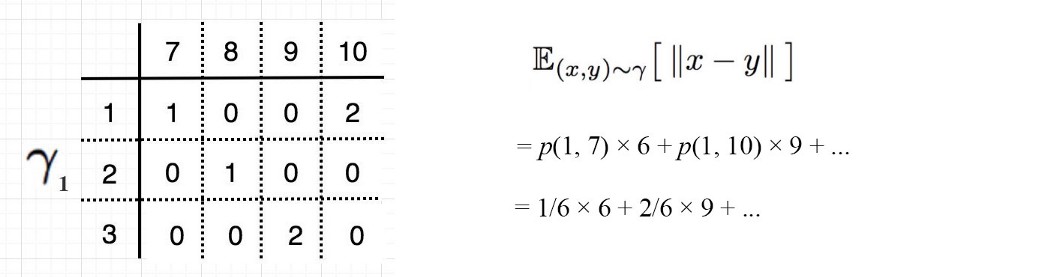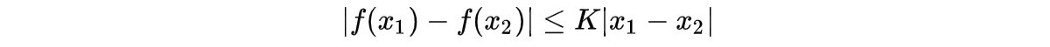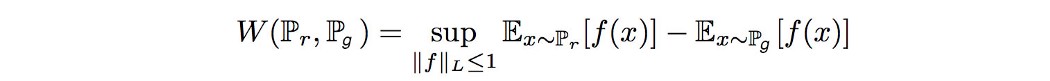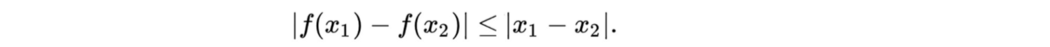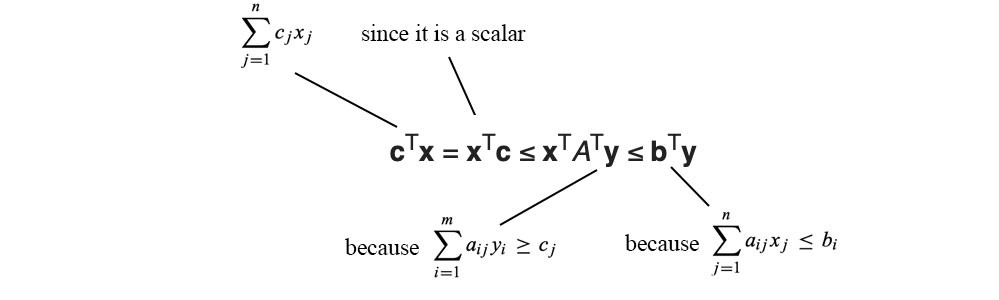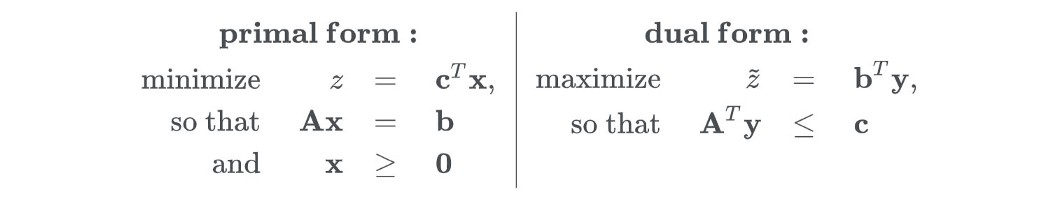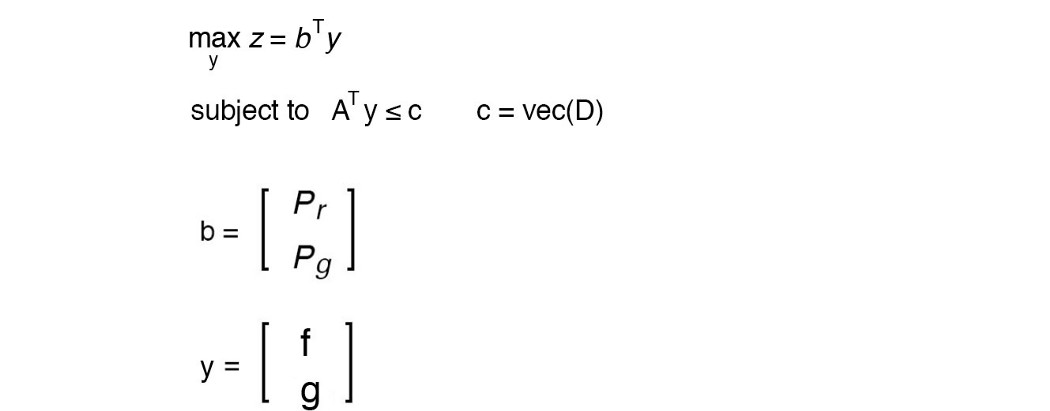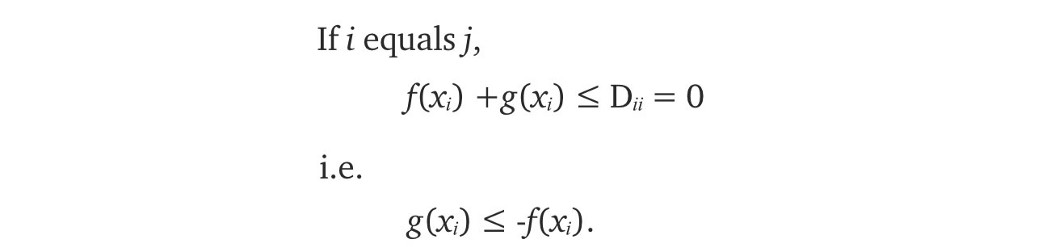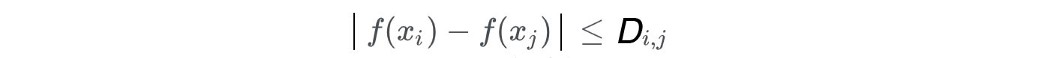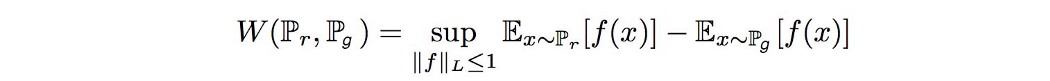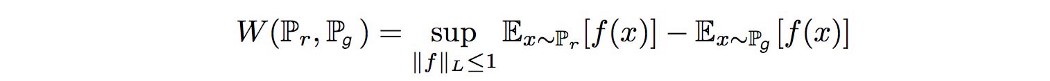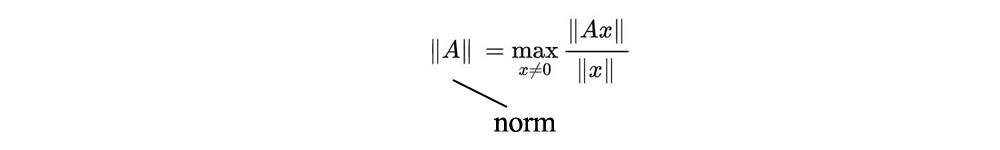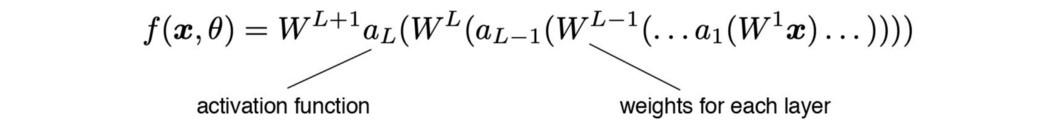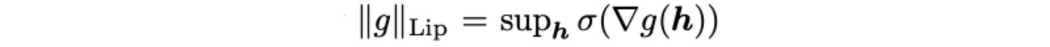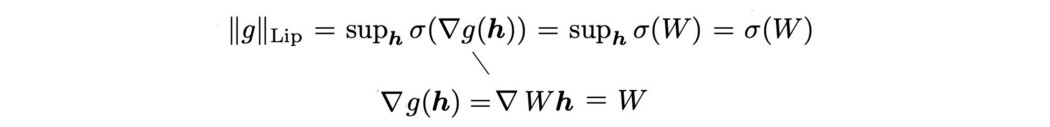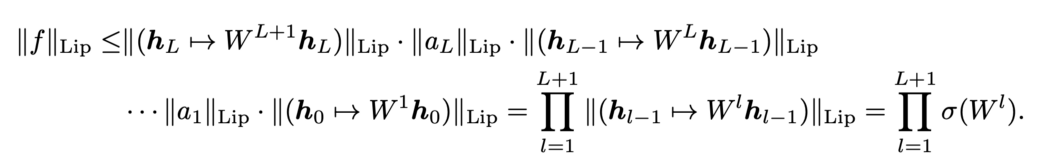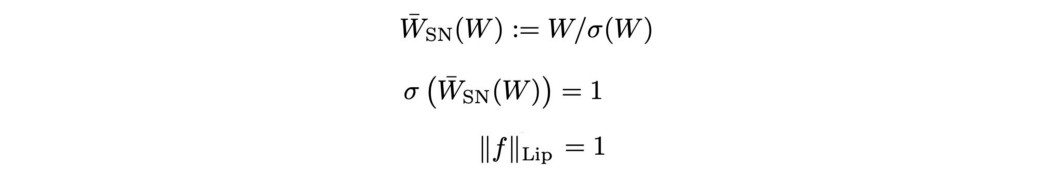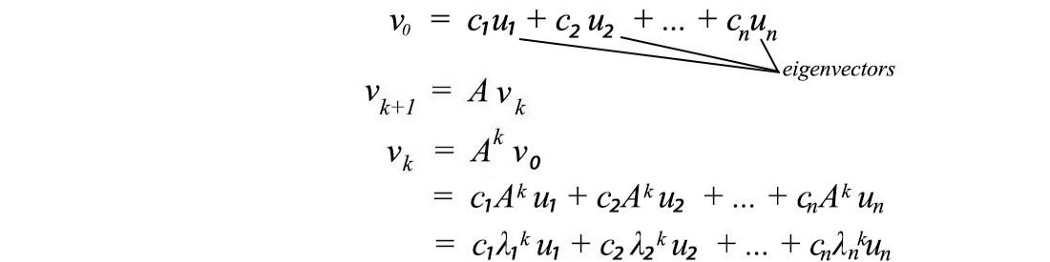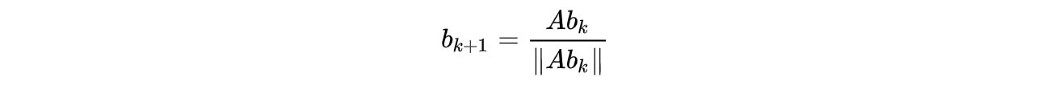|
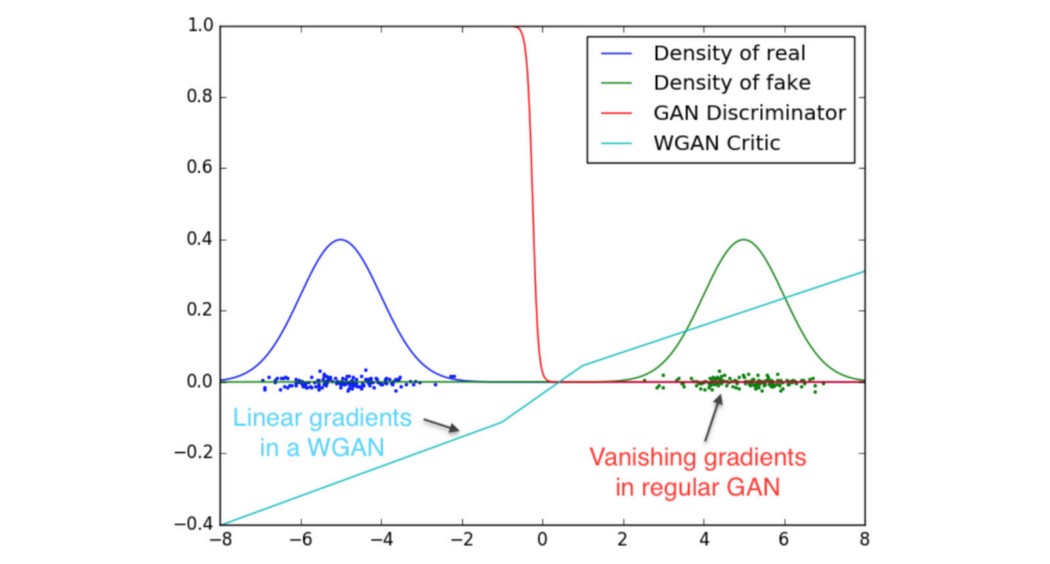
