|
在本文中,我们将讨论如何使用 TensorFlow (TF) 数据集构建高效的数据管道以进行训练和验证。 但是,如果训练数据很小,我们可以将数据放入内存中,并将它们作为 Numpy ndarry 进行预处理。 然而,许多现实生活中的数据集太大了。 为了扩展解决方案,我们在扩展解决方案时使用预处理、预取和缓存等功能创建数据管道 (tf.data.Dataset)。 使用 NumPy 进行 MNIST 数据预处理 尽管如此,例子数据集在开发新模型和算法方面仍然很重要。 所以,让我们从这些小数据集开始我们的讨论,比如 MNIST。 Keras 提供 API 以将流行的数据集作为 NumPy ndarray 加载到内存中。 当一个 ndarray 被传递到一个 TF 操作中时,它会自动转换为一个 TF Tensor(反之亦然)。 如果可能,TF 会为 Numpy ndarray 和 Tensors 维护相同的底层内存表示。 所以转换很容易。 然而,如果 Tensor 托管在 GPU 中,则转换需要将数据复制到 CPU 主机,因为 NumPy ndarray 在主机内存中始终有一个副本。 如果发生不必要的情况,请注意性能影响。 对于小图像数据集,我们将它们加载到内存中,重新缩放它们,并将 ndarray 重新reshape为第一个深度学习层所需的形状。 例如,卷积层的输入形状为(批量大小、宽度、高度、通道),而密集层的输入形状为(批量大小、宽度 × 高度 × 通道)。 以下代码在 0 和 1 之间重新调整 MNIST 像素值,并为卷积层准备数据。 因此,我们将使用 [..., tf.newaxis] 将 ndarray 从 (60,000, 28, 28) 扩展到 (60,000, 28, 28, 1)。 或者,我们可以使用 reshape 来改变 ndarray 的形状。
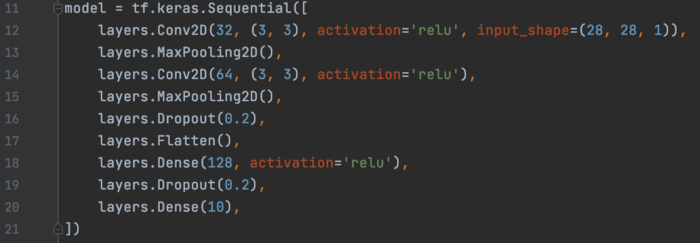
这是CNN模型。
在下面的第 29 行,我们准备输入数据以供dense层使用。
