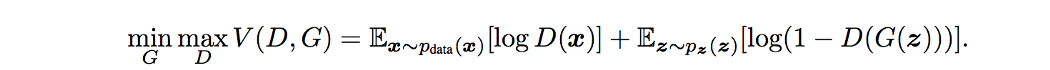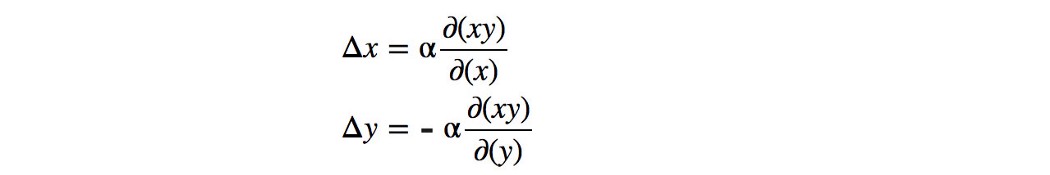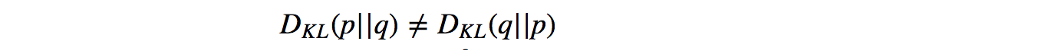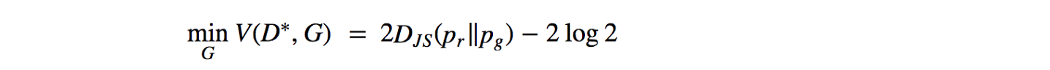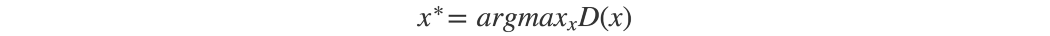|
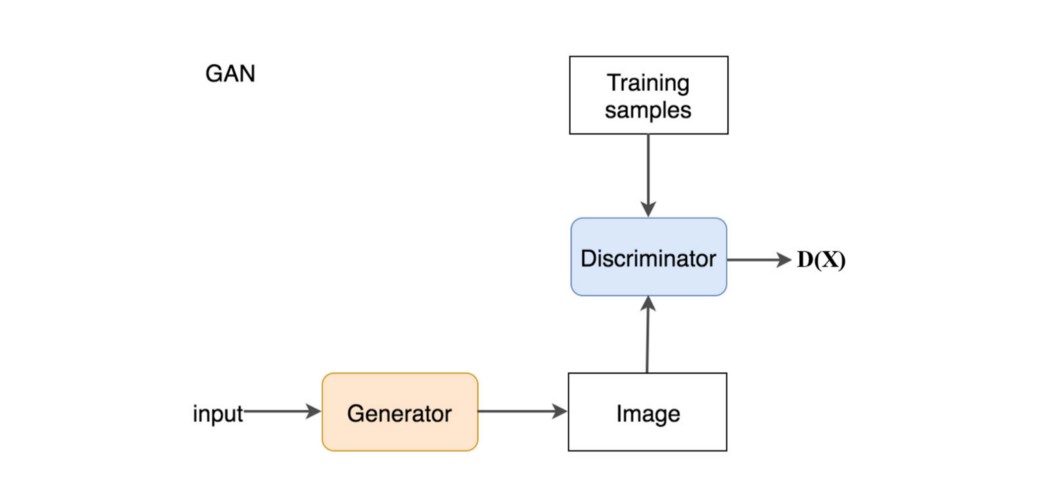
识别莫奈的画比画一幅画更容易。 与判别模型(处理数据)相比,生成模型(创建数据)被认为更难。 训练 GAN 也很困难。 本文是 GAN 系列的一部分,将介绍为什么训练很难。 通过研究,我们了解了一些推动许多研究人员方向的基本问题。 在研究这些问题之前,让我们快速回顾一下 GAN 的一些方程。 GAN GAN 使用正态或均匀分布对噪声 z 进行采样,并利用深度网络生成器 G 来创建图像 x (x=G(z))。
在 GAN 中,我们添加了一个鉴别器来区分鉴别器输入是真实的还是生成的。 它输出一个值 D(x) 来估计输入是真实的几率。
目标函数和梯度 GAN 被定义为具有以下目标函数的极小极大游戏。
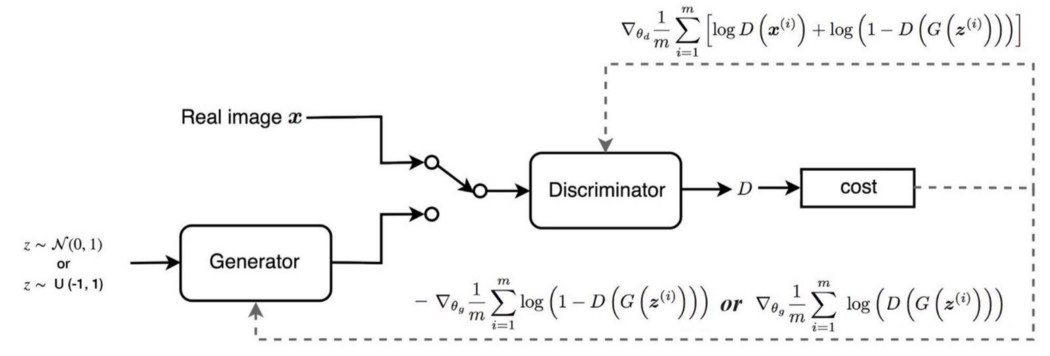
下图总结了如何使用相应的梯度训练判别器和生成器。
GAN 问题 许多 GAN 模型存在以下主要问题:
Mode 现实生活中的数据分布是多模态的。 例如,在 MNIST 中,从数字“0”到数字“9”有 10 种主要模式。 下面的示例由两个不同的 GAN 生成。 第一行产生所有 10 种模式,而第二行仅创建一种模式(数字“6”)。 当仅生成少数模式的数据时,此问题称为模式崩溃。
纳什均衡 GAN 基于零和非合作博弈。 简而言之,如果一个人赢了,另一个人就输了。 零和游戏也称为极小极大。 你的对手想要最大化它的行动,而你的行动是最小化它们。 在博弈论中,GAN 模型在判别器和生成器达到纳什均衡时收敛。 这是下面的极小极大方程的最佳点。
由于双方都想破坏对方,纳什均衡发生在一个玩家无论对手做什么都不会改变其行动的情况下。 考虑分别控制 x 和 y 值的两个玩家 A 和 B。 玩家 A 想要最大化 xy 的值,而 B 想要最小化它。
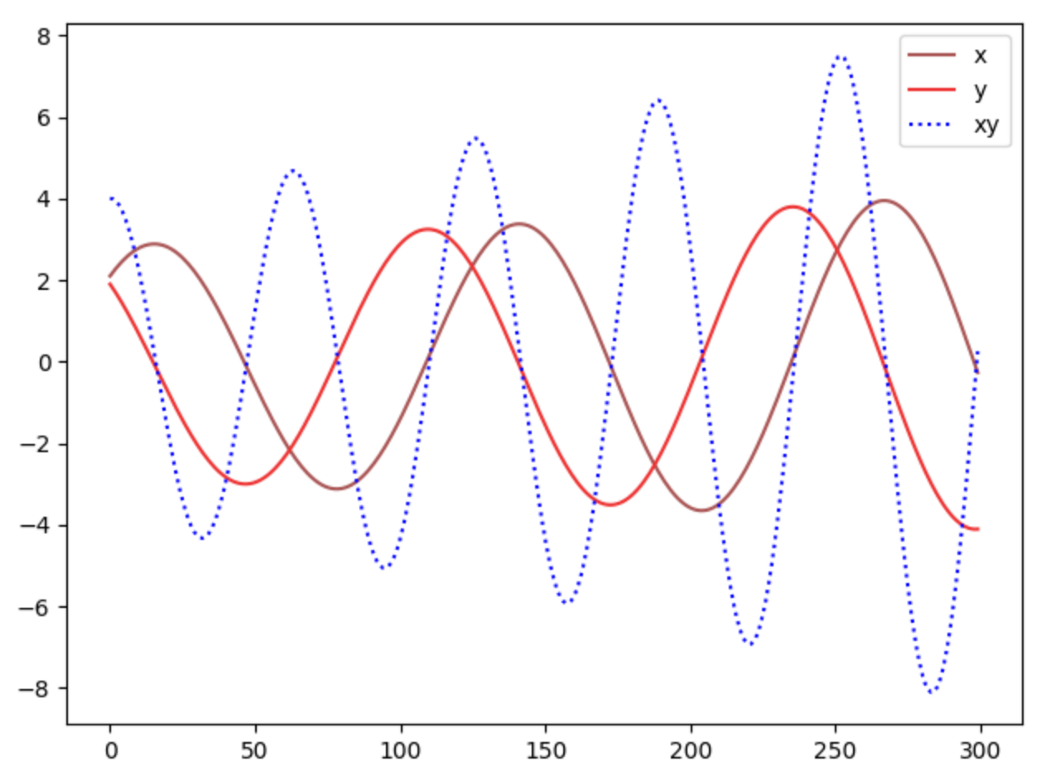
纳什均衡是 x=y=0。 这是唯一一个对手的行动无关紧要的状态。 这是唯一一种任何对手的行为都不会改变游戏结果的状态。 让我们看看我们是否可以使用梯度下降轻松找到纳什均衡。 我们根据值函数 V 的梯度更新参数 x 和 y。
其中α是学习率。 当我们针对训练迭代绘制 x、y 和 xy 时,我们看到我们的方案不会收敛。
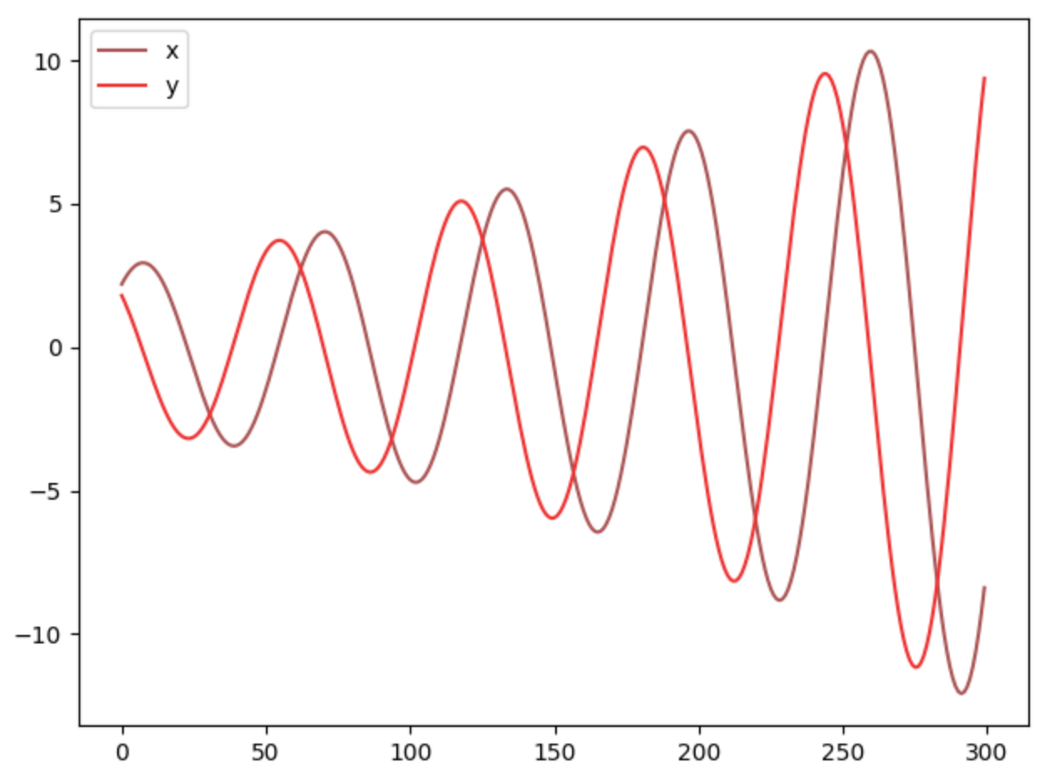
如果我们提高学习率或训练模型的时间更长,我们可以看到参数 x、y 不稳定且波动很大。