GAN 容易受到模式崩溃和训练不稳定的影响。 在本文中,我们研究了频谱归一化以解决这些问题。 但是,要了解光谱归一化,我们需要先回顾一下 WGAN。 讨论将涉及可能不熟悉的数学概念。 我们将首先介绍这些术语,然后让它们易于理解。 理论上,当 GAN 中生成的分布和真实分布不相交时,cost函数的梯度将由梯度消失和爆炸的区域组成——下面的红线。
WGAN 声称 Wasserstein 距离将是一个更好的cost函数,因为它具有更平滑的梯度(蓝线),可以更好地学习。 在实践中,通过适当的调整,vanilla GAN 可以生成高质量的图像,但模式崩溃仍然是一个突出问题。 Wasserstein 距离的真正挑战是如何有效地计算它。 一种可能性是应用 Lipschitz 约束来计算 Wasserstein 距离。 WGAN 应用一个简单的裁剪来强制执行 1-Lipschitz 约束。 WGAN-GP 使用更复杂的方案强制约束,以纠正 WGAN 中观察到的一些问题(有关 WGAN 和 WGAN-GP 的详细信息,请参见此处)。 谱归一化是一种权重归一化,可以稳定判别器的训练。 它控制判别器的 Lipschitz 常数,以缓解爆炸梯度问题和模式崩溃问题。 与 WGAN-GP 相比,这种方法在计算上将更轻,并实现良好的模式覆盖。 Earth-Mover(EM) 距离/ Wasserstein 度量 让我们快速回顾一下 Wasserstein 距离。 首先,我们要将 6 个框从左下方移动到右侧由虚线方框标记的位置。 对于框 #1,让我们将其从位置 1 移动到位置 7。移动cost定义为行驶距离。 因此,要将框 #1 移动到位置 7,cost等于 6。
但是,移动这些boxes的方法不止一种。 我们称移动计划 i 为 γᵢ。 例如,在下面的第一个计划 γ1 中,我们将 2 个boxes从位置 1 移动到位置 10。下面,我们展示了两个不同的计划,它们的移动cost都是 42。