然后,我们使用 model.compile 配置模型进行训练。
接下来,model.fit 使用我们之前准备的训练图像和标签训练下面的模型 10 个epochs。 当 model.fit 的输入数据是 ndarray 时,数据以小批量训练。 默认情况下,batch size(batch_size)为32。另外,validation_split=0.1,我们保留最后10%的训练样本进行验证。
我们还可以划分训练样本并明确传递验证数据。
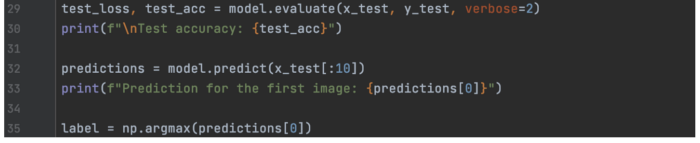
以下是进行评估和预测的剩余代码。
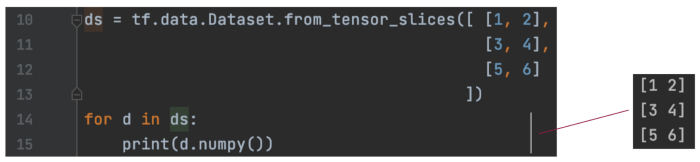
当输入数据为 ndarry 时,model.fit 会自动准备小批量。 在讨论了小数据集之后,让我们看看我们如何使用 Dataset 来扩展数据加载和处理。 tf.data.Dataset 基础 作为一个简单的演示,下面的代码使用 Python list创建了 4 个数据样本。
dataset.from_tensor_slices 第一维对其进行切片。
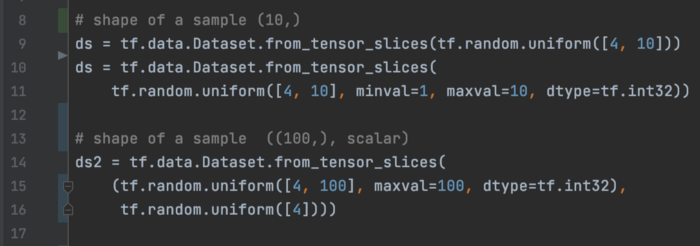
在早期的开发过程中,我们经常造数据来测试logic。 在下面的代码中,我们将不同数据形状的uniform数据输入到一个数据集中。
在第 14 行,ds2 生成元组——第一个元素包含 100 个特征,第二个元素包含一个标签。 我们还可以使用多个数据集来创建一个新的数据集。 例如,下面的代码创建了一个新数据集,该数据集提供第一个和第二个元素分别来自 ds2 和 ds 的元组。
我们可以通过使用 take(1) 检查第一个数据样本来举例说明数据集生成的内容。
我们也可以定义一个稀疏张量。 下面的索引是具有非零值的元素列表,值存储相应的值。
Mini-Batch (dataset.batch) 到目前准备的数据集一次生成一个样本。 然而,训练通常以小批量进行。 在下面的示例中, dataset.batch(size) 创建一个数据集,生成每个包含 4 个样本的小批量。
