|
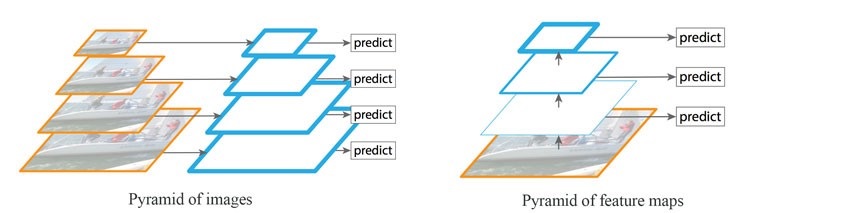
在不同的尺度上检测物体具有一定难度,特别是对于小物体来说更是如此。我们可以在不同的尺度上使用同一图像的金字塔来检测物体(下面的左图)。然而,处理多尺度图像时,内存需求太高,无法同时进行端到端的训练。因此,当速度不是很重要时,我们只能在推理中使用它来尽可能地提高准确性,尤其是在比赛中。或者,我们创建一个特征金字塔,并将它们用于物体检测(右图)。然而,特征映射更接近于由低层次结构组成的图像层,而这些结构对于精确的目标检测并不有效。
数据流
SSD从多个特征映射中进行检测。但是,没有为目标检测选择底层。它们具有很高的分辨率,但语义值不足以证明它的使用是正确的,因为速度慢是很重要的。因此,SSD只使用上层进行检测,因此对小型对象的性能要差得多。
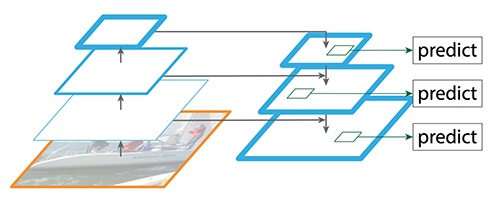
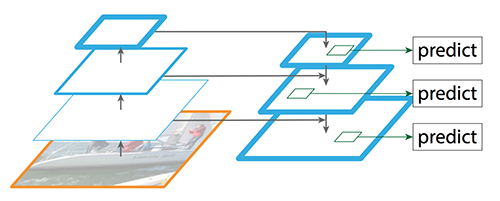
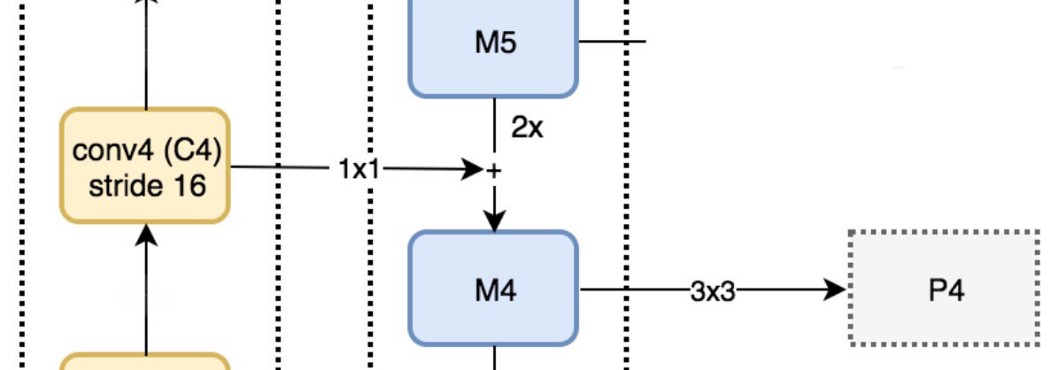