然而,并非所有的交通计划都承担相同的cost。 Wasserstein 距离(或 EM 距离)是最便宜的交通计划的cost。 在下面的示例中,Wasserstein 距离(最小cost)为 2。
Wasserstein 距离的形式化可以很容易地从离散空间扩展到连续空间,如下所示:
让我们再次回到我们的例子。 下面的每个表格单元格 (x, y) 对应于从位置 x 移动到 y 的框数。 在将像元值归一化为概率值后,γ₁ 的移动cost计算为:
Wasserstein distance 查找最便宜计划的距离。 对于任何有效的计划 γ,其边际必须分别等于 p(x) 和 p(y)。
例如,
在连续的空间中,
∏ 是其边际分别等于 p(x) 和 p(y) 的有效计划集。 γ 是这些计划之一,它对 x 和 y 的联合概率分布进行建模。 我们想在∏中找到cost最低的一个。 接下来,让我们看看 Lipschitz 约束。 Lipschitz 连续性 一个实函数 f : R → R 是 Lipschitz 连续的,如果
对于 x₁ 和 x₂ 的 ∀ 实值。 直观地说,Lipschitz 连续函数限制了 f 变化的速度。
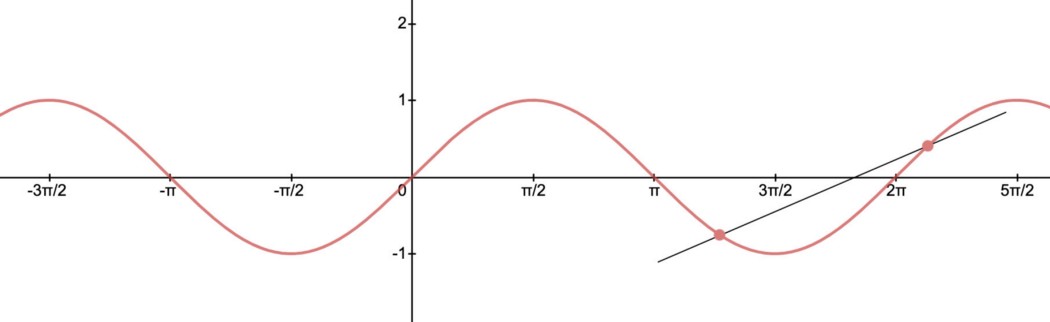
如果我们将 f(x1) 和 f(x2) 连接在一起,它的斜率的绝对值总是小于 K,称为函数的 Lipschitz 常数。 如果一个函数有界一阶导数,它就是 Lipschitz。 它的 Lipschitz 常数等于导数的最大绝对值。 对于 sin 函数,其导数的绝对值始终以 1 为界,因此它是 Lipschitz。 Lipschitz 常数等于 1。 直观地说,Lipschitz 连续性限制了梯度,并有利于缓解深度学习中的梯度爆炸。
从图形上看,我们可以构造一个斜率为 K 和 -K 的双锥。 如果我们沿着图形移动它的原点,图形将始终保持在圆锥之外。