Cache & Prefetch 为了提高数据集pipeline的性能,通常的做法是将pipeline与缓存和prefetch链接起来。 缓存允许数据缓存在内存和本地存储中,prefetch允许多个线程预加载数据。
这是链的通常顺序,包括 shuffle 和 batch。 (我们稍后会讨论 shuffle。)
带有 NumPy ndarray 的数据集 我们可以围绕 NumPy ndarray 形成数据集并利用数据集 API。 在下面的代码中,我们准备一个来自 Fashion MNIST 的样本数据集。
具体来说,我们在第 27 和 28 行构建了一个数据集。 dataset.batch(32) 不是一次生成一个样本,而是生成小批量。
fmnist_train_ds 生成一个元组,其中第一个元素包含 32 个图像,第二个元素包含 32 个标签。
我们可以将包含图像和标签的数据集直接传递给 model.fit、model.evaluate 和 model.predict。 对于每次训练迭代,model.fit 将从数据集中训练一个小批量。
带有 NumPy ndarray 和 Keras 预处理层的数据集 在上一节中,数据预处理是在模型拟合之前进行的。 Keras 预处理层提供了在模型内执行此处理的选项。 在下面的示例中,重新缩放和重塑被定义为模型内的层。 如果模型在图形模式下运行,它可以通过其他操作进行优化并在 GPU 上运行。 这是代码,但我们将在另一篇文章中推迟对 Keras 预处理层的讨论。
TensorFlow Datasets TensorFlow 还提供了一大类Datasets作为数据集下载和加载。
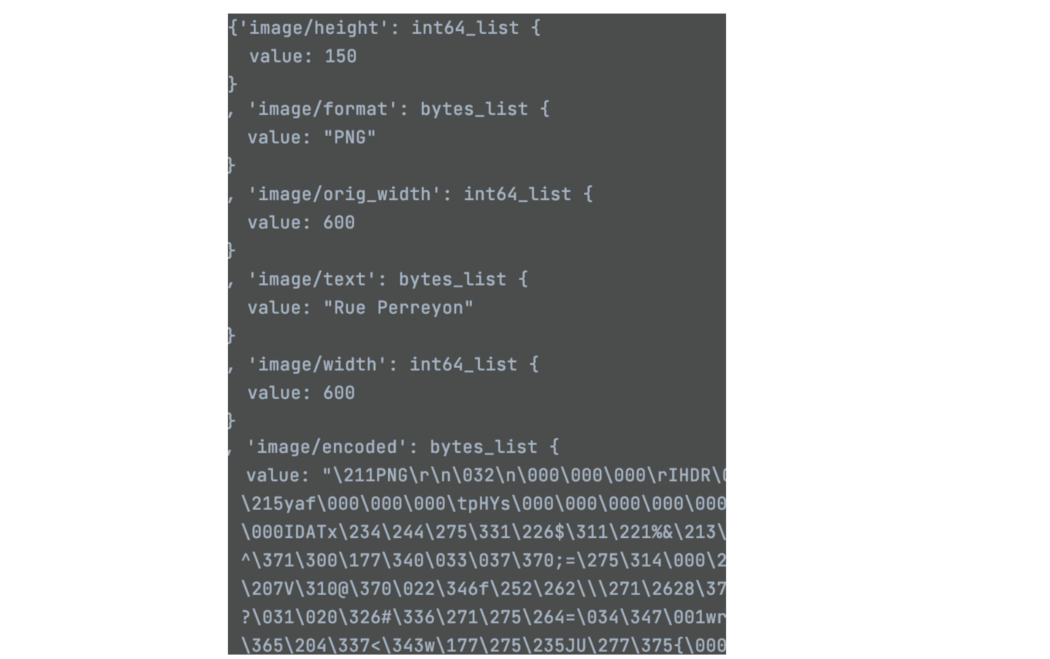