我们的示例很好地展示了某些cost函数不会与梯度下降收敛,特别是对于非凸游戏。 我们也可以直观地看待这个问题:你的对手总是反击你的行为,这使得模型更难收敛。 在极小极大游戏中,使用梯度下降可能无法收敛cost函数。 具有 KL-Divergence 的模型生成 为了理解 GAN 中的收敛问题,我们将首先研究 KL-divergence 和 JS-divergence。 在 GAN 之前,许多生成模型会创建一个模型 θ 来最大化最大似然估计 MLE。 即找到最适合训练数据的最佳模型参数。
这与最小化 KL-Divergence KL(p,q)(证明)相同,后者测量概率分布 q(估计分布)如何与预期概率分布 p(现实生活中的分布)发散。
KL-Divergence不对称。
对于 p(x) → 0 的区域,KL(x) 下降到 0。例如,在右下图中,红色曲线对应于 D(p, q)。 当 p 接近 0 的 x>2 时,它下降到零。
这意味着什么? KL-divergence DL(p, q) 如果生成器遗漏了某些图像模式,则会对其进行惩罚:当 p(x) > 0 但 q(x) → 0 时,惩罚很高。不过,有些图像没有 看起来真实。 当 p(x) → 0 但 q(x)>0 时,惩罚很低。 (质量较差但种类更多样化) 另一方面,如果图像看起来不真实,则反向 KL-divergence DL(q, p) 会惩罚生成器:如果 p(x) → 0 但 q(x) > 0,则会受到高惩罚。但它探索的多样性较少: 如果 q(x) → 0 但 p(x) > 0,则惩罚较低。(质量更好但样本较少) 一些生成模型(GAN 除外)使用 MLE(又名 KL-divergence)来创建模型。 最初认为 KL-divergence 会导致图像质量下降(图像模糊)。 但请注意,一些实证实验可能对这一说法提出异议。 JS-Divergence JS-divergence 定义为:
JS-divergence 是对称的。 与 KL-divergence 不同,它会严重惩罚糟糕的图像。 (当 p(x)→ 0 且 q(x) > 0)在 GAN 中,如果判别器是最优的(在区分图像方面表现良好),则生成器的目标函数变为(证明):
因此优化生成器模型被视为优化 JS-divergence。 在实验中,与使用 KL-divergence 的其他生成模型相比,GAN 生成了更好的图片。 按照上一节的逻辑,早期研究推测优化 JS-divergence,而不是 KL-divergence,可以创建更好但更少多样性的图像。 然而,一些研究人员已经撤回了这些说法,因为使用 MLE 的 GAN 实验产生了相似的图像质量,但仍然存在图像多样性问题。 但是已经在研究 JS-Divergence 在 GAN 训练中的弱点方面做出了重大努力。 无论辩论如何,这些作品都很重要。 因此,接下来我们将深入挖掘 JS-divergence 的问题。 JS-Divergence 中的梯度消失 当判别器是最优的时,生成器的目标函数是:
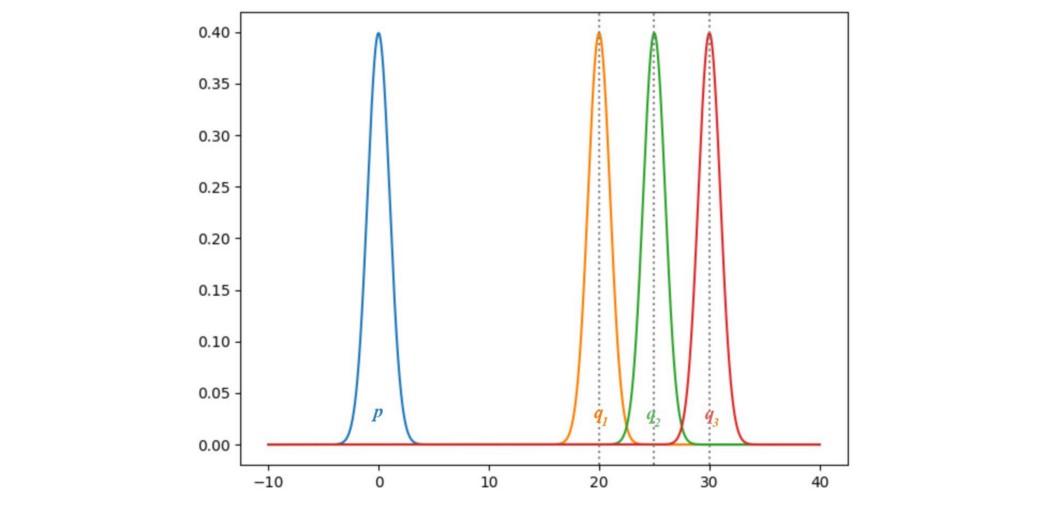
当生成器图像的数据分布 q 与真实图像的ground truth p 不匹配时,JS-divergence梯度会发生什么情况。 让我们考虑一个例子,其中 p 和 q 是高斯分布且 p 的均值为零。 让我们用不同的方法考虑 q 来研究 JS(p, q) 的梯度。
