在上一篇文章中,我们介绍了有关计算机视觉的 TensorFlow 编码示例。 现在,我们将专注于 NLP 分类和 BERT。 以下是示例列表,使用 2020 年 12 月发布的 TF 2.4.0 进行测试。这些示例源自 TensorFlow 教程。
IMDB 文件:使用数据集映射和嵌入进行情感分析 这个例子对 IMDB 电影评论进行情感分析——将它们分类为正面评论的 pos 和负面评论的 neg。
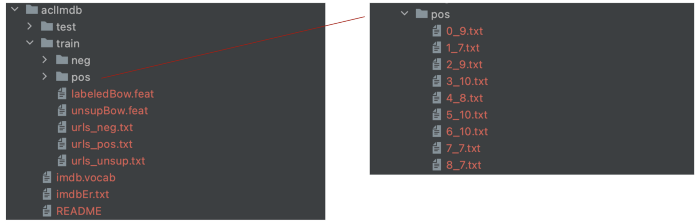
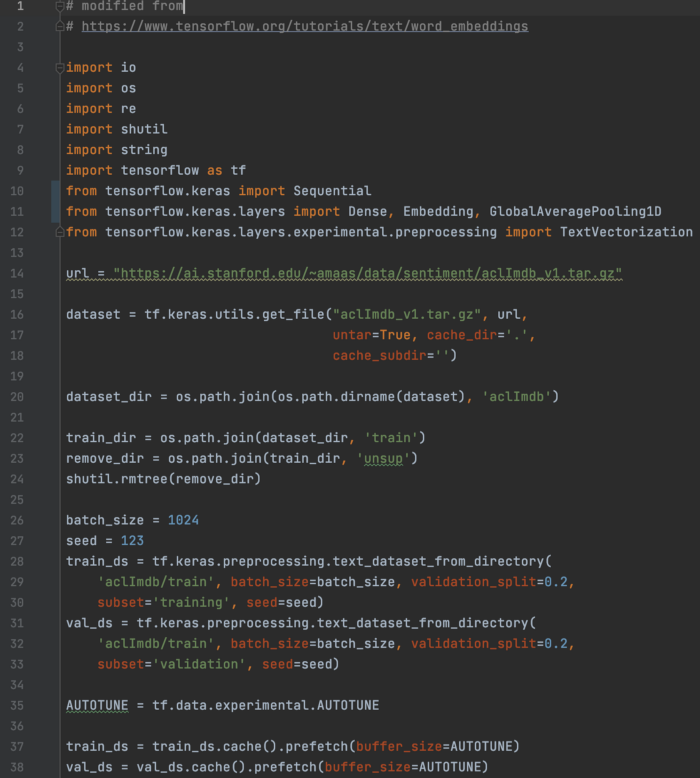
加载和准备 IMDB 数据文件:
删除不需要的目录后,数据目录变为:
使用来自多个目录的文件准备数据集(每个目录包含来自同一类的样本:pos 或 neg):
使用标准化和 TextVectorization 进行文本预处理(第 79-81 行):