Wasserstein距离 Wasserstein 距离的原始公式化通常是难以处理的。 幸运的是,使用 Kantorovich-Rubinstein 对偶,我们可以简化计算
到
其中 sup 是最小上界。 我们需要找到 f ,它是一个遵循约束的 1-Lipschitz 函数
并最大化
在接下来的几节中,我们尝试给出一个没有繁琐数学术语的高级证明。 双重问题 让我们在线性代数的背景下研究对偶问题。 在优化中,我们可以将对偶问题与原始问题联系起来。
根据弱对偶定理,z (cᵀx) 是 v (z≤v) 的下界。 因此,对偶问题为原始问题建立了一个上限。
强对偶性声称原始问题和对偶问题的最优解是相同的(z* = v*)。 然而,这种强二元性只适用于特殊条件。 可以以线性代数形式构建的优化问题确实具有强对偶性(证明)。 因此,如果原始问题难以解决,我们检查对偶是否可能更容易。 这导致了 Kantorovich-Rubinstein 对偶。 Kantorovich-Rubinstein 对偶 因此,让我们将其应用于查找 Wasserstein 距离。 我们的原始和对偶问题将采用以下形式:
原始的是
和
这很难解决,让我们尝试解决对偶问题,
和
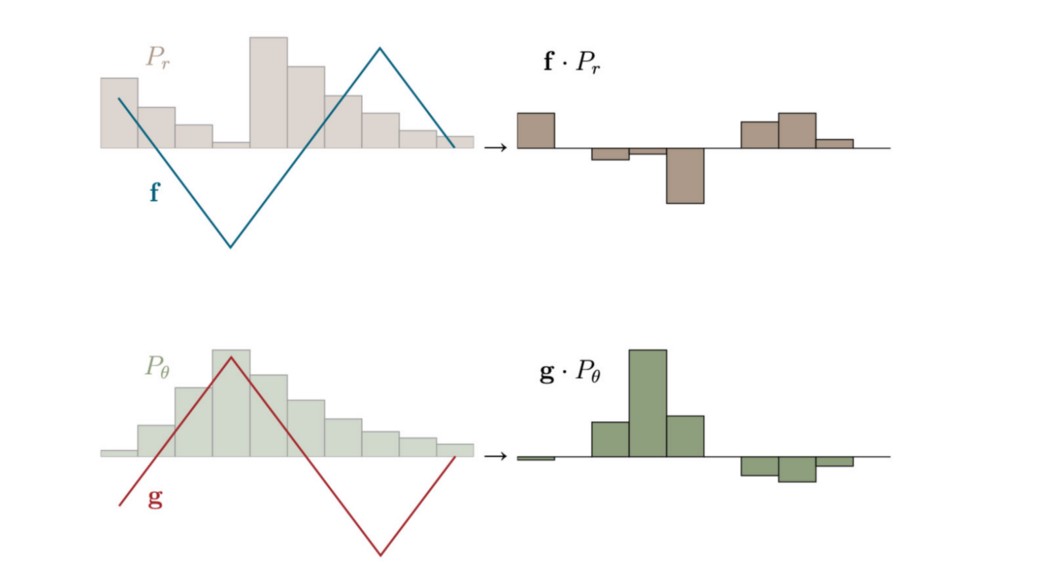
目标是最大化 fᵀ Pr + gᵀ Pg,同时保持约束 f(xᵢ) +g(xⱼ) ≤ Dᵢⱼ。
由于 Pr 和 Pg 是非负的,因此在最大化目标时为 g 选择可能的最高值是有意义的,即 g =-f 而不是 g < -f。 在没有进一步证明的情况下,g =-f 通常是我们想要的。 我们的约束变成
也就是说,我们要限制函数的速率变化。 因此,要解决对偶问题,我们需要 f 是 Lipschitz 约束。 WGAN 为了找到 Wasserstein 距离,我们在 f 是 1-Lipschitz 连续的约束下最大化对偶问题。