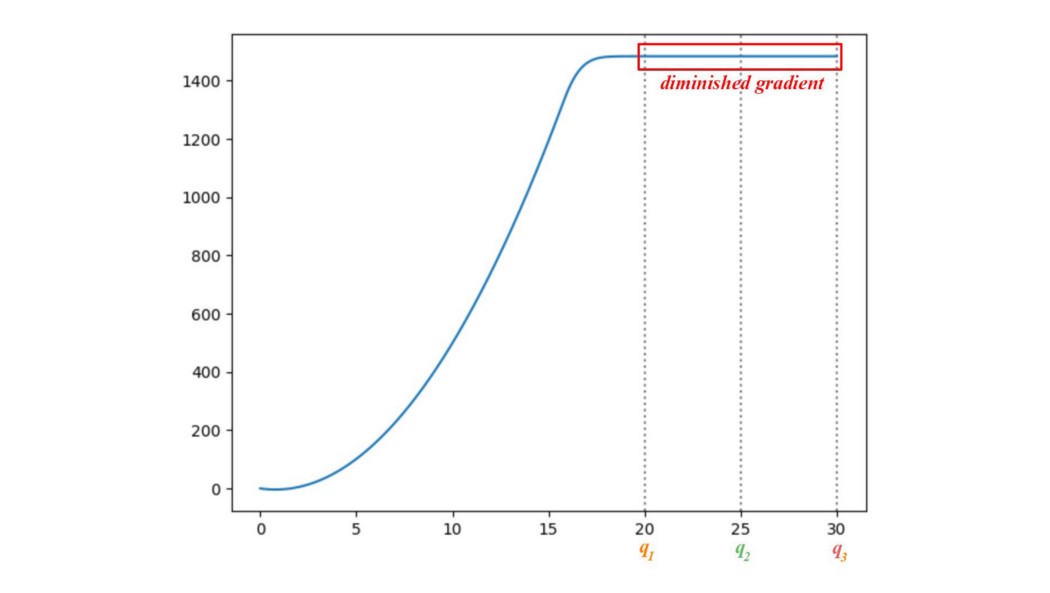
在这里,我们绘制了 p 和 q 之间的 JS-divergence JS(p, q),q 的平均值在 0 到 30 之间。如下所示,JS-divergence 的梯度从 q1 到 q3 消失。 当这些区域的cost饱和时,GAN 生成器的学习速度会非常慢甚至什么都没有。 特别是在早期训练中,p 和 q 非常不同,生成器学习非常慢。
不稳定的梯度 由于梯度消失,原始 GAN 论文提出了一种替代cost函数来解决梯度消失问题。
根据 Arjovsky 的另一篇研究论文,相应的梯度是:
它包括一个反向 KL-divergence 术语,Arjovsky 用它来解释为什么 GAN 与基于 KL-divergence 的生成模型相比具有更高质量但更少多样性的图像。 但同样的分析声称梯度会波动并导致模型不稳定。 为了说明这一点,Arjovsky 冻结了生成器并不断训练判别器。 生成器的梯度随着变体的变大而开始增加。
上面的实验不是我们训练 GAN 的方式。 然而,在数学上,Arjovsky 表明第一个 GAN 生成器的目标函数具有消失的梯度,而替代cost函数具有波动的梯度,导致模型不稳定。 自从最初的 GAN 论文以来,寻找新的cost函数就出现了很高的热度,例如 LSGAN、WGAN、WGAN-GP、BEGAN 等……一些方法基于新的数学模型,而另一些则基于实验支持的直觉。 