TFRecord Dataset 一些TF项目以TFRecord的形式保存数据。 它是 TF 的一种二进制存储格式,用于存储一系列二进制记录。 与文本格式相比,这种二进制格式更加简洁。 因为它是二进制的,在 TF 中具有本机支持,所以一些项目,特别是 NLP 中的项目,将大量数据集保存到 TFRecord 文件中,以便在训练期间可以更有效地读取。 TFRecord 文件包含 {“string”: value} 对形式的序列化 tf.train.Example 消息。 下面是文本形式的示例消息的可视化,其中包括图像元数据(宽度、高度)和图像数据。
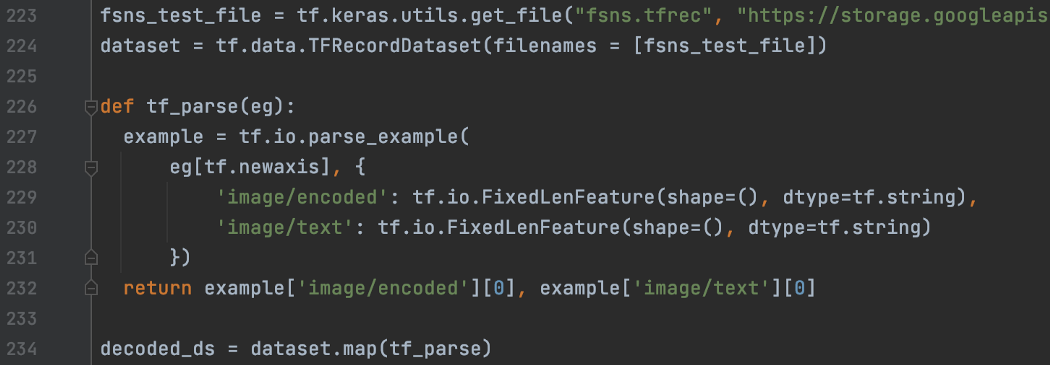
让我们看看如何从 TFRecord 文件构建数据集。 首先,我们创建一个由 TFRecord 文件列表组成的数据集。
然后,我们可以使用 tf.io.parse_example 将 tf.train.Example 消息转换为 Tensor、SparseTensor 或 RaggedTensor 对象。 下面的数据集为每个样本创建一个字符串张量“eg”,我们使用 tf.io.parse_example 从中提取图像数据和标签。
下面的代码手动检查数据集中的样本并显示相应的图像和标签。
作为演示,左边的图表是包含在 TFRecord 文件中的特征的可视化。 右边是tf.io.parse_example提取的数据。
这是另一个例子。
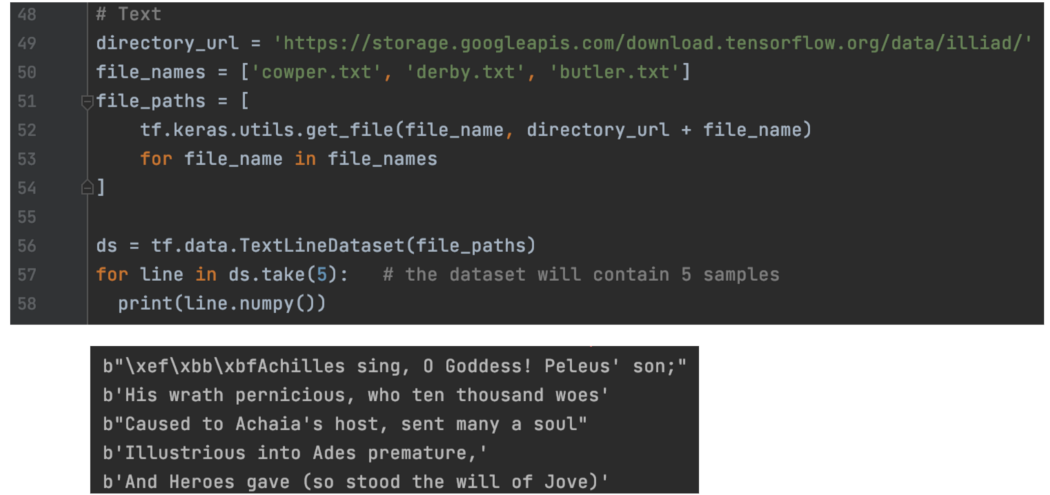
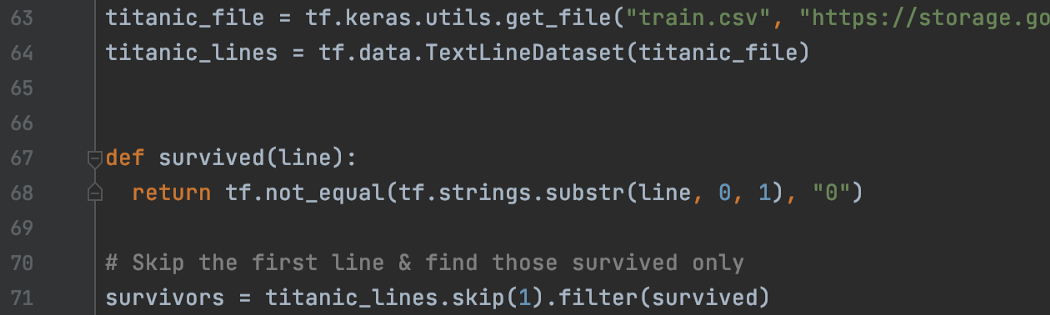
Text Line Dataset 数据样本可能包含在包含许多文件的多个目录中。 在本节中,我们将从多个文本文件创建一个数据集。 我们将使用 TextLineDataset 创建样本,其中每个样本都包含一行文本。
下面的代码混合来自不同文件的数据——以轮换方式从每个文件中选取一行文本。 这允许采样数据在训练中更加随机。
我们还可以使用“skip”来跳过文件的标题并应用过滤器来选择要使用的文本行。
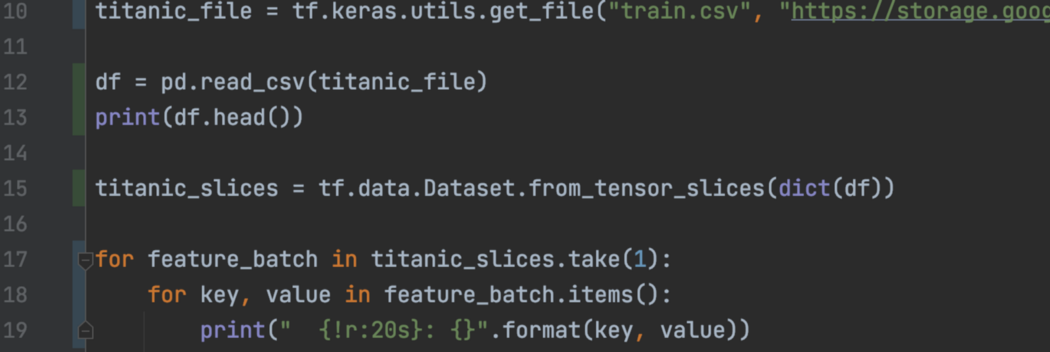
