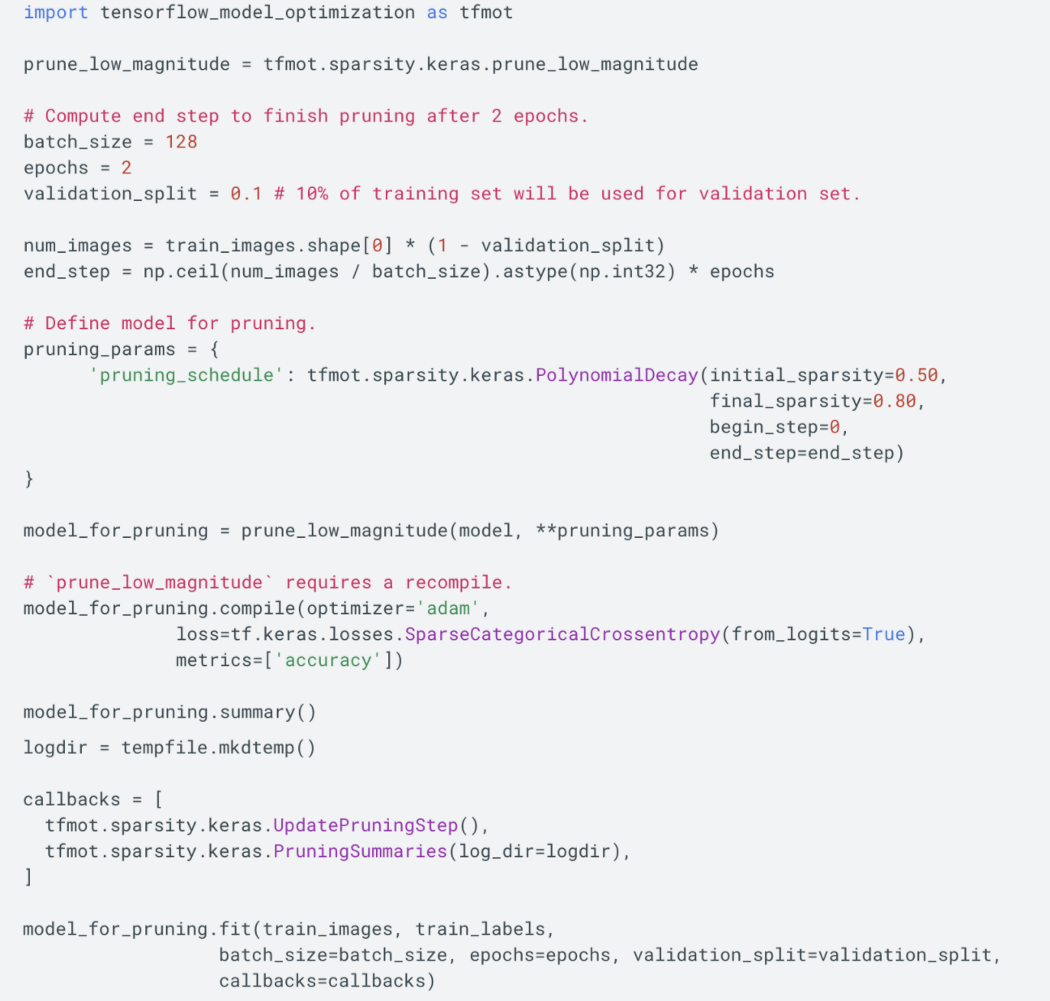
模型优化 使用权重裁剪和/或量化可以进一步优化训练模型,而不会损失或损失很小的准确性。 下面的代码使用权重裁剪优化了一个已经训练好的“模型”。
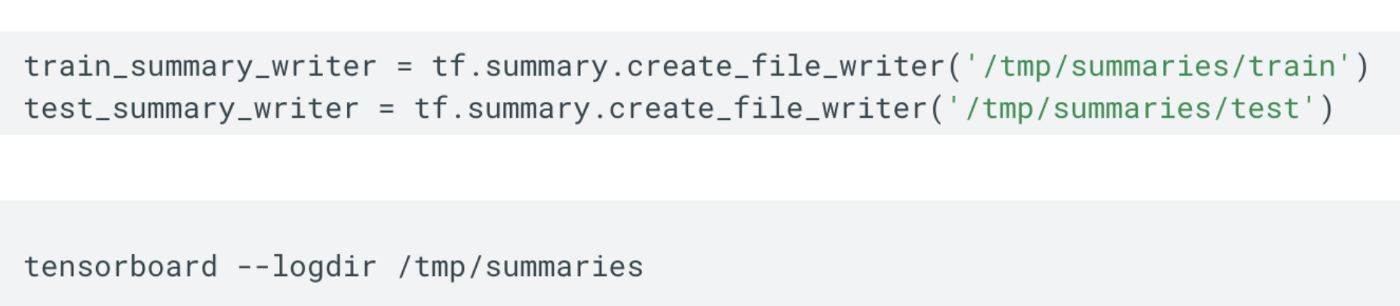
使用权重聚类也可以减少内存占用。 它首先将每一层的权重分组为 N 个簇,然后为属于该簇的所有权重共享该簇的质心值。 TensorBoard TensorBoard 是 TF 应用程序的可视化工具。 它显示应用程序记录的标量指标(如准确性和损失)、输入数据、计算图以及可训练参数的分布和直方图。
在 TF 应用程序中,我们将信息存储到可以从 tensorboard 应用程序读取的文件中。
TensorFlow 概率 (TFP) TFP 提供了一个库来建模概率分布、变分推理、马尔可夫链蒙特卡罗等…… 下面的代码从正态分布中采样 100K 数据并对其进行操作以采样 100K 伯努利分布数据。 收集到数据后,代码用这些数据拟合伯努利分布并找到模型参数。