在第 69 行,文本向量化层 (vectorize_layer) 将适应训练数据集的语料库来设置词汇表和单词索引。 因此,给定一个包含 10 个单词的标准化句子,它会生成一个由 10 个整数组成的序列。 所以“你在哪一边……”被转换成说 (79, 3, 4, 23, ...)。
优化数据集:
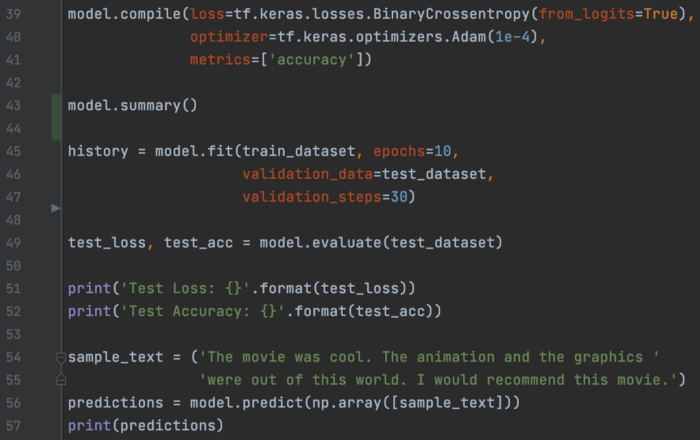
模型创建、训练和评估:
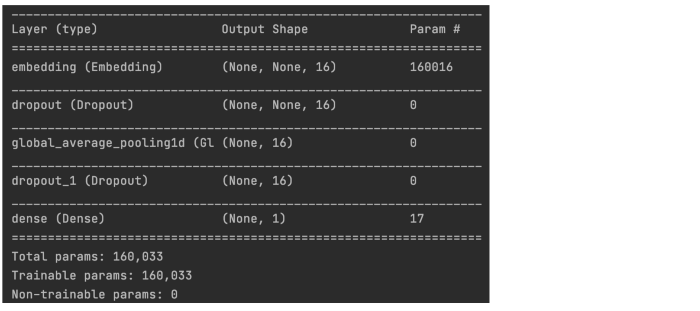
这是模型的摘要。
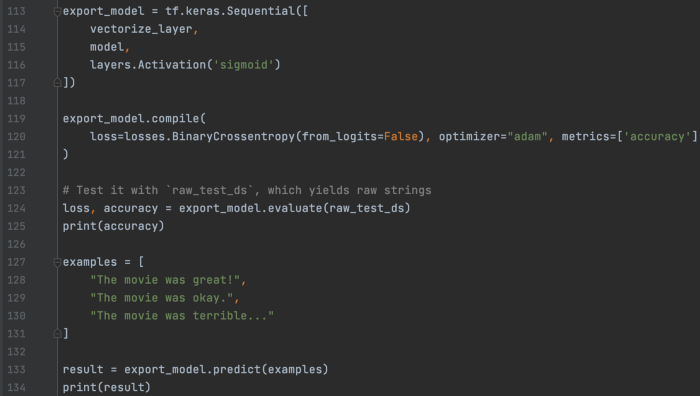
导出一个概率模型:
IMDB 文件:TensorBoard 和带有嵌入和数据预处理层的情感分析 在这个例子中,
首先,用于加载数据和准备数据集的样板代码。
接下来,我们创建 TextVectorization 层并使其适应训练数据集。