Reconstruct spatial resolution in the top-down pathway. 虽然重构层具有较强的语义性,但经过所有的下采样和上采样后,目标的位置并不精确。我们在重建层和对应的特征图之间添加横向连接,以帮助检测器更好地预测位置。它还起到跳过连接的作用,使训练更容易(类似于ResNet所做的工作)。
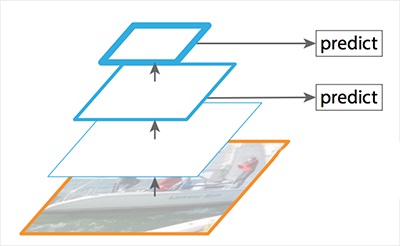
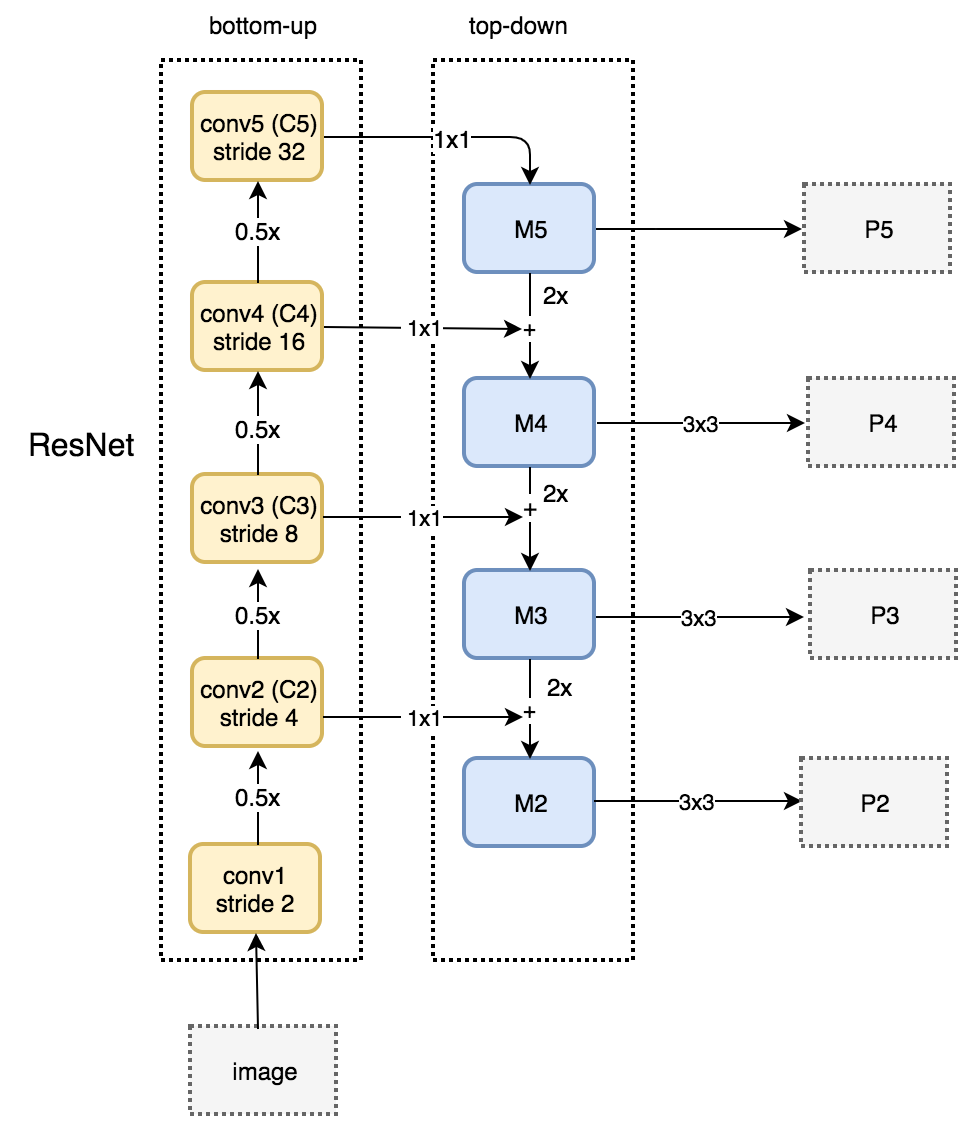
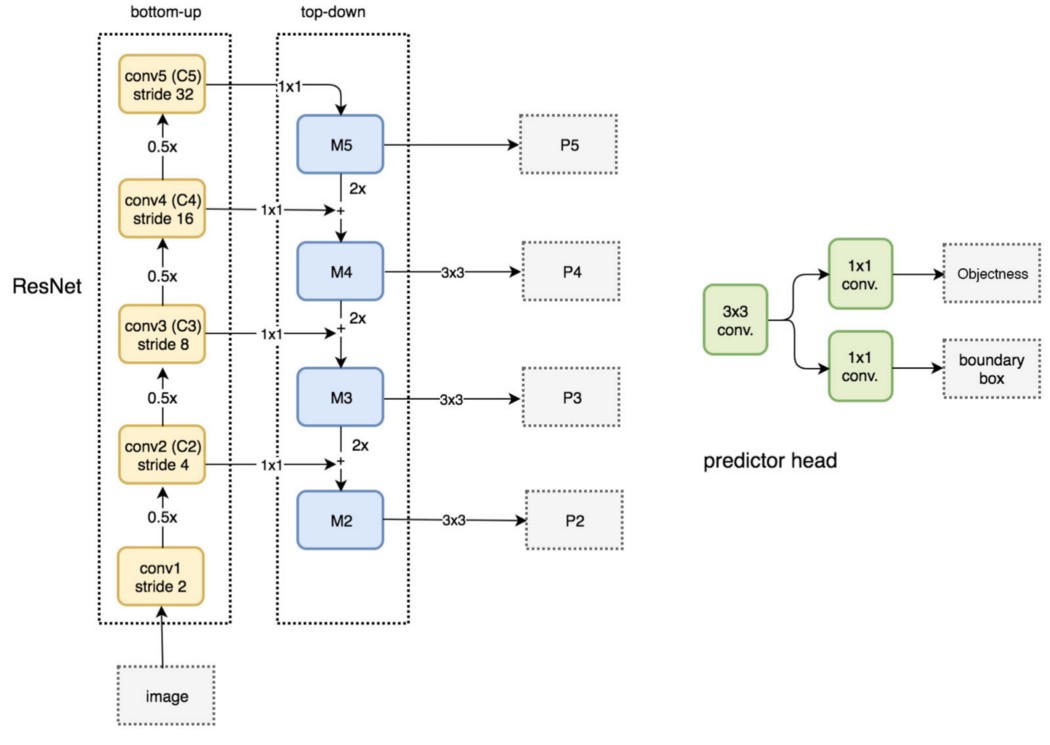
自下而上路径 自下而上的路径是使用ResNet构建自下而上的路径.它由许多卷积模(i=1~5)组成,每个卷积模都有许多卷积层。当我们向上移动时,空间维数减少了1/2(即步幅的两倍)。每个卷积模块的输出被标记为Ci,并在自顶向下的路径中使用。
