|
在本文中,我们将讨论基于区域的object detectors,包括Fast R-CNN、FasterR-CNN、R-FCN和FPN。 1.滑动窗检测器 自AlexNet赢得2012年ILSVRC的挑战以来,CNN的分类一直占据着主导地位。一种用于目标检测的蛮力方法是从左、右滑动窗口,并从上到下使用分类识别对象。为了在不同的观察距离上检测不同的对象类型,我们使用不同大小和纵横比的窗口。
下面是伪代码。我们创建了许多窗口来检测不同位置的不同对象形状。要提高性能,一个明显的解决方案是减少窗口的数量。 我们使用区域提议方法来创建感兴趣区域(ROIS)来检测目标,而不是蛮力方法。在选择搜索(selective search)中,我们从每个像素作为自己的组开始。接下来,我们计算每个组的纹理,并将最接近的两个纹理组合起来。但是,为了避免在吞食其他区域时出现单一区域,我们更倾向于先将较小的群体分组。我们继续合并各地区,直到一切都合并在一起。在下面的第一行中,我们展示了如何增长区域,第二行中的蓝色矩形显示了在合并过程中生成的所有可能的ROIs。
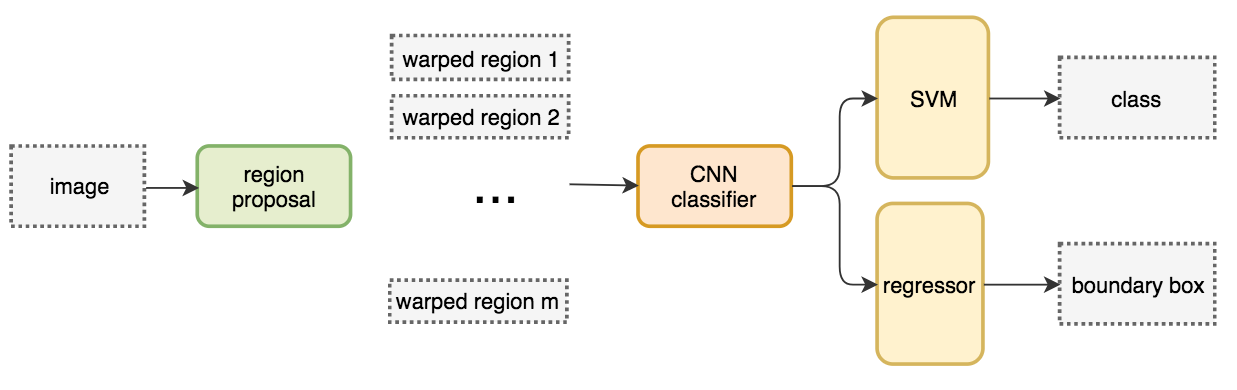