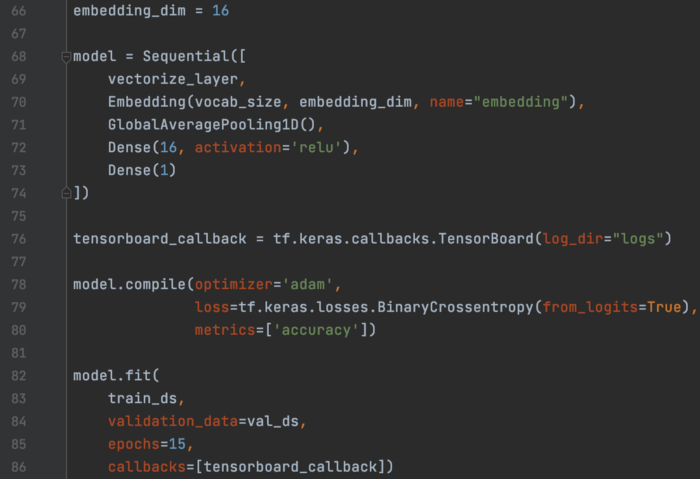
将 TextVectorization 层包含到模型中。 通过回调训练模型并记录 TensorBoard 信息。 我们稍后可以使用“tensorboard -logdir logs”(其中“logs”是第 76 行中的 TensorBoard 日志目录)访问此信息。
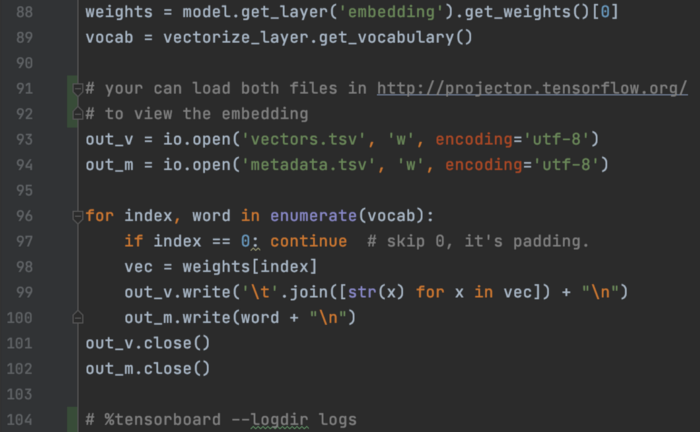
我们可以保存嵌入权重和词汇表。
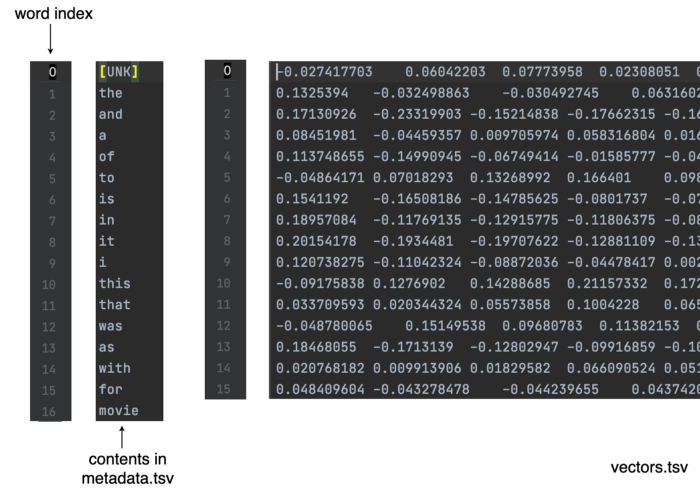
Metadata.tsv 包含词汇表——一行一个单词,vectors.tsv 包含每个单词的向量表示。
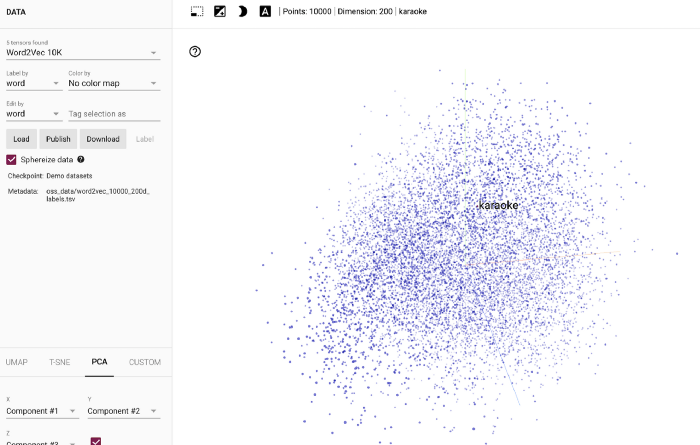
我们可以通过在下面的加载按钮中上传这两个文件来使用 projection.tensorflow.org 查看此嵌入信息。