自上而下路径 我们采用1×1卷积将C5通道深度降至256-d以产生M5。这将成为用于对象预测的第一个特征映射层。 当沿着自顶向下的路径走时,使用上采样,用2对前一层进行上采样。我们再次将1×1卷积应用于自下而上路径中相应的特征映射.然后我们按元素添加它们。我们将3×3卷积应用于所有合并层。当与上采样层合并时,该滤波器降低了重叠效应。
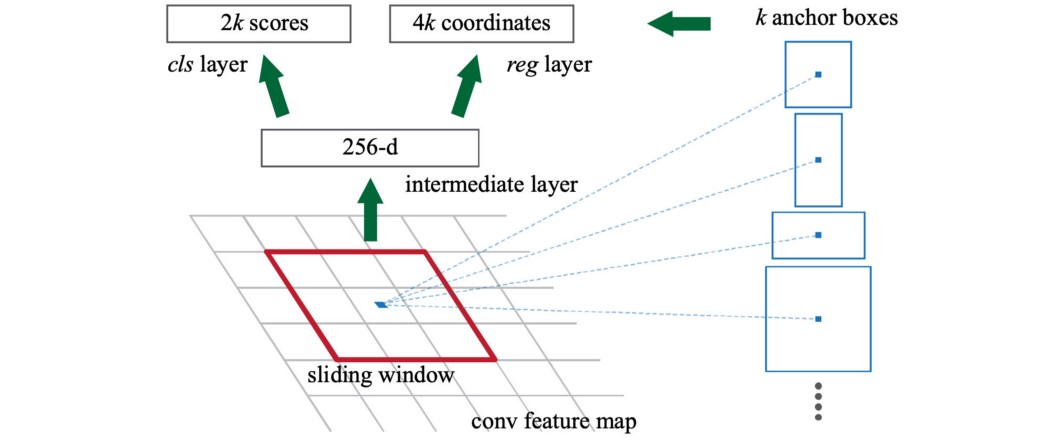
带RPN的FPN(Region Proposal Network) FPN本身并不是一个目标检测器。它是一个与目标检测器一起工作的特征提取器 FPN提取特征映射,然后输入检测器,对于RPN来说,用于目标检测。RPN在特征映射上应用一个滑动窗口,对每个位置的对象(有无对象)和对象边界框进行预测。
在FPN框架下,对于每个尺度级(如P4),在特征映射上采用3×3卷积,然后分别进行1×1卷积,用于物体预测和边界框回归。这3×3和1×1卷积层称为RPN头。同样的头适用于所有不同比例的特征图。
具有fast R-CNN或faster R-CNN的FPN 让我们快速地看看下面的fast R-CNN和faster R-CNN的数据流。它使用一个特征图层来创建ROIs。我们使用ROIs和特征映射层来创建特征块,以输入ROI池。