R-CNN利用一种区域提案方法创建了大约2000 Rois(regions of interest)。这些区域被扭曲成固定大小的图像,并分别输入CNN网络。然后是完全连接的层,以分类对象和细化边界框。
使用更少但质量更高的ROIS,R-CNN运行速度更快,比滑动窗口更精确. 4.Boundary box regressor 区域建议方法计算量大。为了加快这一过程,我们通常选择一个比较便宜的区域建议方法来创建ROIS,然后是一个线性回归器(使用完全连接的层)来进一步细化边界框。
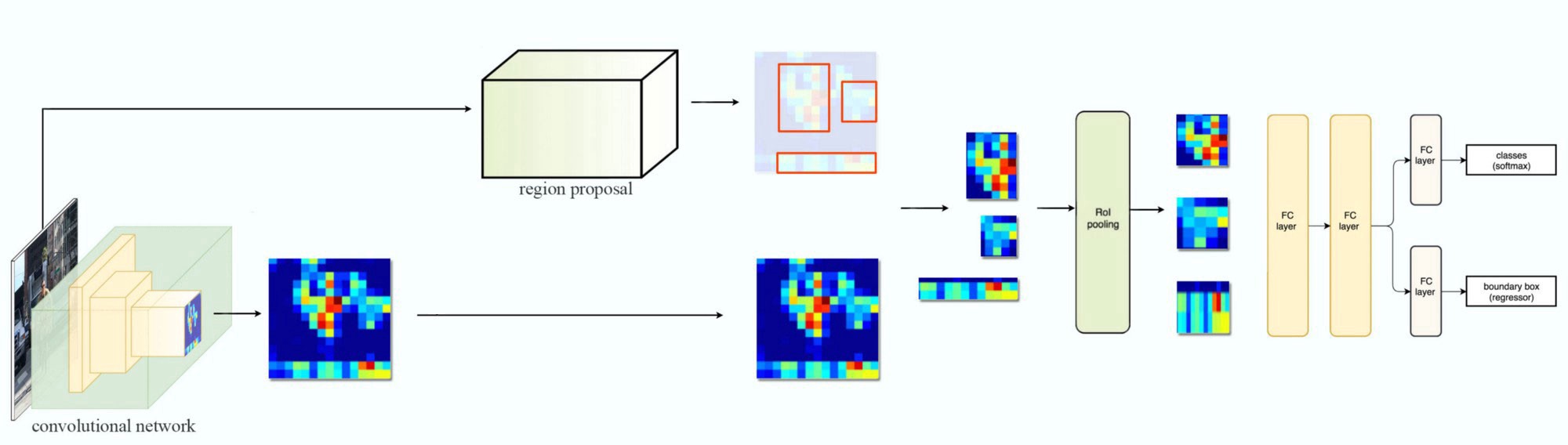
5.Fast R-CNN R-CNN需要许多proposals才能准确,而且许多区域相互重叠。R-CNN在训练和推理方面也比较慢.如果我们有2,000项proposals,每一项都由CNN单独处理,即我们对不同的ROI重复2,000次特征提取。 我们使用一个特征提取器(CNN)来首先提取整个图像的特征,而不是从零开始提取每个图像小区域的特征。我们还使用外部区域建议方法,如选择性搜索,创建ROIS,该方法随后与相应的特征映射相结合,形成用于对象检测的小区域。