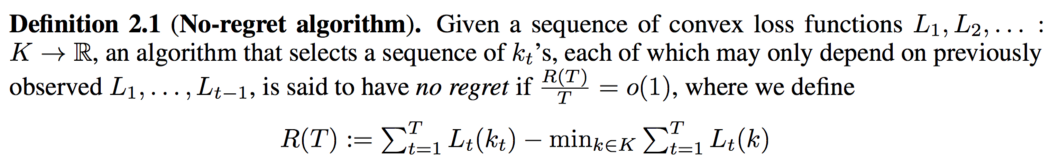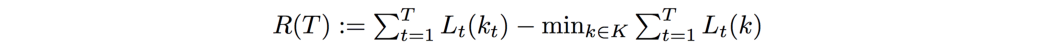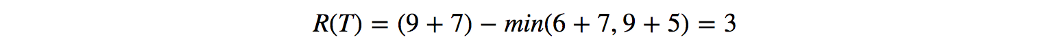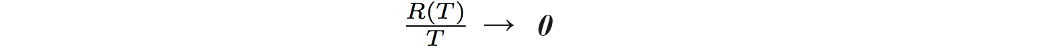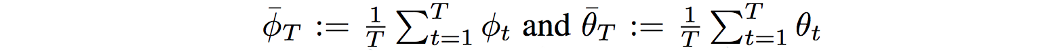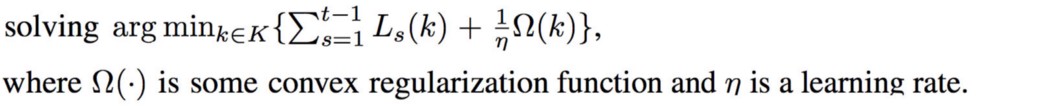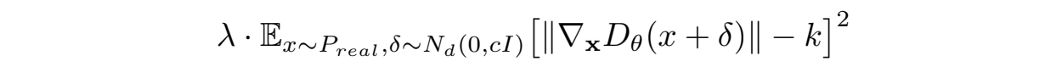|
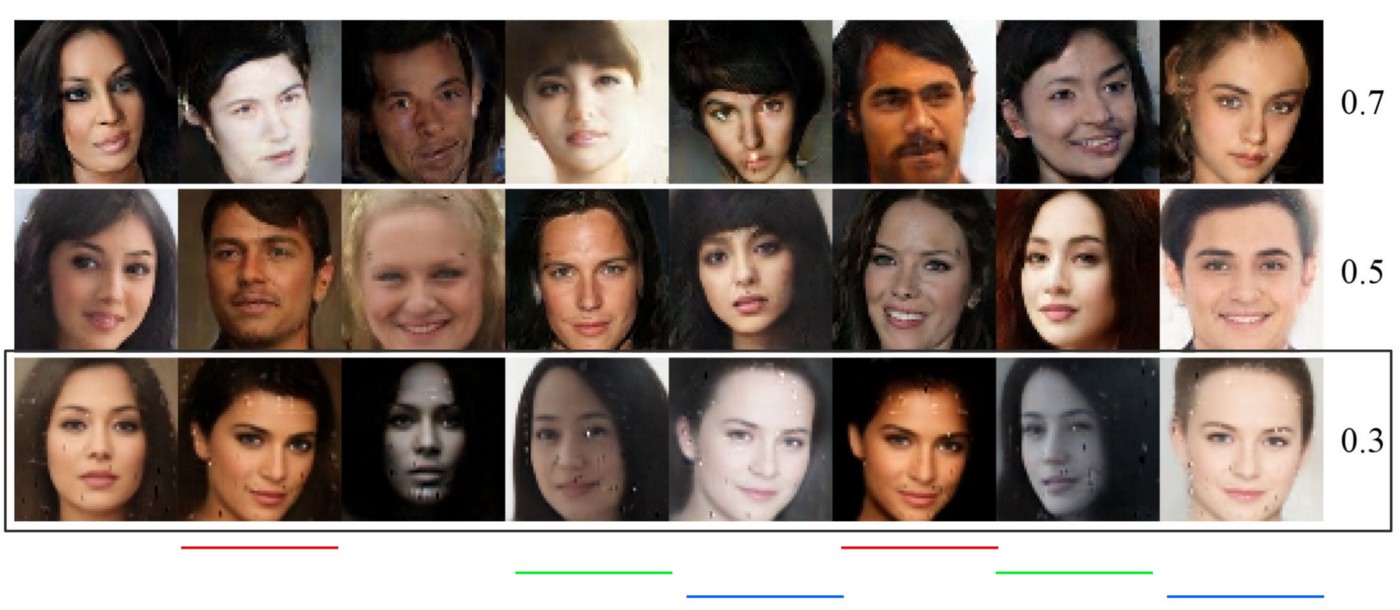
模式崩溃是训练 GAN 的一个主要问题。 在下图中,我们使用一个 BEGAN 来生成人脸。 对于每一行,我们使用不同的超参数 γ 来训练模型。 如最后一行所示,模式在 γ=0.3 时开始崩溃。 例如,带有相同颜色下划线的面孔看起来相似。
尽管完全坍塌并不常见,但它仍然是一个高度研究的领域:
作为 GAN 系列的一部分,我们着眼于 Deep Regret Analytic Generative Adversarial Networks (DRAGAN),它对模式崩溃的回答以及它对模式崩溃的假设。 凸凹游戏中的无悔算法 GAN 被研究为一个极小极大游戏,并在成本函数 J 上使用交替梯度下降来优化鉴别器 D 和生成器 G。