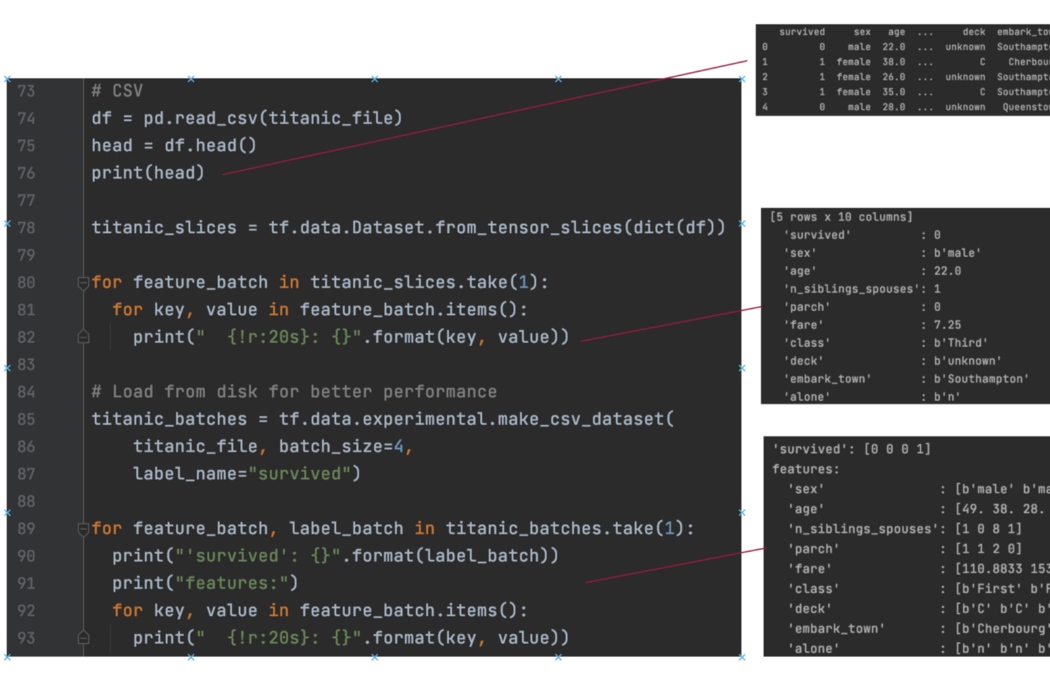
CSV Dataset 从 CSV 数据创建数据集。 每个数据样本将包含一个特征字典,比如对于 Titanic CSV 数据集来说,生存:0,性别:男性,年龄:22.0,……。 如果数据量不大,我们可以用 Pandas 读入内存,然后用 from_tensor_slices 创建一个数据集。
但是,对于大数据样本,我们希望按需从磁盘读取样本。 在第 85 行,我们使用 tf.data.experimental.make_csv_dataset 从文件中逐渐加载样本。
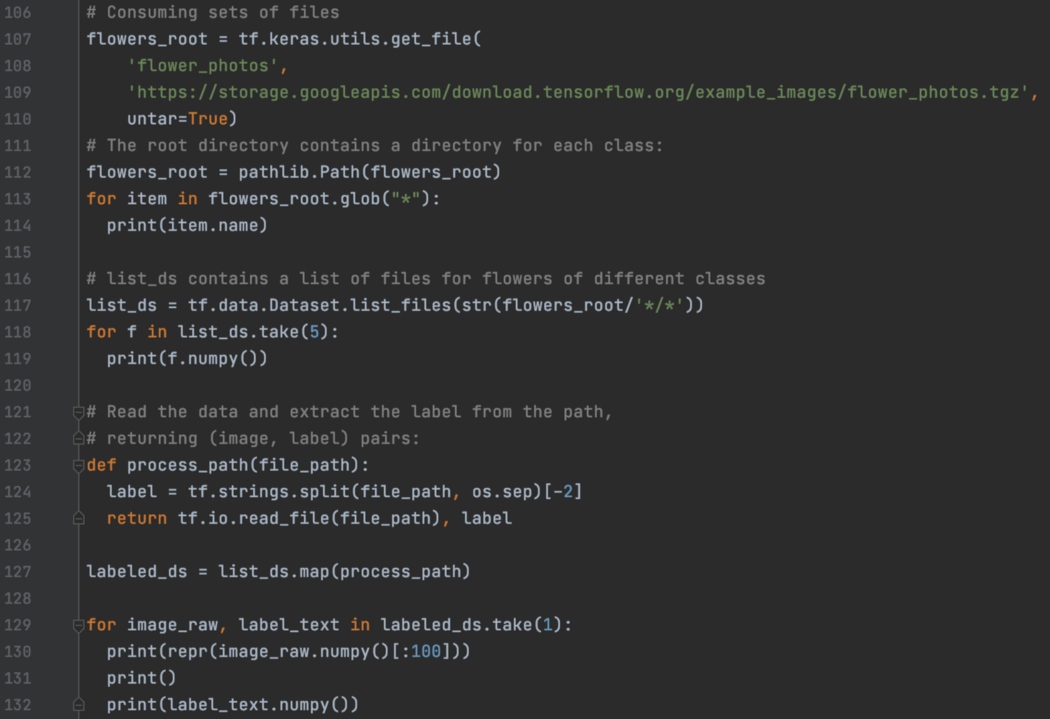
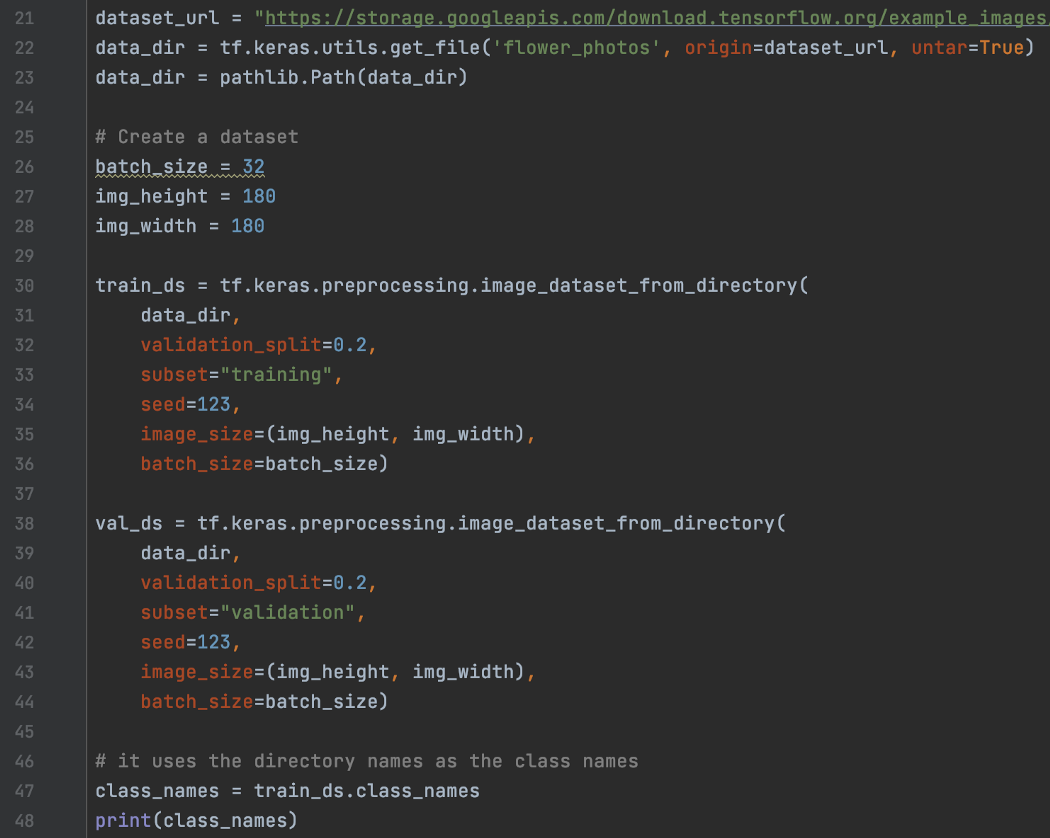
Dataset - 每个样本一个文件 接下来,我们要处理多个文件——特别是每个样本一个文件。 在下面的第 117 行,我们创建了一个包含来自不同目录的文件名的数据集,每个目录将保存特定类别的样本。 然后在第 127 行,我们在顶部创建另一个数据集。 这个新数据集包含图像和相关标签——我们将使用 process_path 将文件中的数据映射到原始图像数据和标签。 由于属于同一类的图像存储在同一目录中,因此我们只需使用图像父目录名称作为其类标签。
上面的代码提供了从多个文件创建数据集的精细控制。 但是 Keras 预处理还为图像提供了更简单的高级 API。 首先,我们下载一个 zip 文件并将文件解压缩到:
然后,Keras 预处理可以使用 preprocessing.image_dataset_from_directory 从这些目录直接创建数据集。 它将文件的内容视为单个样本。
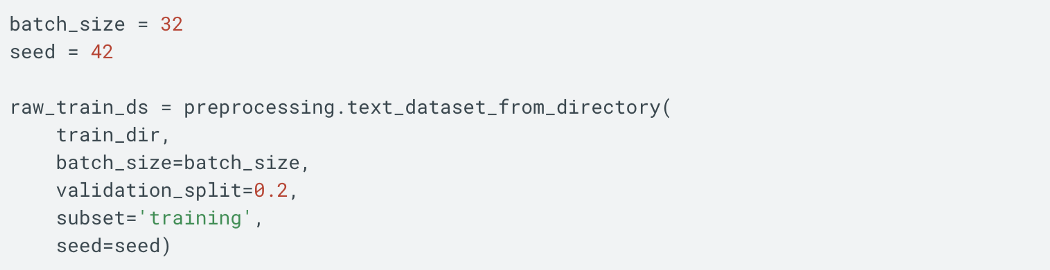
注意:上面的训练数据集和验证数据集来自同一个源,data_dir。 为避免样本重叠,它们应使用相同的seed值或 shuffle=False。 还有另一个版本,称为 preprocessing.text_dataset_from_directory 用于文本文件。