目标是找到具有更平滑和非消失梯度的cost函数。 然而,2017 年 Google Brain 的一篇论文“Are GANs Created Equal?” 声称 Finally, we did not find evidence that any of the tested algorithms consistently outperforms the original one. 训练 GAN 很容易失败。 与其在一开始就尝试许多cost函数,不如先调试设计和代码。 接下来努力调整超参数,因为 GAN 模型对它们很敏感。 在随机尝试cost函数之前执行此操作。 为什么模式在 GAN 中崩溃? 模式崩溃是 GAN 中最难解决的问题之一。 完全崩溃并不常见,但经常发生部分崩溃。 下面具有相同下划线颜色的图像看起来相似,并且模式开始崩溃。
让我们看看它是如何发生的。 GAN 生成器的目标是创建最能欺骗鉴别器 D 的图像。
但是让我们考虑一种极端情况,即 G 在没有更新 D 的情况下进行了广泛的训练。生成的图像将收敛以找到最能愚弄 D 的最佳图像 x*,从鉴别器的角度来看,这是最真实的图像。 在这个极端情况下,x* 将独立于 z。
这是个不好的事情。 模式折叠到一个点。 与 z 相关的梯度接近于零。
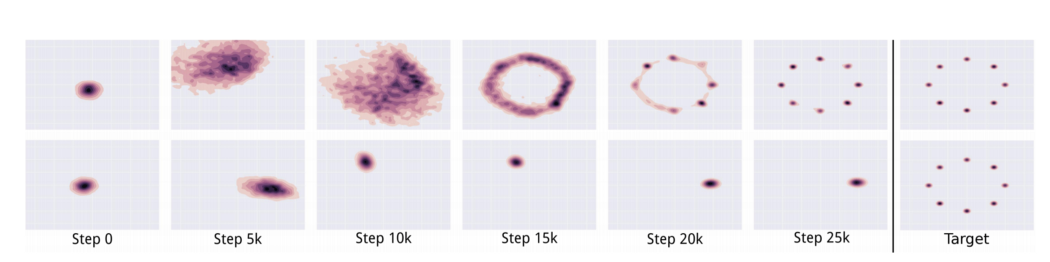