在 GAN 中,我们希望找到判别器 θ 最大化 J 并且生成器 φ 最小化它的平衡。 让我们使用遗憾最小化从另一个角度来看待它。 什么是无悔算法?
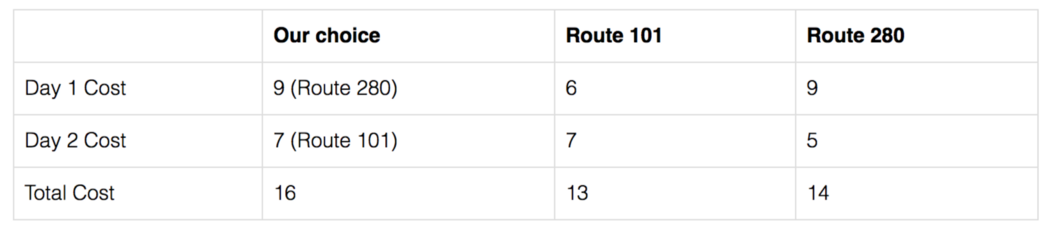
那么什么是遗憾R(T)。 假设我们每天从北京前往上海。 每天,我们可以选择采用不同的路线 kt 并使用成本函数 Lt 来计算当天路线的成本。 T 天后,我们计算总成本。 接下来,我们重新计算,但对于每一天,我们使用相同的路线。 我们计算不同路线的总成本并选择成本最低的一条。 我们的遗憾只是差异。
无遗憾意味着遗憾 R 不与时间成正比增长。 即我们行动的额外成本只是固定的开销。 如果 T 很大,则平均值应接近零。
现在我们可以应用无悔学习来找到 GAN 的平衡点。 让我们 V* 是游戏的均衡值(均衡时 J 的值)。 对于每个玩家,我们计算其平均迭代次数,定义为:
R1 和 R2 分别是玩家 φ 和 θ 的遗憾。 那么可以证明:
如果我们遵守无遗憾条件,遗憾将接近于零,平均迭代将收敛。 我们可以使用“Follow The Regularized Leader”(FTRL)来解决无悔问题,即