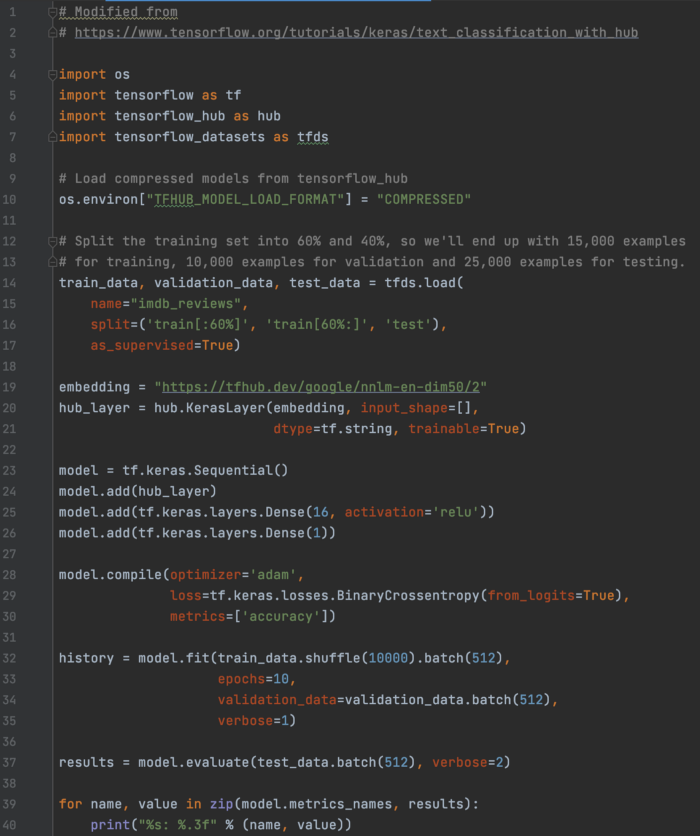
IMDB TF 数据集:使用预训练的 TF Hub 嵌入进行情感分析 在这个情感分析中:
一种常见的做法是使用 hub.KerasLayer(第 20 行)包装一个预训练的 TF Hub 模型。
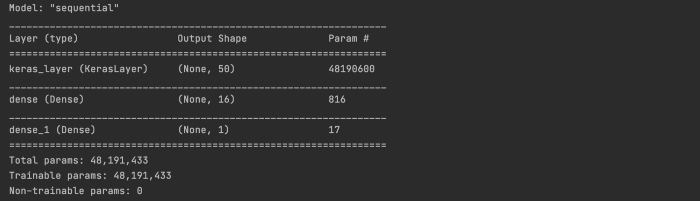
这是模型:
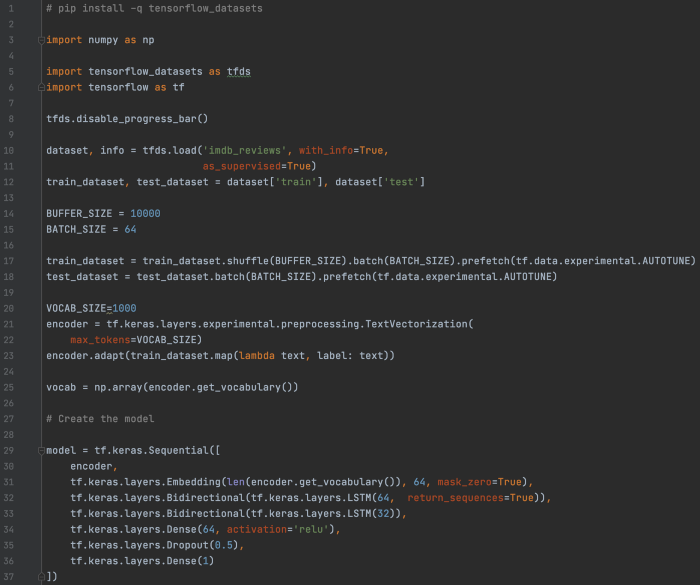
IMDB TF 数据集:使用双向 LSTM 进行情感分析 在这个例子中,
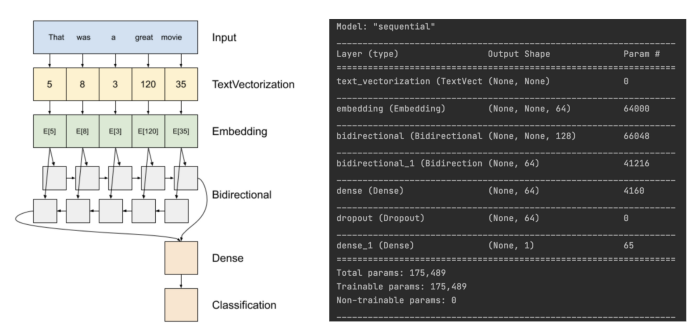
这是模型摘要。
然后,我们训练和评估模型。
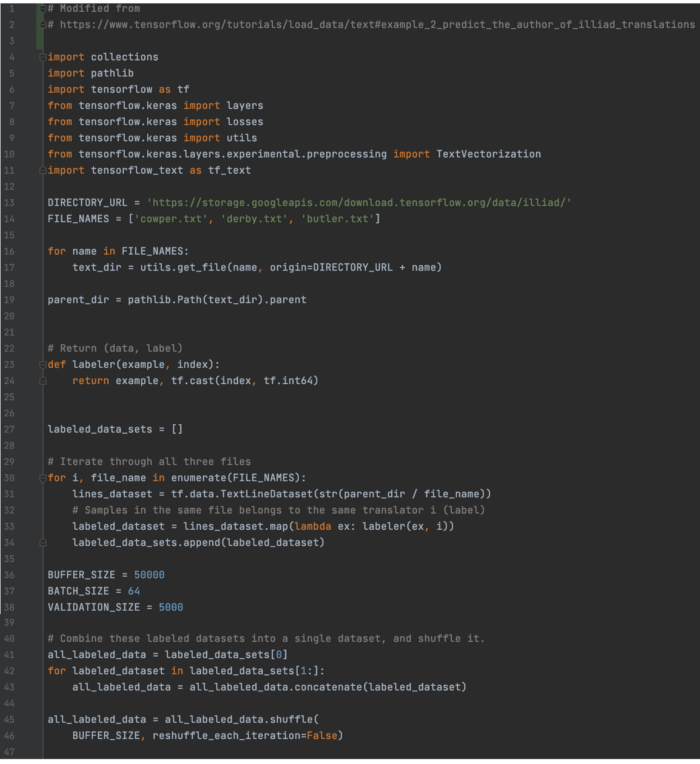