当我们在鉴别器中重新开始训练时,检测生成图像的最有效方法是检测这种单一模式。 由于生成器已经对 z 的影响不敏感,来自鉴别器的梯度可能会将单点推到下一个最易受攻击的模式。 这并不难找到。 生成器在训练中产生了如此不平衡的模式,以至于它降低了检测其他模式的能力。 现在,这两个网络都过度拟合以利用短期对手的弱点。 这变成了猫捉老鼠的游戏,模型不会收敛。 在下图中,Unroll GAN 设法生成所有 8 种预期模式的数据。 第二行显示了另一个 GAN,当判别器赶上时,该模式崩溃并转到另一个模式。
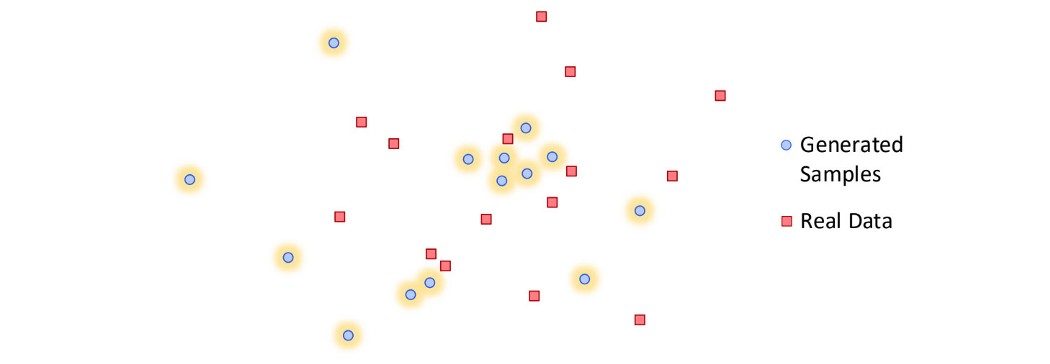
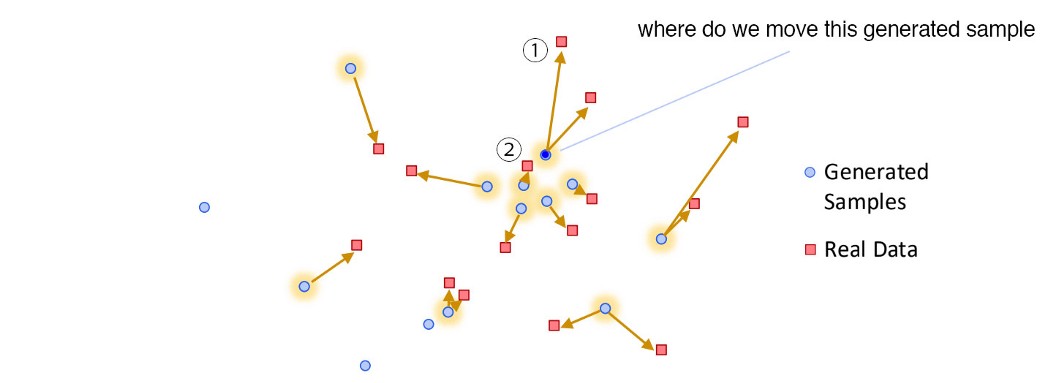
在训练期间,鉴别器不断更新以检测对手。 因此,生成器不太可能过度拟合。 在实践中,我们对模式崩溃的理解仍然有限。 我们上面的直观解释可能过于简单化了。 通过经验实验开发和验证缓解方法。 然而,GAN 训练仍然是一个启发式过程。 部分塌陷仍然很常见。 但模式崩溃并不全是坏消息。 在使用 GAN 进行风格迁移时,我们很乐意将一张图像转换为一张好的图像,而不是找到所有变体。 实际上,部分模式崩溃的专业化有时会创建更高质量的图像。 但模式崩溃仍然是 GAN 需要解决的最重要问题之一。 隐式最大似然估计 (IMLE) 有一篇解释和解决模式崩溃问题的研究论文。 让我们考虑下面的红色方块是真实数据,蓝色方块是生成的样本。
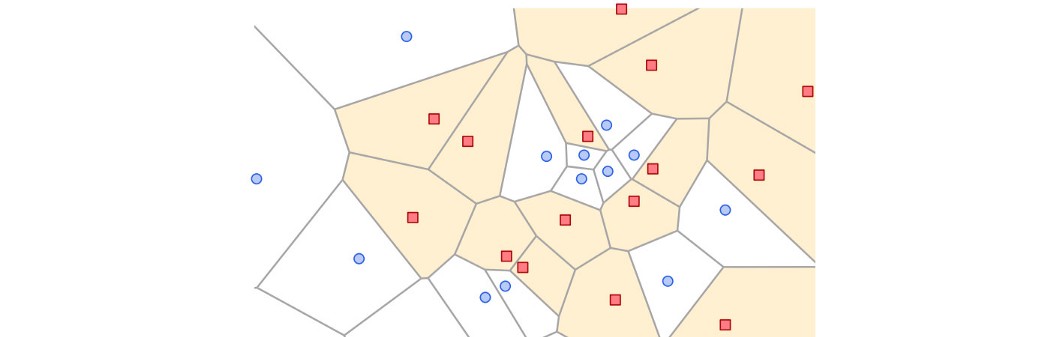
GAN 鉴别器创建黄色区域以区分真实数据和生成数据。
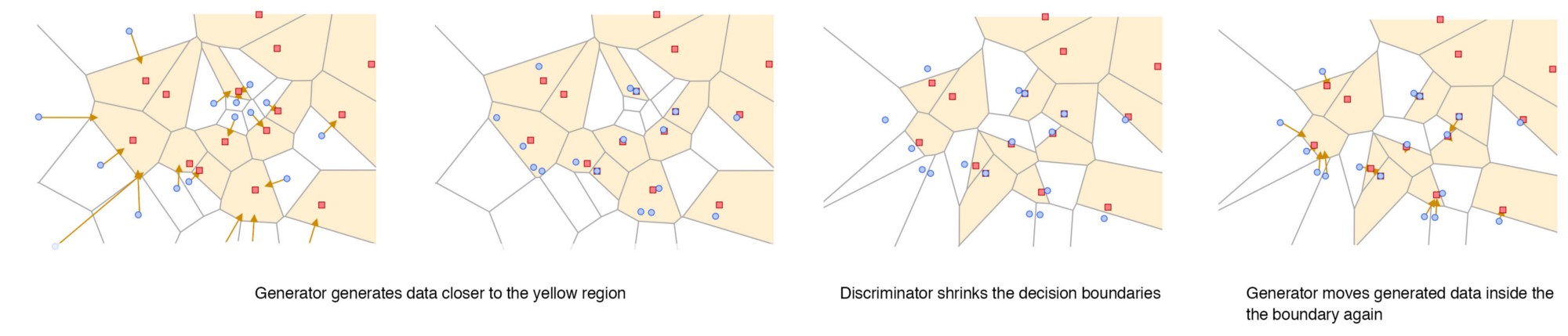