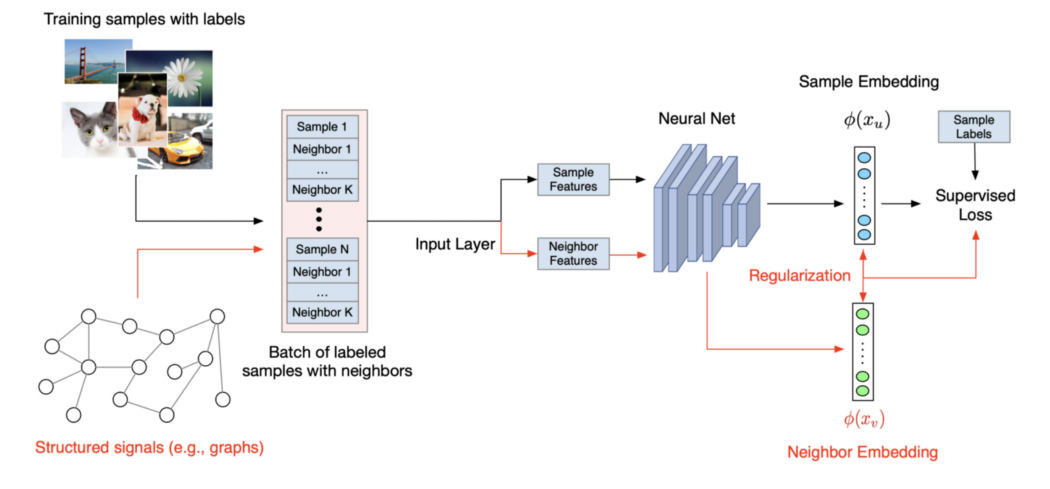
Neural Structured Learning (NSL) 在计算机视觉中,信息被编码在图像中。 在 NLP 中,它包含在文本中。 但是,可以在图形中编码丰富的信息来描述样本之间的关系。 Cora 数据集是一个引文图,其中节点代表机器学习论文,边代表论文对之间的引文。 我们可以同时利用节点(论文内容)和链接(引文)将每篇论文更好地分类为七个类别之一。 在下图中,我们希望邻居之间的嵌入特征相似。
例如,我们可以引入邻居损失来惩罚邻居嵌入的差异 (D)。
使用附加的边缘信息,我们可以在执行文档和情感分类时执行图正则化。 在计算机视觉中,我们可以将噪声添加到图像的像素中以生成人工neighbors以避免对抗性攻击。 这是在使用 NSL 的深度学习模型之上生成对抗正则化模型的代码。