Padding 在许多 RNN 模型中,输入时间序列的长度是可变的。 实际上,TF中内置的RNN模型对于变长输入是没有问题的。 问题在于需要张量的训练。 所以。 在每个训练步骤中,同一批中的所有样本必须具有相同的编号序列(定长序列)。 这可以通过使用下面的 padded_batch 创建数据集来实现。 它找到一个batch内最长的序列长度,并将批次内的所有样本扩展到这个长度并填充 0。例如,在下面的第一个批次中,最长的序列有 4 个时间步长,因此所有样本都扩展到 4 个时间步长。 但是对于第二批,最长的序列是 8,因此,所有样本都填充到长度为 8。
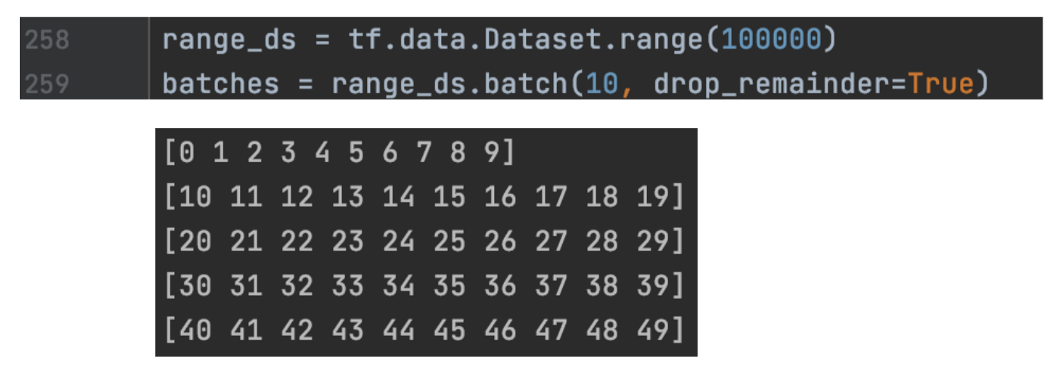
drop_remainder 有时,数据集中的最后一个mini-batch可能不包含完整的batch。 我们可以使用 drop_remainder 来跳过最后一个mini-batch。
Repeat 我们还可以重复数据集中的数据以提供(repeat)更多数据。
152 中的原始数据集仅包含 3 个样本。 通过在第 153 行重复 3 次,我们现在有 9 个样本。 批量大小为 2 时,新数据集生成 5 个mini-batches。
如果初始数据集很小,我们确实希望在批处理(或shuffle)之前调用repeat,这样只有最后一个小批处理的大小可能小于批处理大小。 否则,可能在每个 epoch 结束时都有一个较小的 mini-batch。 Shuffle 如果数据集中的数据是有序的或高度相关的,我们希望在训练之前先将它们打乱。 在下面的示例中,我们有一个包含从 0 到 99 的有序数字序列的数据集。此示例将使用大小为 3 的缓冲区对数据进行打乱。首先,数据集的前 3 个元素 (0, 1, 2) 是 放入缓冲区。 我们随机选择缓冲区中的一个元素作为下一个采样数据,并将其替换为 ds 中的下一个元素。 让我们来看看这个例子。 