使用 tf.text、TextLineDataset 进行数据处理的 Illiad 文件分类(可选) 在这个例子中,我们预测Illiad翻译的作者。
样本来自三个文件。 每个文件都包含由同一作者完成的 Illiad 翻译。 这是我们为每个文件创建数据集的代码。 由于每个文件都来自同一个作者,我们给它的所有样本都赋予了相同的标签(第 33 行)。 然后,我们将数据集连接(合并)为一个并打乱样本。 新数据集 all_labeled_data 包含文本和标签。
此示例不使用 TextVectorization,而是用于更复杂的路由。 我们使用 tf_text API 从 all_labeled_data 创建了一个标记化数据集。 这个新数据集将文本转换为单词序列。
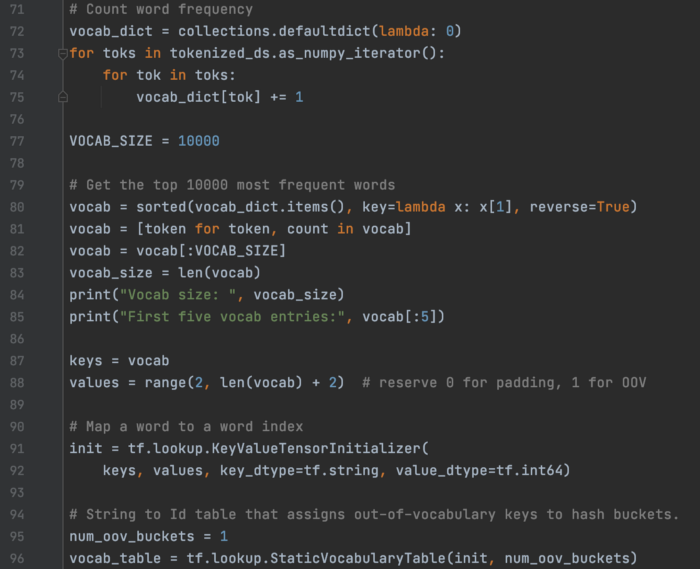
