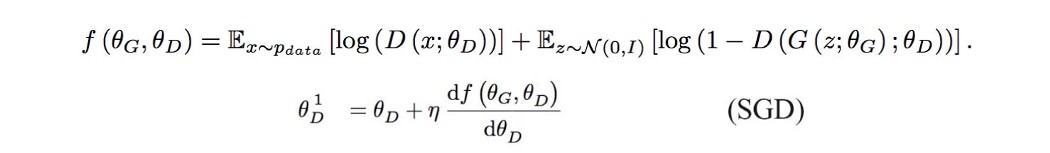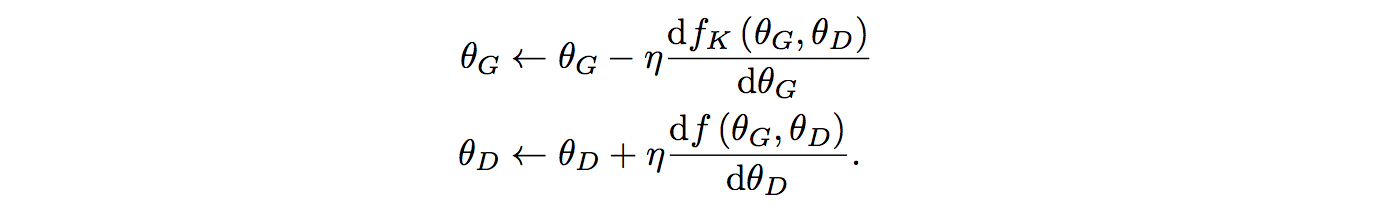|
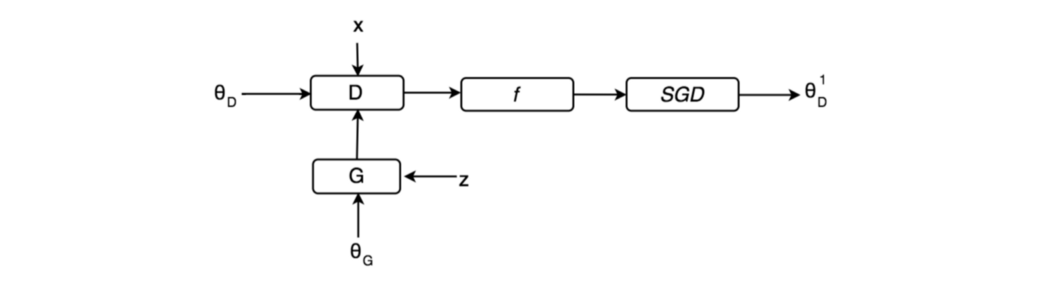
直觉:在任何游戏中,你都会提前预测对手接下来的几步棋,并相应地准备下一步棋。 在 Unrolled GAN 中,我们为生成器提供了一个机会,可以展开 k 步来了解鉴别器如何优化自身。 然后我们使用反向传播更新生成器,并使用最后 k 步计算的成本。 前瞻不鼓励生成器利用容易被鉴别器抵消的局部最优值。 否则,模型会振荡,甚至变得不稳定。 Unrolled GAN 降低了生成器过度拟合特定判别器的机会。 这减少了模式崩溃并提高了稳定性。 本文是 GAN 系列的一部分。 由于模式崩溃很常见,我们花一些时间来探索 Unrolled GAN,看看如何解决模式崩溃问题。 鉴别器训练 在 GAN 中,我们计算成本函数并使用反向传播来拟合判别器 D 和生成器 G 的模型参数。
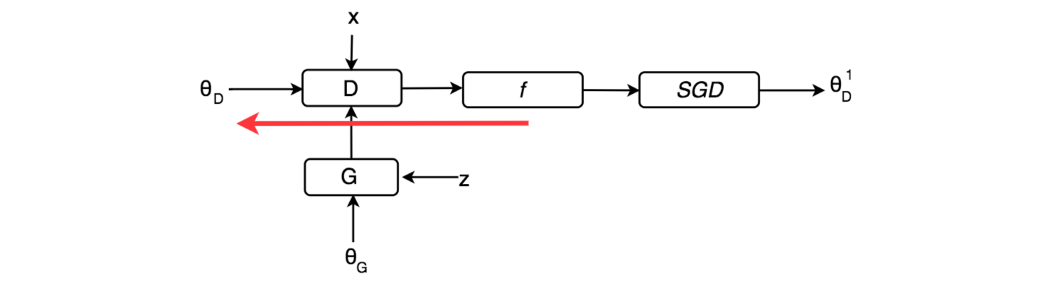
我们重新绘制下图以强调模型参数 θ。 红色箭头显示了我们如何反向传播成本函数 f 以拟合模型参数。
这是成本函数和梯度下降。 (为了说明的目的,我们使用简单的梯度下降)
在下图中,我们添加了 SGD(梯度下降公式)来明确定义判别器参数的计算方式。 在 Unrolled GAN 中,我们训练判别器的方式与 GAN 完全相同。
生成器训练 Unrolled GAN 运行 k 个步骤来学习鉴别器如何针对特定生成器优化自身。 通常,我们使用 5 到 10 个展开步骤,这表明模型性能非常好。 下图将过程展开 3 次。
成本函数基于最新的鉴别器模型参数,而生成器的模型参数保持不变。
在每一步,我们应用梯度下降来优化判别器的新模型。
但如前所述,我们只使用第一步来更新判别器。 生成器使用展开来预测移动,但不用于鉴别器优化。 否则,我们可能会过度拟合特定生成器的判别器。
对于生成器,我们在所有 k 步中反向传播梯度。 这与 LSTM 如何展开以及梯度如何反向传播非常相似。 由于我们有 k 个展开的步骤,因此生成器还会累积参数更改 k 次(每一步一次),如上所示。
总而言之,Unrolled GAN 使用在最后一步计算的成本函数来执行生成器的反向传播,而鉴别器仅使用第一步。 代码 Unrolled GAN 的实现可以从这里找到。 实际上,这很简单。 展开 k 步的核心逻辑很简单:
graph_replace 使用上一步中的最新鉴别器模型加载鉴别器。 这是在 TensorFlow 中构建计算图的核心逻辑。 实验 在下面的实验中,我们从一个玩具数据集开始,其中包含 8 个高斯分布的混合。 提供了一个不太复杂的生成器,第二行中的 GAN 设法生成了良好的数据质量,但未能实现多样性。 模式崩溃。 应用 Unrolled GAN,它发现了所有 8 种高质量模式(第一行)。
RNN 生成器特别容易受到模式崩溃的影响。 Unrolled GAN(第一行)设法发现所有 10 种模式,而常规 GAN 模型崩溃(第二行)。
|