Prf 和 Pgf 项分别成为从分布 Pr 和 Pg 中采样的 f(x) 的期望值。
从图形上看,如果 Pr ≥ Pg(低于 Pθ),我们希望 f 具有较高的值,如果 Pg > Pr,我们希望 f 具有较低的值。
在 GAN 中,我们使用以下cost函数训练鉴别器和生成器。
在 WGAN 中,我们训练一个 Lipschitz 函数 f。
我们使用目标使用 Wasserstein 距离优化评价 f 的 w。
为了强制执行 Lipschitz 约束,WGAN 只需裁剪 w 的值。
WGAN 算法 这是WGAN算法。
然而,正如研究论文所引用的: 权重裁剪显然是实施 Lipschitz 约束的糟糕方法。 如果裁剪参数很大,那么任何权重都可能需要很长时间才能达到其极限,从而使得训练critic 直到达到最优变得更加困难。 如果剪裁很小,当层数很大时,这很容易导致梯度消失……我们坚持使用权重剪裁,因为它简单且性能已经很好。 调整 c 的值很难。 找到正确的值是困难的。 一个小的变化可以显着改变梯度范数。 此外,一些研究人员认为 WGAN 中图像质量的提高以模式多样性为代价。 WGAN-GP 引入梯度惩罚来强制执行 Lipschitz 约束。 然而,这增加了计算复杂度。 Spectral norm 矩阵norm或spectral norm定义为:
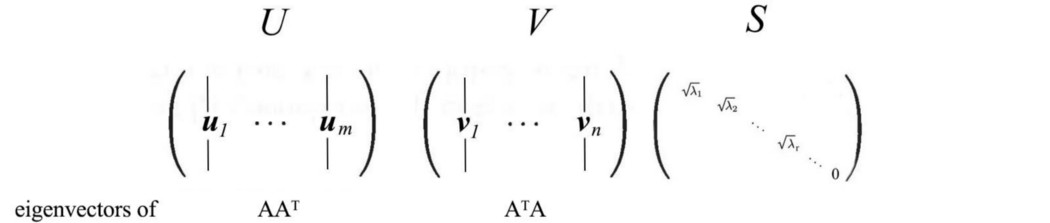
从概念上讲,它测量矩阵 A 可以拉伸向量 x 的程度。 根据 SVD,矩阵可以分解为:
其中
U 和 V 分别被选为 AAᵀ 和 AᵀA 的正交 (UᵀU=I) 特征向量。 AAᵀ 和 AᵀA 都具有相同的正特征值。 S 包含这些特征值的平方根,称为奇异值。 谱范数 σ(A) 是矩阵 A 的最大奇异值(证明)。 Spectral normalization 让我们用以下公式化构建一个深度网络。