使用 TextVectorization,我们可以使用训练样本对其进行调整,以创建词汇表以及单词和整数索引之间的映射。 在这里,我们手动完成。 首先,我们找到 10,000 个最频繁出现的单词并创建映射(第 96 行中的 vocab_table)。
最后,我们创建将文本向量化为整数序列(每个单词一个整数)的数据集。
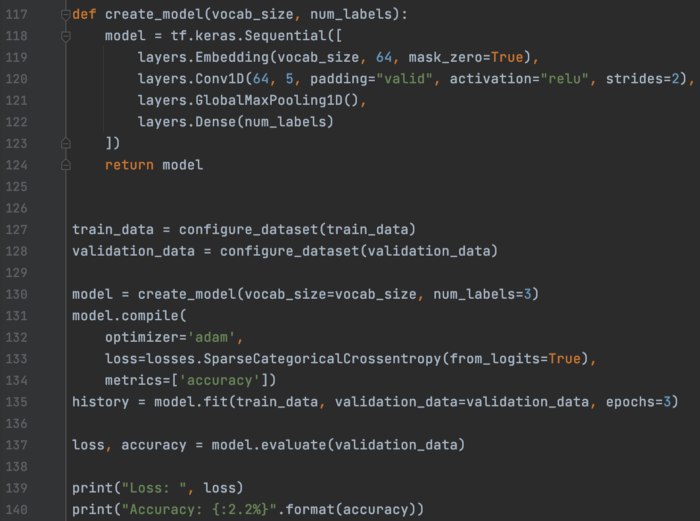
现在,我们建立一个模型,对其进行训练和评估。
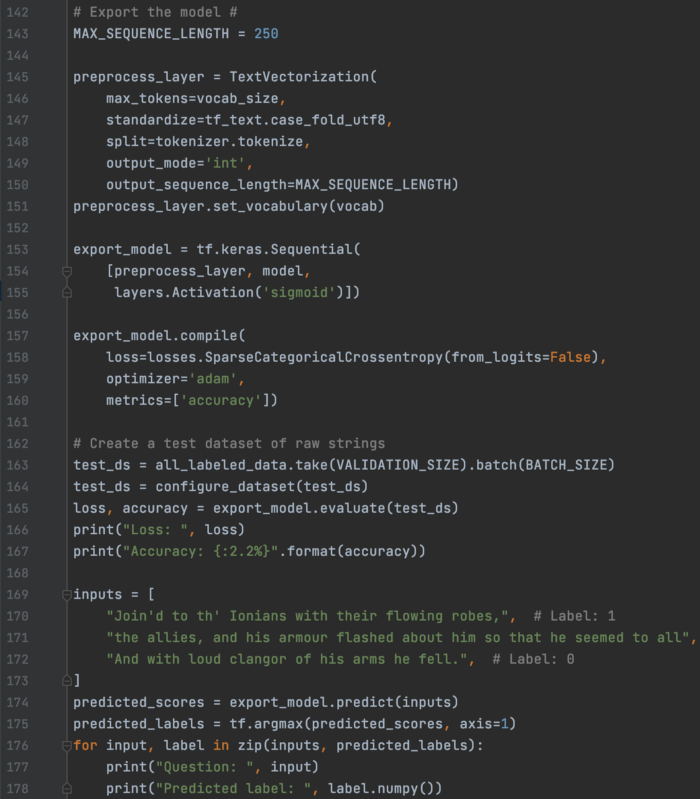
导出模型 现在,我们创建了一个导出模型,包括可用于生产推理的文本预处理。 该模型可以直接获取原始文本,无需额外的文本预处理代码。 我们将在复制数据预处理时使用 TextVectorization 层。 在第 142 到 148 行,它使用相同的标准化器和标记器,并适应我们之前创建的相同词汇表(包括映射)。 其余代码重建模型并进行预测。
所有源代码均源自或修改自 TensorFlow2 教程。 |