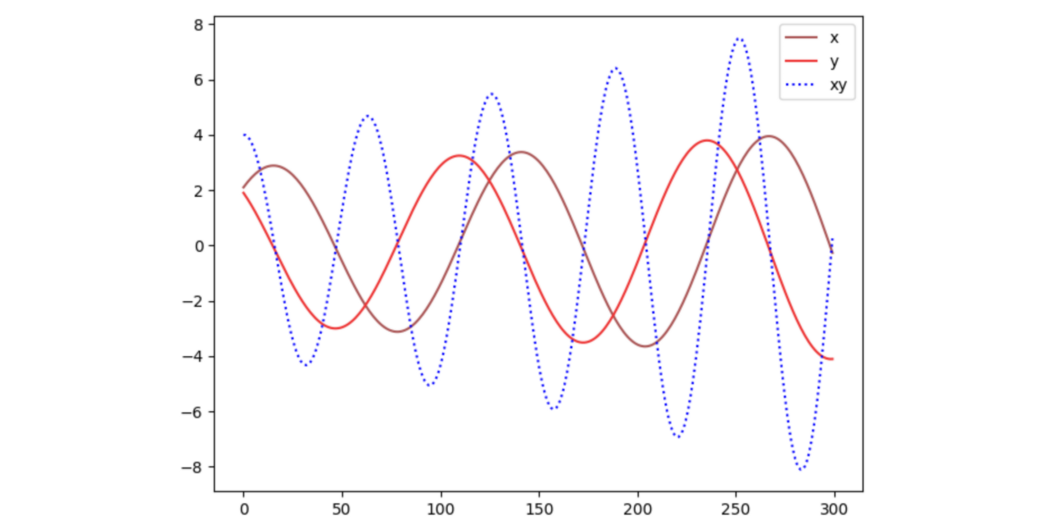
这就是在线梯度下降。 即后悔最小化使我们得到与我们在 GAN 中使用的凸凹游戏相同的解决方案。 因此,作者将其用作解释 GAN 机制的替代观点。 考虑目标函数 L=xy,其中一个玩家控制 x 最大化 L,一个玩家控制 y 最小化 L,这个极小极大游戏不会使用替代梯度下降收敛(如上一篇 GAN 文章中所述)。
但是,可以通过简单地对遗憾最小化中的迭代进行平均来找到解决方案。 非凸博弈 对于非凸博弈,模型可以收敛到某个局部均衡。
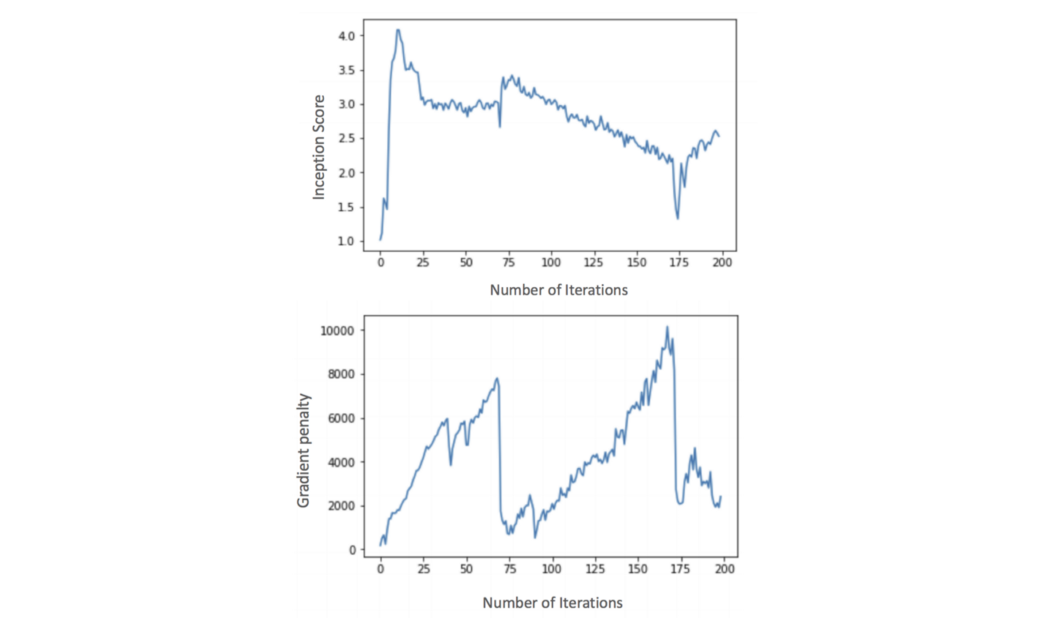
DRAGAN 论文假设模式崩溃是博弈收敛到不良局部均衡的结果。 它还假设初始分数的突然下降与梯度的范数有关。 因此,为了提高图像质量,DRAGAN 建议在成本函数中添加梯度惩罚。
梯度惩罚 这是推荐的梯度惩罚。
对于 DRAGAN 所做的实验,其中 λ 约为 10,k = 1,c 约为 10。 更多思考 DRAGAN 提出了解释 GAN 的新视角。 它假设模式崩溃是博弈收敛到糟糕的局部均衡的结果。 为了减轻这种情况,建议使用梯度惩罚。 DRAGAN 也是 GAN 训练中经常提到的成本函数之一。 |