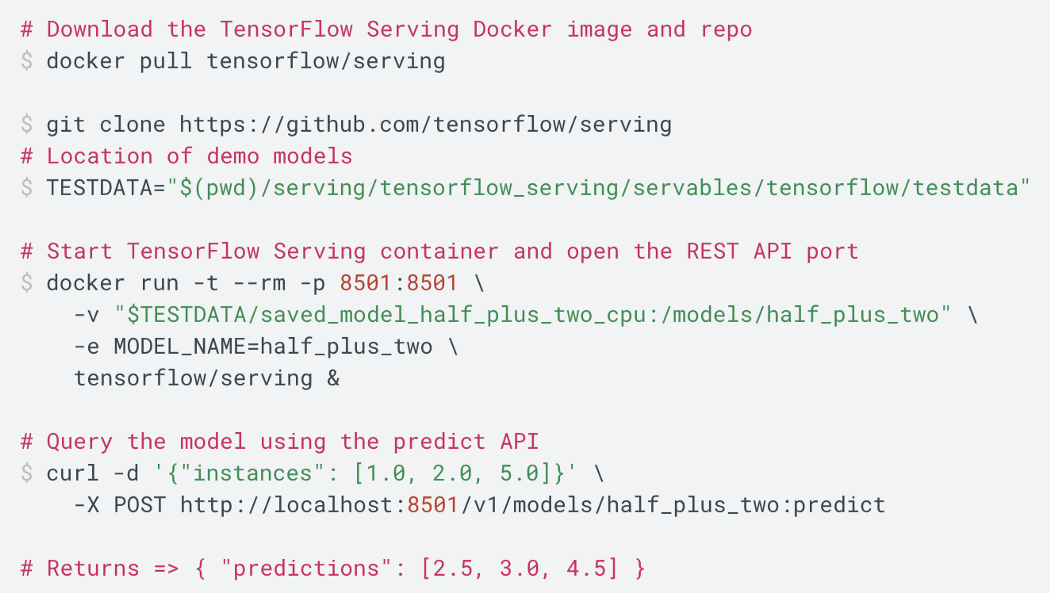
TensorFlow Serving (TFS) TensorFlow Serving 为机器学习模型的生产环境中的客户端请求提供服务。 下面的命令使用 TFS 创建一个 docker,用于部署 y = x/2 + 2 的模型。
下面,SavedModel “my_model” 在端口 8501 上提供服务。
TensorFlow Federated (TFF) TFF 对去中心化数据进行模型训练。 TFF 可以在将训练数据保存在本地的参与客户中训练此模型。 例如,手机可以在不将敏感用户数据上传到服务器的情况下训练模型。
在联合学习中,客户端设备根据本地收集的数据计算 SGD 更新。 模型的更新在远程服务器中收集和聚合,而不是将更敏感的用户数据发送到该服务器。 最后,聚合模型被发送回客户端。
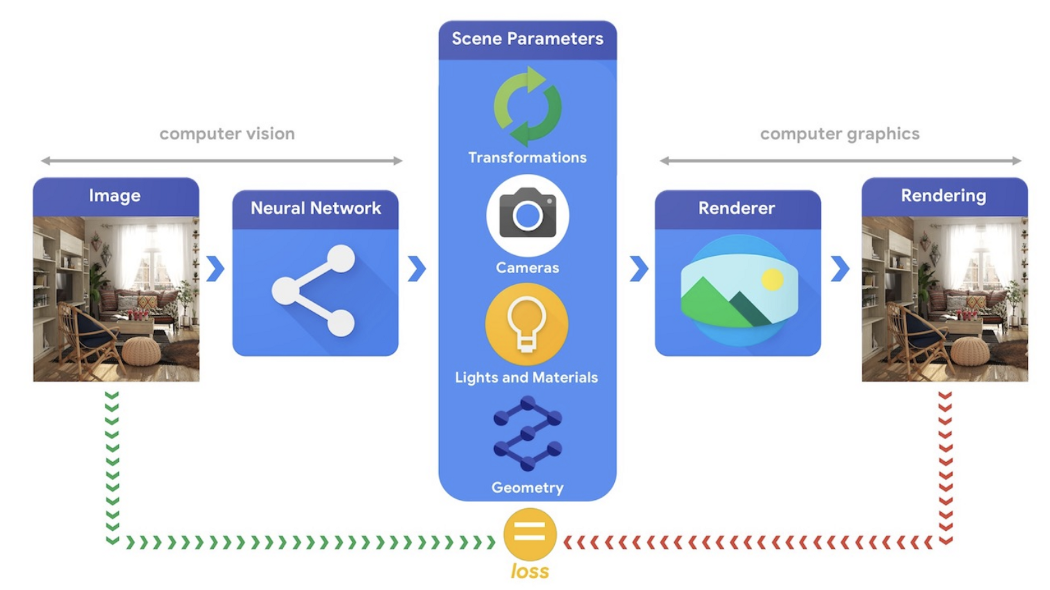