在训练过程中,生成器将生成数据以将生成的样本移向决策边界,而判别器将进一步缩小边界。
但是生成器不能保证它会生成覆盖过程中所有模式的样本。 如示例所示,某些模式可以在过程中被忽略并且无法恢复。
IMLE 以相反的方式翻转机制。 在 GAN 中,我们将生成的样本移向最近的边界。 例如,我们将下面的蓝点移向②。 但是在 IMLE 中,对于每一个真实数据,我们都会问什么是 closet 生成的样本。 所以我们训练模型将蓝点移动到①。
IMLE 不是 GAN 模型。 所以我们在这里不再赘述。 超参数和训练 如果没有良好的超参数,任何cost函数都无法工作,并且调整它们需要时间和很大的耐心。 新的cost函数可能会引入具有敏感性能的超参数。 超参数调优需要耐心。 如果不花时间进行超参数调整,任何cost函数都不会起作用。 鉴别器和生成器之间的平衡 不收敛和模式崩溃通常被解释为鉴别器和生成器之间的不平衡。显而易见的解决方案是平衡他们的训练以避免过度拟合。然而,取得的进展很少,但这并不是因为缺乏尝试。一些研究人员认为,这不是一个可行或理想的目标,因为一个好的鉴别器会给出好的反馈。因此,一些注意力转移到了具有非消失梯度的cost函数上。 cost与画面质量 在判别模型中,损失衡量预测的准确性,我们用它来监控训练的进度。然而,GAN 的损失衡量了我们与对手相比的表现。通常,生成器cost会增加,但图像质量实际上正在提高。我们回退到手动检查生成的图像以验证进度。这使得模型比较更难,从而导致难以在一次运行中选择最佳模型。它还使调整过程复杂化。 |