|
2017 年 Google Brain 的一篇论文“Are GANs Created Equal?” 声称 最后,我们没有发现任何经过测试的算法始终优于原始算法的证据。 该论文主张我们应该花时间在超参数优化上,而不是测试不同的cost函数。 那些像 LSGAN、WGAN-GP 或 BEGAN 这样的cost函数已经完了吗? 我们应该停止使用它们吗? 在本文中,我们研究了所呈现数据的细节,并尝试自己回答这个问题。 让我们看一下论文中引用的两个主要主张:
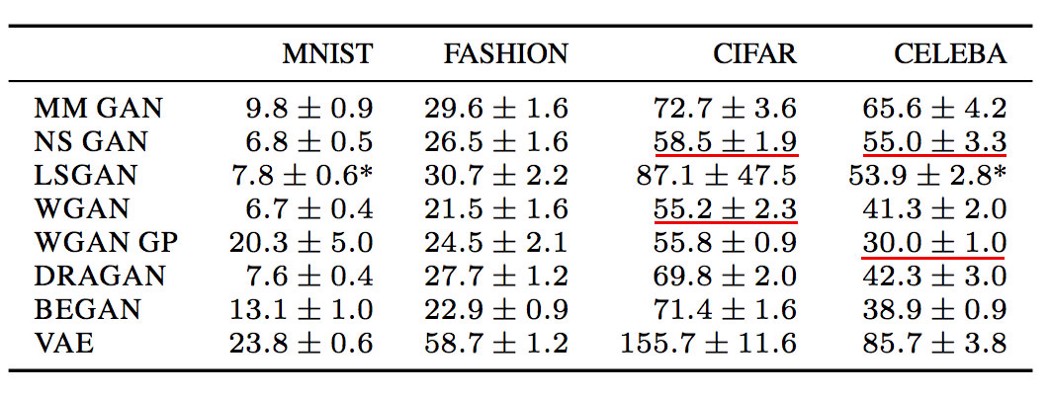
这对于实验中的两个低复杂度数据集是正确的。 然而,与 CELEBA 中的其他方法相比,WGAN-GP 在 FID 分数上的表现更好(越低越好)。 在 CIFAR10 中,cost函数在任何预算水平上的表现都不同。
如果按照下图,WGAN 和 WGAN-GP 分别在 CIFAR10 和 CELEBA 中的 FID 得分最好。 因此,对于复杂的数据集,cost函数可能很重要。
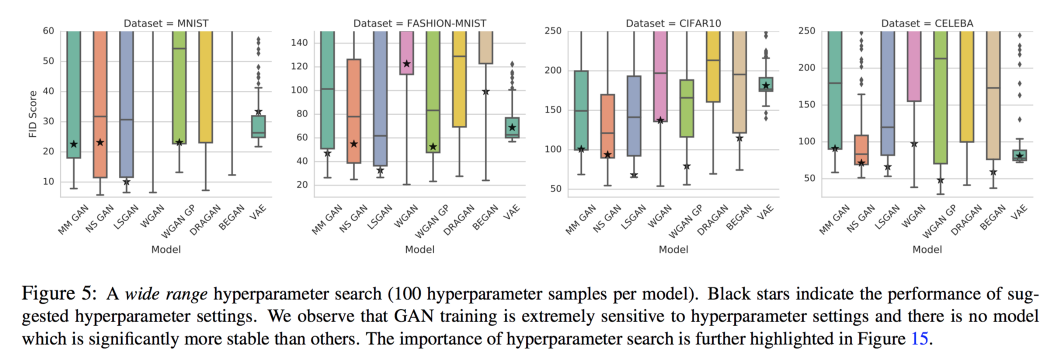
在实践中,许多分区器使用的数据集非常复杂。 许多项目尚未达到商业质量,因此推动图像质量仍然是重中之重。 根据提供的数据,可能会继续使用不同的cost函数对其进行测试。 超参数和计算预算 在不同的数据集中,没有一个cost函数始终比其他cost函数表现更好。 该论文声称新的cost函数在训练 GAN 时不一定更稳定或更可预测。 由于在不同超参数下的性能范围很广,超参数调优对于任何cost函数都尤为重要,因此它会有更好的回报。
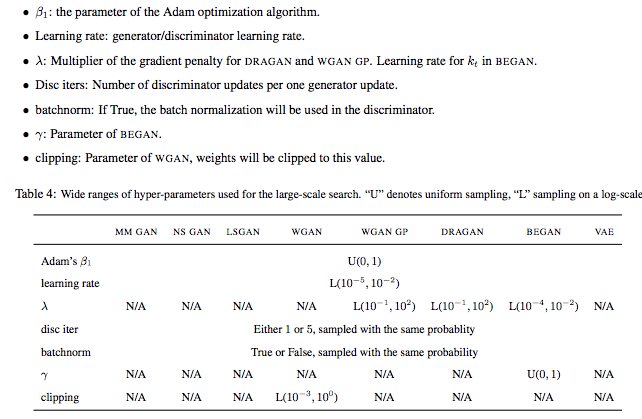
但是让我们来看看论文如何进行调整的细节。 以下是针对每种算法调整的超参数列表。
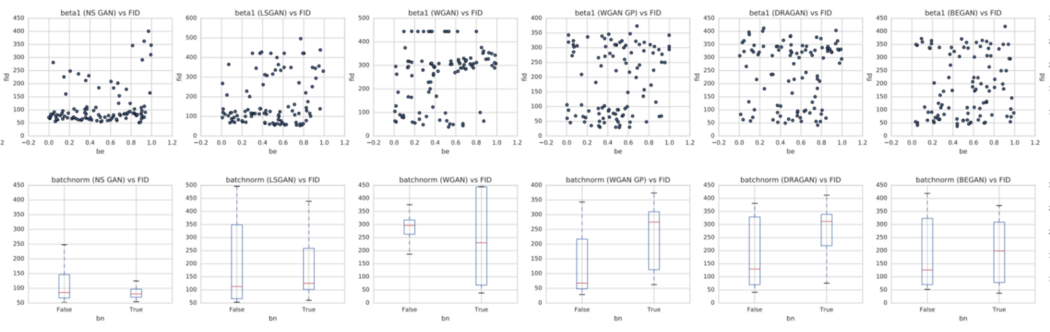