我们使用ROI池将小区域扭曲到固定大小,并将它们提供给完全连接的层进行分类和定位(检测对象的位置)。通过不重复的特征提取,快速R-CNN大大缩短了处理时间.
以下是网络流程图:
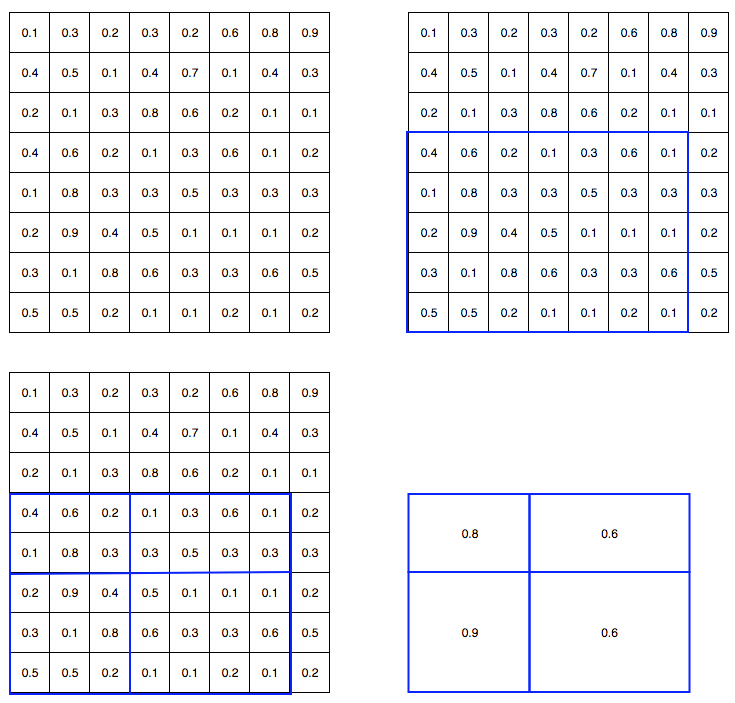
在下面的伪代码中,代价大的特征提取从for-循环中移出,这是一个显著的速度改进,因为它是对所有2000 rois执行的。快速R-CNN比R-CNN训练快10倍,推理速度快150倍。 6.ROI Pooling 因为FastR-CNN使用ROI pooling层,所以我们应用ROI池将可变大小的ROIS扭曲成一个预定义的大小形状。 让我们简化讨论,将8×8特征映射转换为预定义的2×2形状。
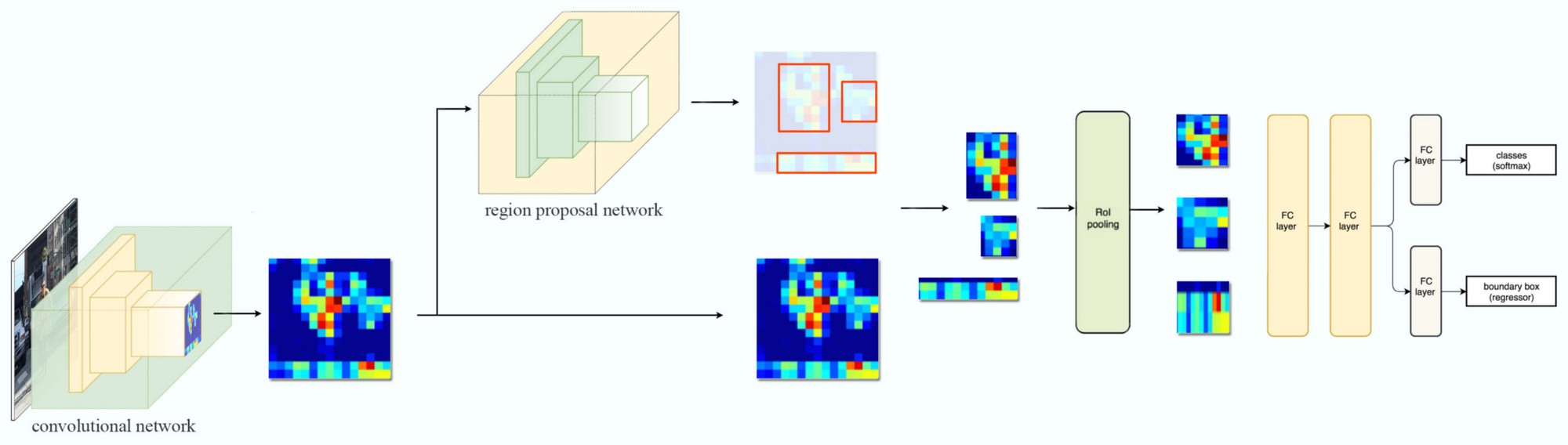
因此,我们得到了一个2×2特征区域,可以输入到分类器和盒回归器中。 7.Faster R-CNN Faster R-CNN依赖于外部区域建议方法,如选择性搜索。然而,这些算法运行在CPU上,而且速度很慢。在测试中,Fast R-CNN需要2.3秒才能做出预测,其中2秒用于生成2000 Rois.