在FPN中,我们生成一个特征映射金字塔。我们应用RPN(在上一节中描述)来生成ROI。根据ROI的大小,在最合适的尺度上选择特征映射层来提取特征块。
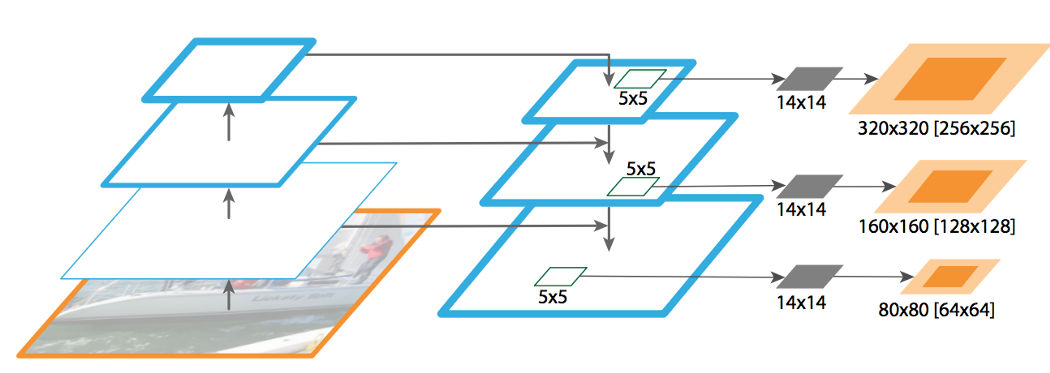
分割 就像MASK R-CNN一样,FPN也擅长于提取用于图像分割的mask.使用MLP,在特征映射上滑动一个5×5窗口,生成一个维数为14×14的物体块。稍后,我们以不同的比例合并掩码,形成最终的掩码预测。
结果 在RPN中放置FPN将AR(average recall:获取目标的能力)提高到56.3,比RPN基线提高8.0点。小对象的性能提高了12.9个百分点。
基于fpn的faster R-cnn在单个NVIDIA M40 GPU上实现了每幅图像0.148秒的推理时间,而单尺度的ResNet-50基线运行在0.32秒。下面是使用faster R-CNN的FPN的基线比较.(FPN为FPN中的这些额外层引入了较小的额外成本,但在FPN实现中有一个较轻的权重头。)
以下是从实验数据中吸取的一些教训。
|