beta 和batch normalization等超参数在某些cost函数中具有广泛的性能。
但 beta 最终设置为 0.5,并且通常每个cost函数都有一个首选的batch normalization设置。 包括大范围的超参数搜索可能会使一些cost函数处于不必要的劣势并高估资源需求。 我的看法是什么? 那么我的看法是什么? 我们还没有找到始终比其他函数更好的最佳cost函数。 但似乎有一个在特定的复杂数据集中效果更好。 然而,没有模型在非最优超参数下表现良好。 为 GAN 模型调整超参数更难,也需要更长的时间。 因此,如果没有足够的时间,找出最喜欢的cost函数是所能做的最好的事情。 如果你的性能停滞不前或停滞不前,可以给其他cost函数一个机会。 所以真正的问题不一定是我们是否应该尝试新的cost函数。 真正的问题是什么时候。 在新cost函数的开发过程中,我们确实意识到了一些值得追求的趋势。 甚至我们可能还没有找到一个总能击败另一个的cost函数,但努力可能会继续下去。 同时,我们将处理大量相互矛盾的信息。 但随着时间的推移,我们会纠正一些误解,更好地理解事物。 事实上,Google Brain 的论文为我们提供了大量关于特定超参数对不同cost函数的影响的原始数据。 当我们计划调整时,强烈建议使用此信息。 最终,即使资源非常有限,尝试不同的cost函数也会容易得多。
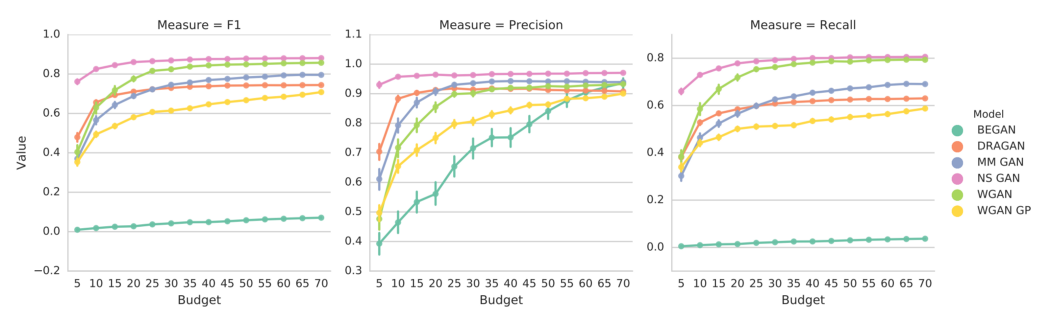
关于 F1、precision和recall score的思考 在 Google 论文中,它还展示了许多新的成本函数在其多项式玩具实验中具有较低的 F1 和召回分数。 然而,CELEBA 中 BEGAN 的低分与其相对较高的 FID 分数无法调和。 因此,这些测量对复杂数据集的影响仍然值得怀疑。
此外,如果图像质量提高,部分模式崩溃(或召回率降低)对于许多 GAN 应用程序来说不一定都是坏消息。
|