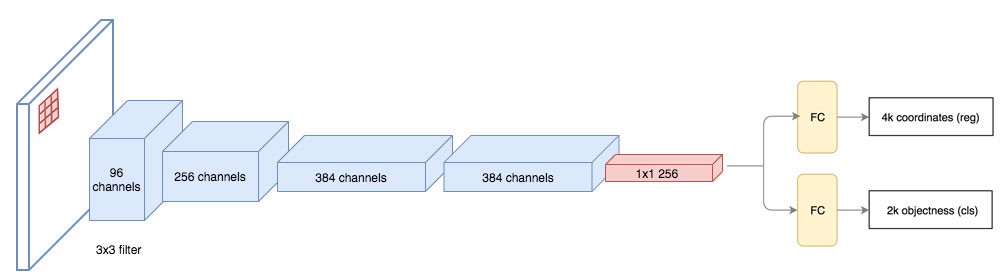
8.Region proposal network 区域提议网络(RPN)以来自第一卷积网络的输出特征映射作为输入。它在特征图上使用3×3滤波器,使用ZF网络这样的卷积网络(如下面),提出与类无关的区域建议。其他深网络,如VGG或ResNet,可以以速度为代价进行更全面的特征提取。ZF网络输出256个值,输入两个独立的全连接层来预测边界框和2个objectness分数。框是否包含一个对象。我们可以使用一个回归器来计算单个对象的得分,但为了简单起见,R-CNN使用了一个带有两类的分类器:一个用于“有一个对象”类别,另一个没有(即背景类)。
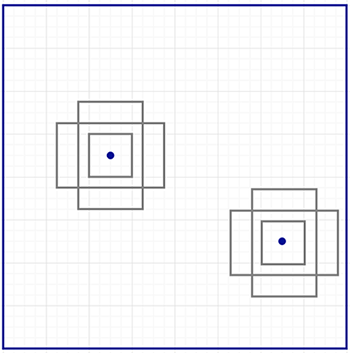
对于特征映射中的每个位置,RPN进行k个猜测。因此,RPN每个位置输出4×k坐标和2×k scores。下图显示带3×3滤波器的8×8特征图,共输出8×8×3 ROI(k=3)。右边的图表显示了由一个地点提出的3项proposals 。
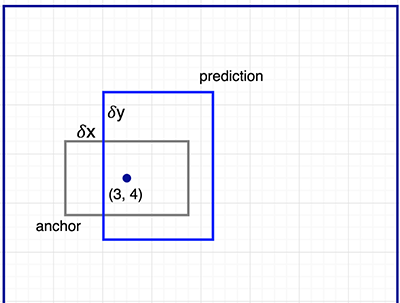
在这里,我们得到三个猜测,我们将在稍后完善我们的猜测。因为我们只需要一个是正确的,如果我们的最初猜测有不同的形状和大小,这样会更好。因此,Faster R-CNN不会提出随机的边界框proposals.相反,它预测了相对于一些称为anchors的参考框左上角的偏移量,如果我们的最初猜测有不同的形状和大小,这样会更好。因此,Faster R-CNN不会提出随机的边界框.相反,它预测了相对于一些称为锚的参考框左上角的偏移量。
Faster R-CNN使用更多的anchors。它配置9个anchors箱:3种不同的尺度,3种不同的纵横比。每个位置使用9个锚,每个位置产生2×9 scores 和4×9坐标。
9.R-CNN方法的性能 如下图所示,R-CNN的速度更快.
