|
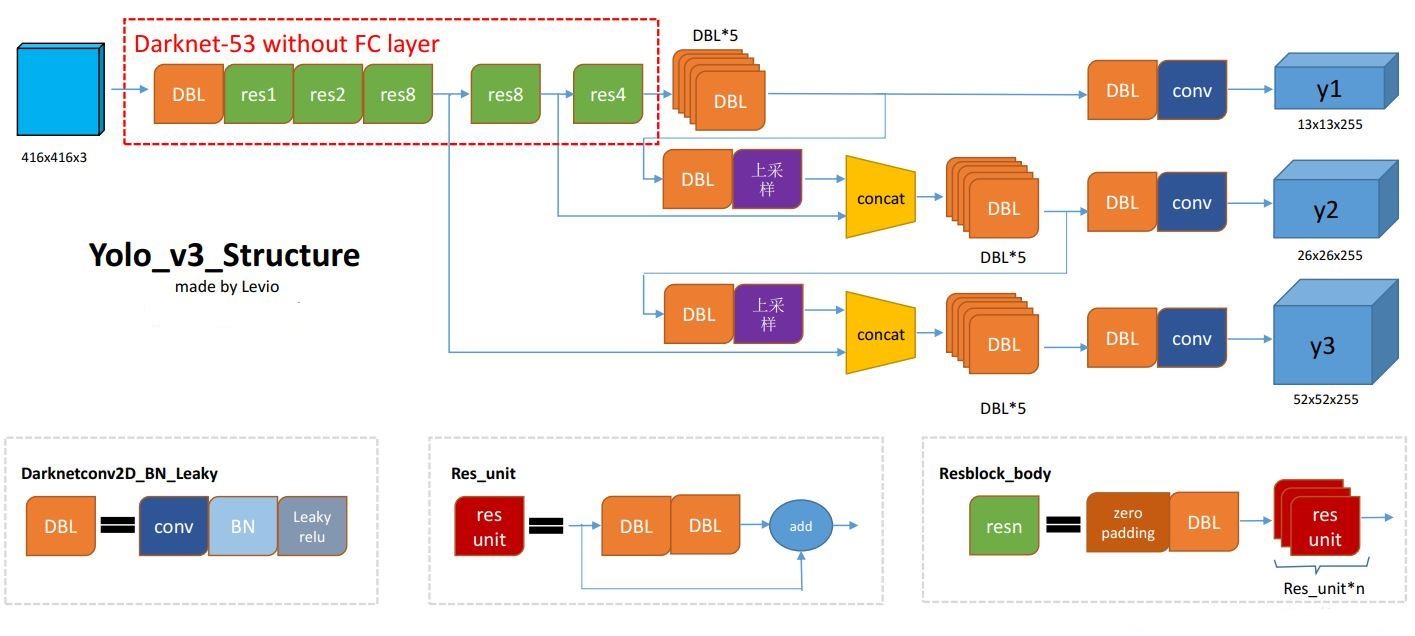
本文主要讲解YOLOv3的原理 1.架构 yolo系列从v1到v3网络是越来越快,精度越来越高,从v2开始作者引入和SSD一样anchor的概念,使得v2v3需要提前设置好anchor,这样才能使网络精度有所提升。 这里来看下网络的整体结构,如图:
上图是使用别人的图片,这里做个解释: 其中DBL:是conv+BN+Leaky的组合键, resn:n代表数字,有res1,res2, … ,res8等,res_block表示里含有多少个res_unit, concat:表示拼接,这里指的是,在图片不同大小的时候进行拼接,可以更好提取不同尺度时的图片信息,这里和add不同这里增加了维度信息。 这里如果是v1版本,直接使用最后全连接进行检测这样会将很多比较小的异物进行遗漏掉,并且框也不是很准确,在v3中,采用了使用不同的图片尺度进行提取特征。YOLO是一个完全卷积网络,它的最终输出是通过在feature map上应用1 x 1内核生成的。在YOLO v3中,检测是在网络中三个不同位置的三种不同大小的feature map上应用1 x 1的检测内核来完成的,这样可以使大的物体以及小的物体都可以进行比较好的进行提取。 2.backbone backbone部分是提取图片特征的部分,这里作者使用了darknet53,是借鉴res的结构部分。如图所示:
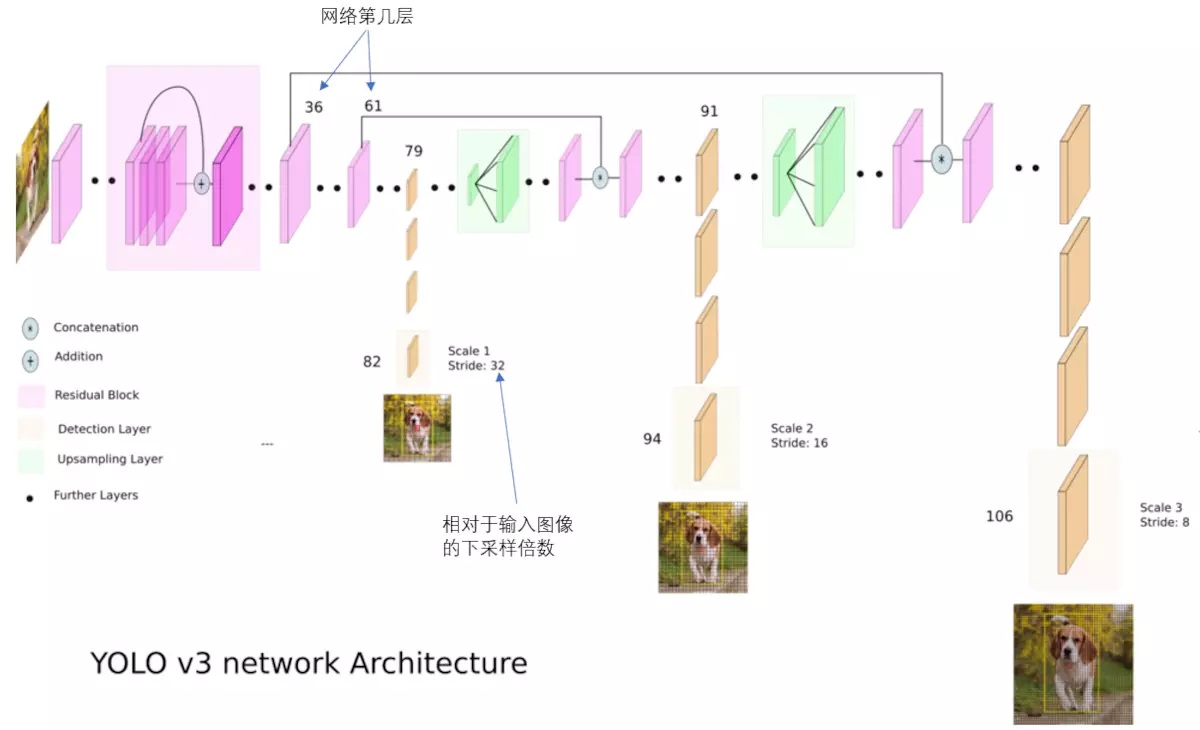
图片输入为412x412x3通过卷积图片为256x256x32,其中2,8,8,4是res部分;具体可以参考resnet部分。 对于darknet提取图片的特征用于检测具体如图所示:
由于需要检测小物体所以,作者采用了上采样,在上采样到和61层一样大时,90层和61层进行特征融合,这样就可以检测到更加精细的物体。同样经过几个卷积层后得到相对输入图像16倍下采样的特征图,这样就可以检测中等大小的物体。 同理在较小的物体上进行检测,还需要进行上采样,如图与36层进行特征融合,过几个卷积层后得到相对输入图像8倍下采样的特征图,这样就可以检测更小的物体。这也是YOLOv3比较好的原因之一了。 3.先验框 在v2中作者使用了先验框,这里先验框共有9个,分别为小物体三个,中物体三个,大物体三个。这里先验框的尺寸是根据k-means聚类得到的。v3中的先验框是根据coco数据集进行聚类得到的:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326) 在使用先验框上,是在最小特征图上使用较大的先验框,即在13x13特征图上使用(116x90),(156x198),(373x326),因为在小特征图上存在着交大的感受野,在26x26特征图上使用中等先验框,(30x61),(62x45),(59x119),最后在大特征图上使用小先验框(10x13),(16x30),(33x23),因为在大特征图上相对感受野交小。
下图为相对应的先验框,其中蓝色的为聚类的到的先验框,黄色为ground truth,红色是对象中心点所在的网格。
对于输出的结果如图所示:
红色代表预测到狗,输出的值如图,其中包括位置信息和类别信息以及相关概率。 4.输出 在输出对象类别时,使用了logistics而不是使用softmax函数,这样可以支持多标签对象。下图为输出的结构:
这里我们就可以直接计算出做了多少预测。对于416*416的图片来说,总共有13*13*3 + 26*26*3 + 52*52*3 = 10647 个预测。每一个预测的向量为(4+1+80)=85维。4代表的是边框坐标,边框的置信度为1,类别概率为80中的一个,这就是YOLOv3的相关原理。 |