首先,假设 0 是随机选择的,现在缓冲区变为 (3, 1, 2)。 接下来,假设选择了 2,缓冲区变为 (3, 1, 4)。 随机选择1作为第三个数据,缓冲区变为(3, 5, 4)。 到目前为止,数据集生成了 0, 2, 1。正如所下所示的,如果数据是高度有序的,我们确实需要一个更大的shuffling缓冲区,与数据大小相当,用于shuffling。
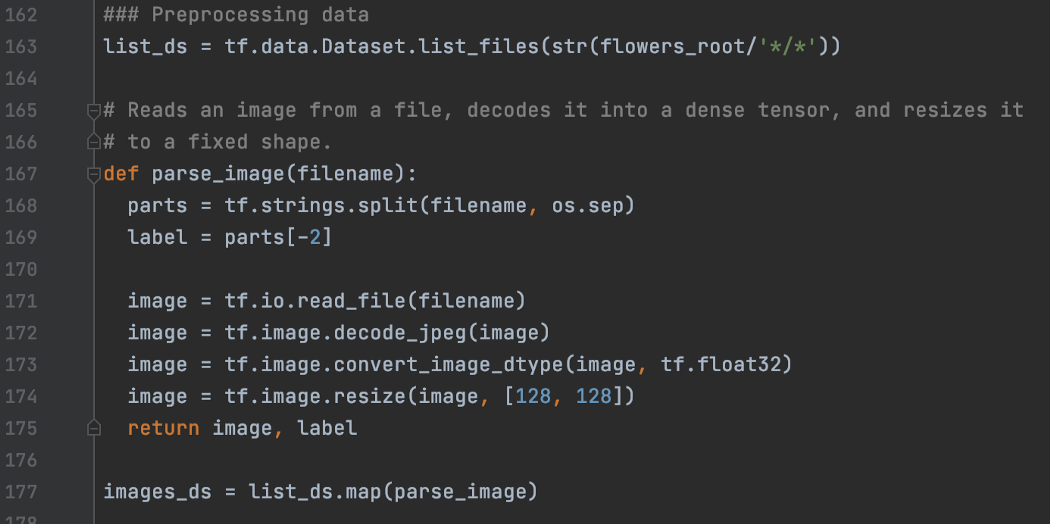
使用 Map 预处理数据 接下来,我们将创建一个具有更复杂预处理的数据集。 在下面的代码中,我们使用“map”来进一步处理数据。 list_ds 数据集提供文件名流。 使用“map”,我们创建了一个新的数据集,将这个文件流处理成图像和标签流。 在“map”中传入方法parse_image,它从文件中读取图像数据,对其进行解码并将其调整为128×128,最后返回预处理后的图像数据和标签。 如果输入图像的纵横比不是 1 比 1,下面的“调整大小”会使图像失真。如果需要,使用 resize_with_pad 用零填充图像以保持原始纵横比。
在下面的代码中,我们使用 scipy.ndimage 中的任意旋转来映射输入以扩充数据。 在这个过程中,创建了一个具有任意旋转图像的新数据集。 但是,ndimage 不是 TF 库。 如果代码在 Eager Execution 中运行是没有问题的。 但是在图形模式下,我们需要先用 tf.py_function 包装它。但是,使用 tf.py_function 会有一个问题:这不适用于使用多个 GPU 或 TPU 的分布式环境。
时序数据(可选) 时间序列模型的标签可能源自输入特征或从输入特征转换而来。 在本节中,我们将演示在创建与源相关的标签时操作数据集的不同方法。 首先,让我们制作一个数据集,其中的数据由递增的数字组成。
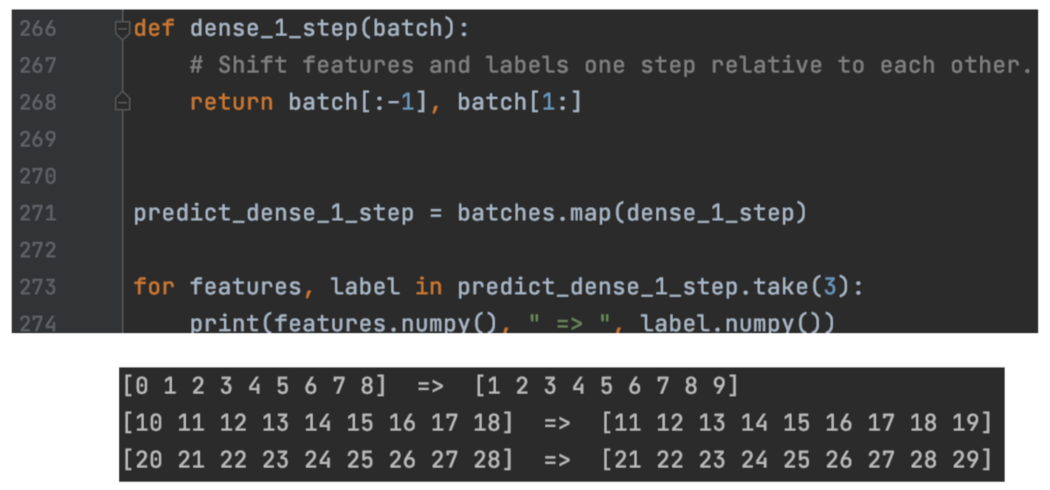
在第一个示例中,我们删除最后一个时间步以创建新输入,并将原始输入向左移动一个时间步以创建标签。