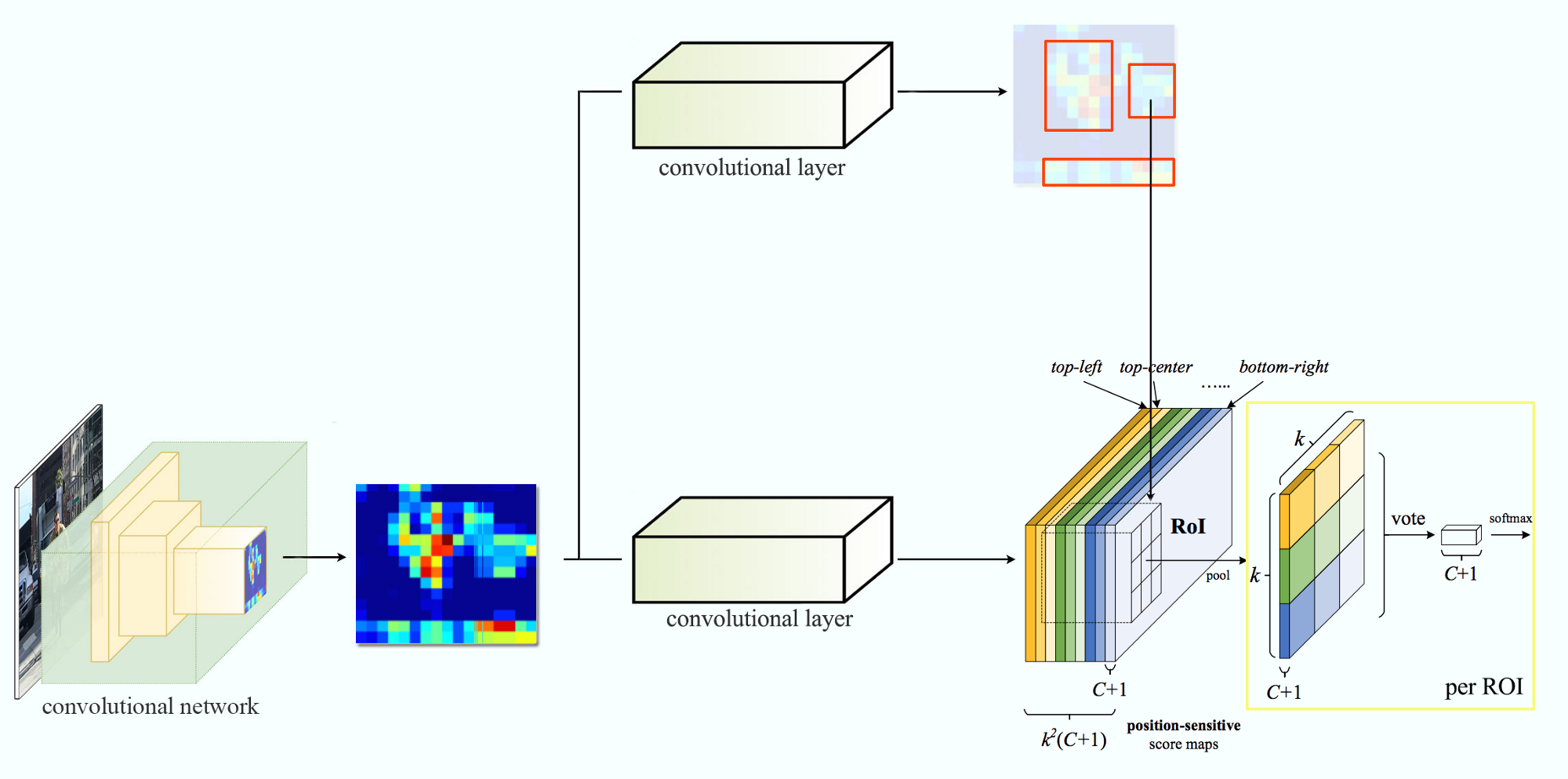
10.基于区域的全卷积网络(R-FCN) 让我们假设我们只有一个特征图检测右眼的脸。我们能用它来定位脸部吗?应该是的。因为右眼应该在面部图片的左上角,所以我们可以用它来定位脸部。
在速度更快的Faster R-CNN中,探测器使用多个完全连接层来进行预测.有了2000ROIs,它可能会使用更多的资源。
由于我们将正方形划分为9个部分,因此我们可以创建9个特征映射,每个特征映射分别检测到对象的相应区域。这些特征映射被称为position-sensitive score maps ,因为每个map检测对象的一个子区域(scores)。
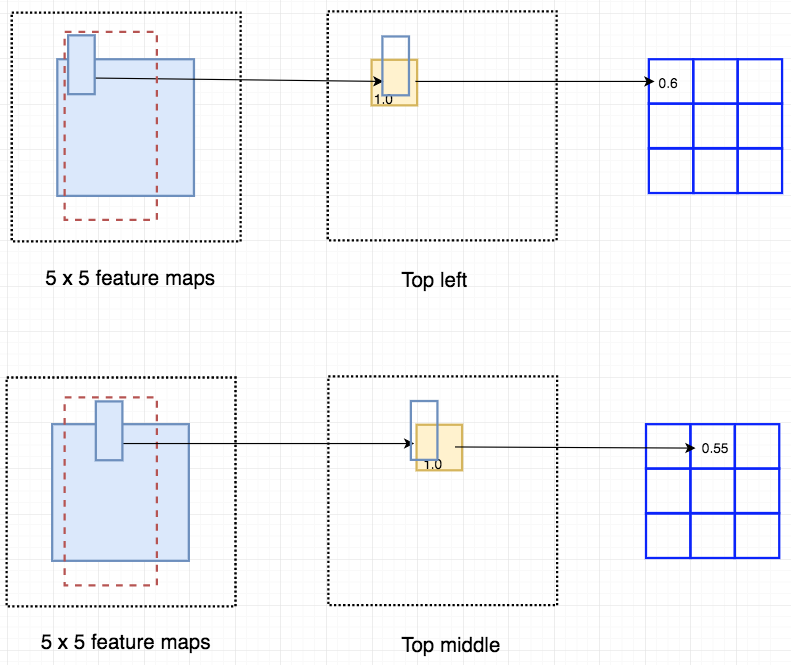
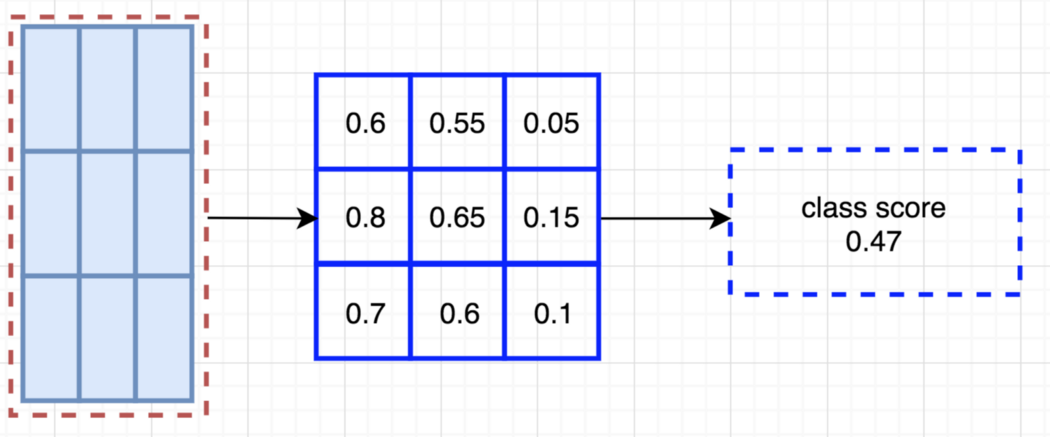
假设下面的红色矩形是ROI proposals 。我们将其划分为3×3区域,并询问每个区域包含对象的对应部分的可能性。例如,左上角ROI区域包含左眼的可能性有多大.我们将结果存储到右图中的3×3投票数组中。例如,表决数组[0][0]包含我们是否找到正方形对象左上角区域的分数。
Apply ROI onto the feature maps to output a 3 x 3 array. 将分数映射和ROIS映射到投票数组的过程称为position-sensitive ROI-pool。这个过程非常接近我们之前讨论过的ROI-pool。我们将不进一步讨论它,但您可以参考我其他博客。
Overlay a portion of the ROI onto the corresponding score map to calculate V[j] 在计算位position-sensitive ROI-pool的所有值之后,类得分是其所有元素的平均值。
假设我们有C类要检测。我们将其扩展到C+1类,因此我们为背景(非对象)添加了一个新类。每个类别都有自己的3×3分数图,因此总共有(C+1)×3×3分数图。使用它自己的一组分数图,我们预测每个类的类别分数。然后,我们对这些分数应用一个软件最大值来计算每个类的概率。 以下是数据流图。对于我们的例子,我们有以下k=3。
至此结束 |