Tensorflow Graphics Tensorflow Graphics 提供可用于训练机器学习模型的可微分图形和几何层(例如相机、反射模型、空间变换、网格卷积)。 我们可以使用 3D TensorBoard 来可视化 3D 渲染。 例如,我们可以训练神经网络模型将图像分解为可用于渲染场景的相应场景参数。 这样的模型将被训练以最小化重建损失。
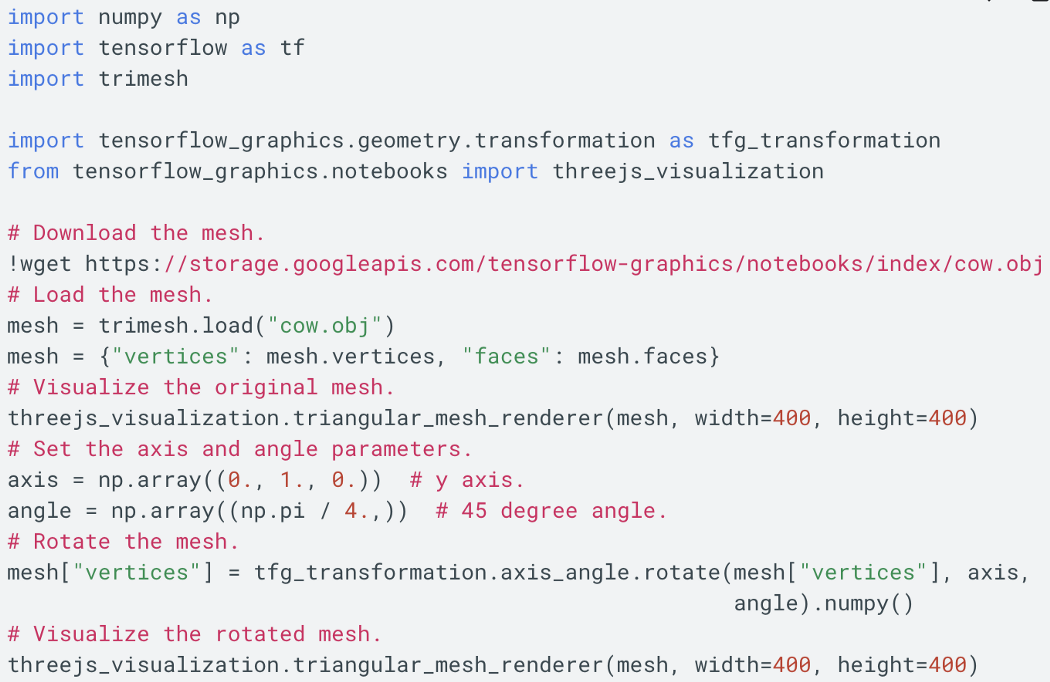
以下是使用 Tensorflow Graphics对象的示例代码。
MLIR MLIR 创建要在 AI 加速器上执行的机器学习模型或算法的中间表示。 这种表示弥合了逻辑模型和物理芯片设计之间的差距。 目标是让这种表示可以在 AI 芯片中得到更好的优化和执行。
XLA XLA 是一种 JIT 编译器,它采用计算图并在组合和删除冗余计算节点时进行优化。 然后,它将它们编译为目标设备的内核序列,并进行进一步优化。 例如,在 GPU 设备中,XLA 组合了可以在单个 GPU 操作中执行的计算节点。 |