在这里,我们使用 range_ds 中的前 10 个条目作为数据,然后使用接下来的 5 个条目作为标签。
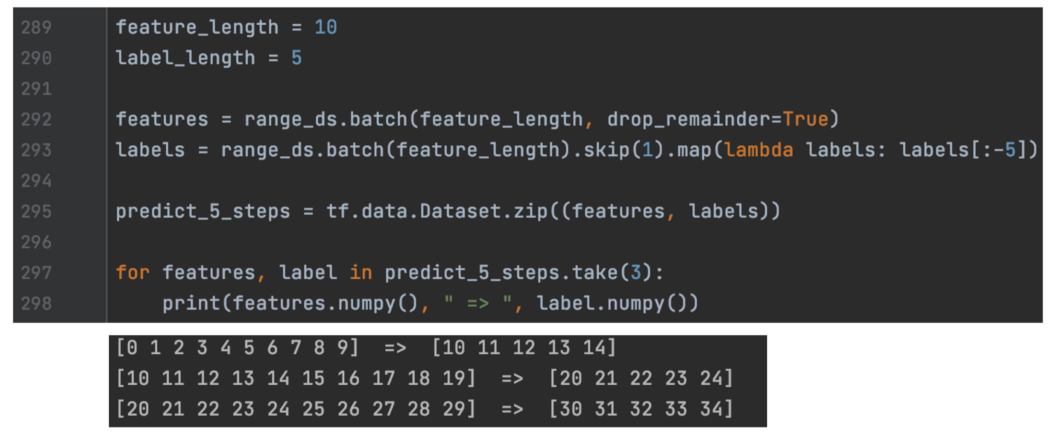
在这个例子中,输入特征是连续的。 然后对于每 15 个特征,我们使用最后五个条目作为标签。
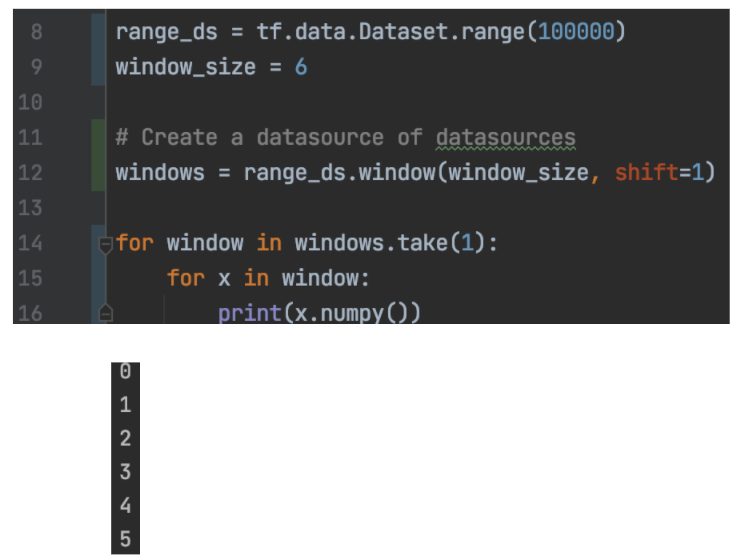
window 下面的 range_ds.window 创建了一个数据集的数据集,即 windows 下面是一个包含许多数据集(子数据集)的数据集。 在第 14 行,我们从 windows 中选取第一个子数据集,并在第 15 行从中抽取样本数据。由于我们使用的窗口大小为 6,因此第 15 行中的子数据集“window”由 6 个样本组成。 第一个子数据集包含样本 0、1、2、3、4、5 和 6。
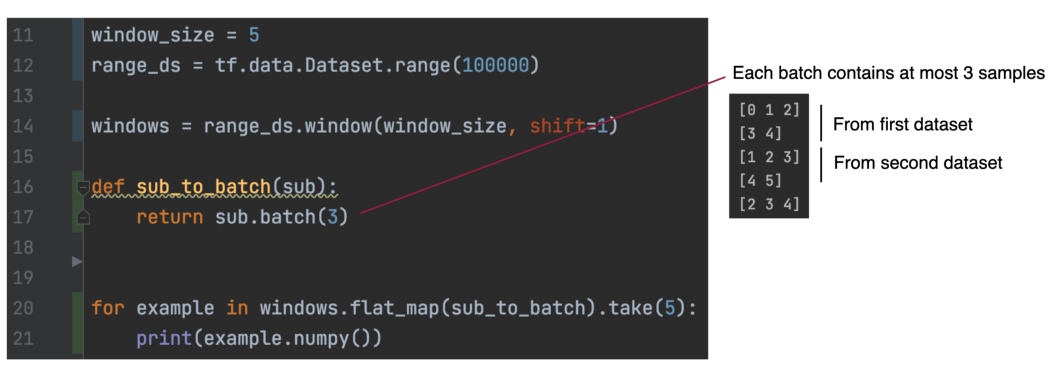
接下来,我们要演示使用windows来创建滑动数据。 flat_map 获取数据集(窗口)的数据集并将其展平为单个数据集。 新数据集将首先从 dataset1 输出批次。 一旦用完,它就会移动到 windows 中的下一个数据集。 在下面的第 18 行,我们从扁平化的数据集中收集了 5 批样本。 第一批样本来自第一个数据集,第二批样本来自第二个数据集。
但是在下面的第 17 行中,我们将子数据集配置为batch size大小仅为 3。 因此,每个子数据集可以产生 2 个batches,右侧的图表是使用展平数据集采样的前 5 个batches。 如果我们不希望最后batche小于 3,则在第 17 行设置 drop_remainder=True。
如下图所示,dataset.window 还允许我们控制采样数据时的stride和shift。 “Shift”表示在创建子数据集的每次迭代中窗口移动的输入元素的数量。 “Stride”表示滑动窗口(子数据集)中输入元素的步幅。
至此结束 |