对于每一层 L,它输出 y = Ax,然后是激活函数 a,比如 ReLU。 函数 g 的 Lipschitz 常数(或 Lipschitz 范数)可以用它的导数计算为:
g = Ax 的 Lipschitz 常数是 W 的谱范数。
RELU 的 Lipschitz 常数为 1,因为它的最大斜率等于 1。 因此,整个深度网络 f 的 Lipschitz 常数为
谱归一化使用谱范数 σ(W) 对每一层的权重进行归一化,使得每一层以及整个网络的 Lipschitz 常数都等于 1。
使用光谱归一化,我们可以在权重更新时对其进行重新归一化。 这创建了一个缓解梯度爆炸问题的网络。 但是我们如何有效地计算 σ(W),因为找到特征向量是昂贵的。 Power Iteration 具有特征向量 u 的 A 的 k 次方很容易计算。
我们可以将向量 v 表示为 A 的特征向量的线性组合,并轻松计算其与 A 的 k 次方。
将 u 视为 A 的特征向量。我们可以将这些特征向量重新排序,其中 u₁ 是具有最高特征值(主要特征向量)的特征向量。 向量 b 可以分解为 A 的特征向量。 A 与 v 的 k 次方将接近:
使用以下迭代从 b₀ 开始,b 将收敛到主要特征向量的倍数。 简而言之,我们可以从一个随机向量 b₀ 开始。 将它与 A 相乘,我们可以逼近主导特征向量。
相同的概念可以用迭代计算的 u 和 v 来完成,如下所示(其中 A 现在写为 W)。
在 SGD 中,W 在每次迭代中的变化很小。 因此,光谱范数的变化也很小。 因此,Spectral normalization 可以重用上一次迭代中 u 的值。 实际上,不需要在幂迭代中进行多次迭代,只需要一次迭代,即我们每次更新只计算一次下面的等式 20 和 21。 这显着降低了计算复杂度。 这是应用频谱归一化的最终算法。
|