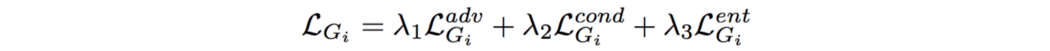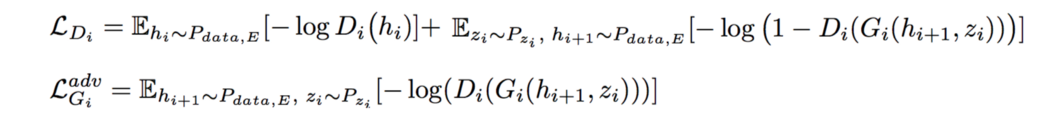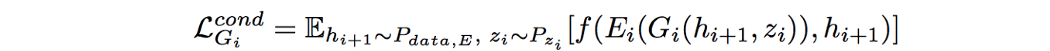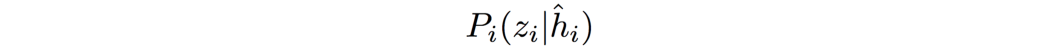|
在本文中,我们将研究 SGAN 的细节,它在 GAN 中产生了一些最高的图像质量。 堆叠生成对抗网络(SGAN)由
此处的解码器充当 GAN 模型中的生成器。
正如名称“stacked”所暗示的那样,解码和编码是在堆栈中完成的。
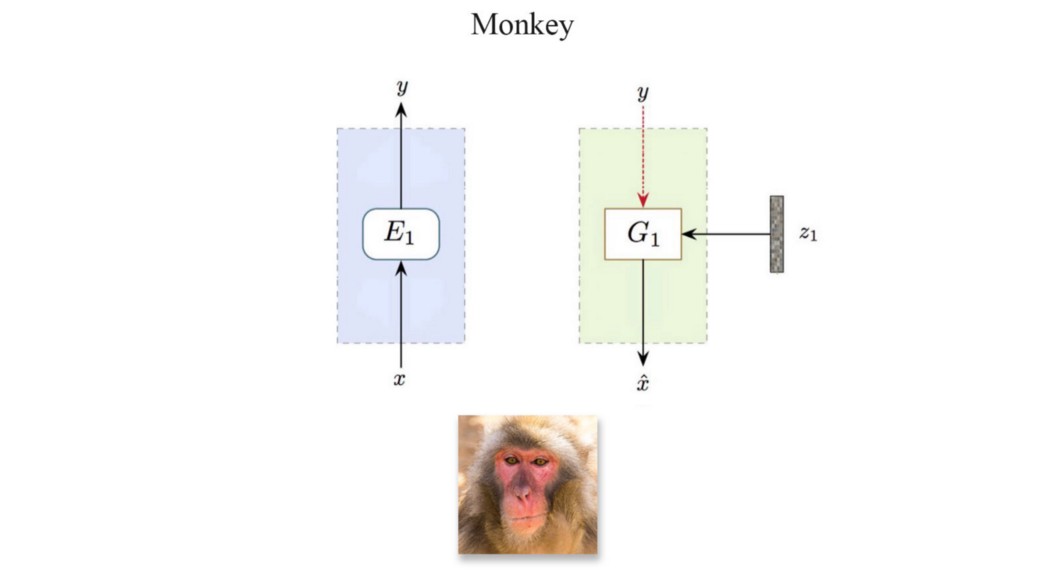
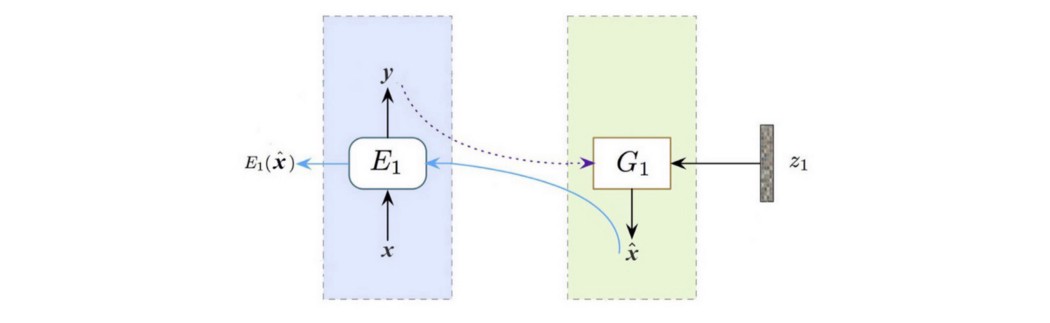
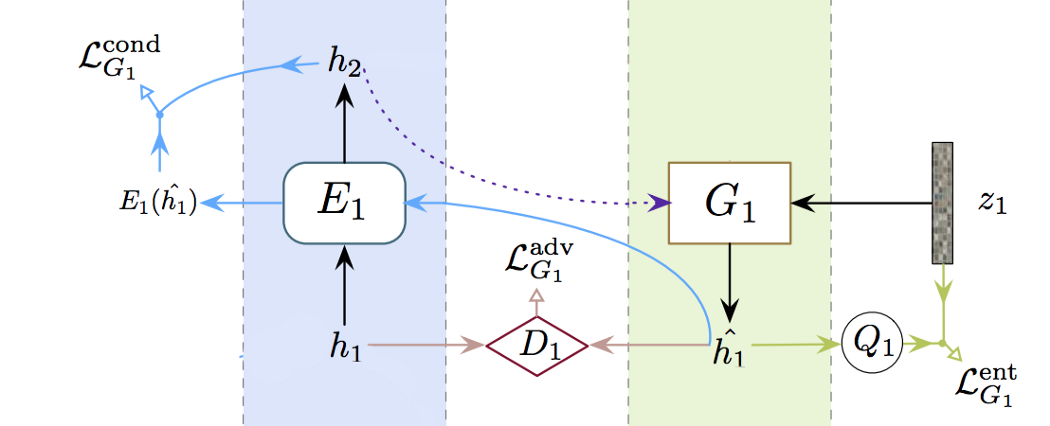
但让我们只关注只有 1 个单层的设计。 图像 x 被输入编码器 E1 以预测标签 y。 然后将其与噪声 z1 一起馈入生成器 G1 以生成图像。 生成的图像被转发到 E1 编码器以再次预测标签。
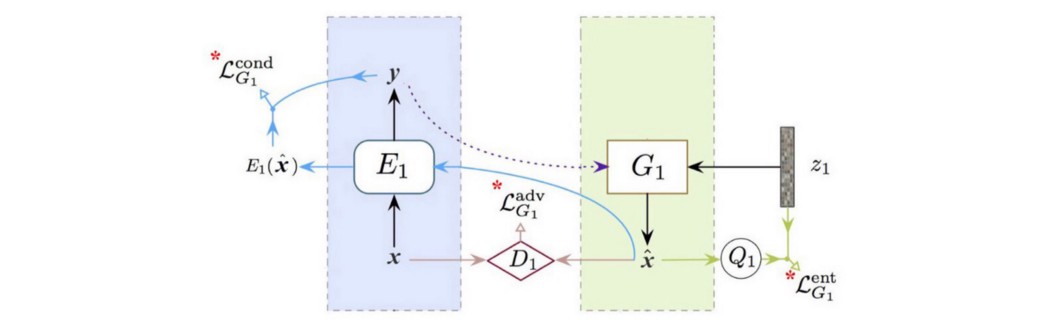
现在,我们有一个生成图像和 2 个预测标签(一个用于真实图像,另一个用于生成图像)。 训练生成器 G1 的cost函数由三部分组成
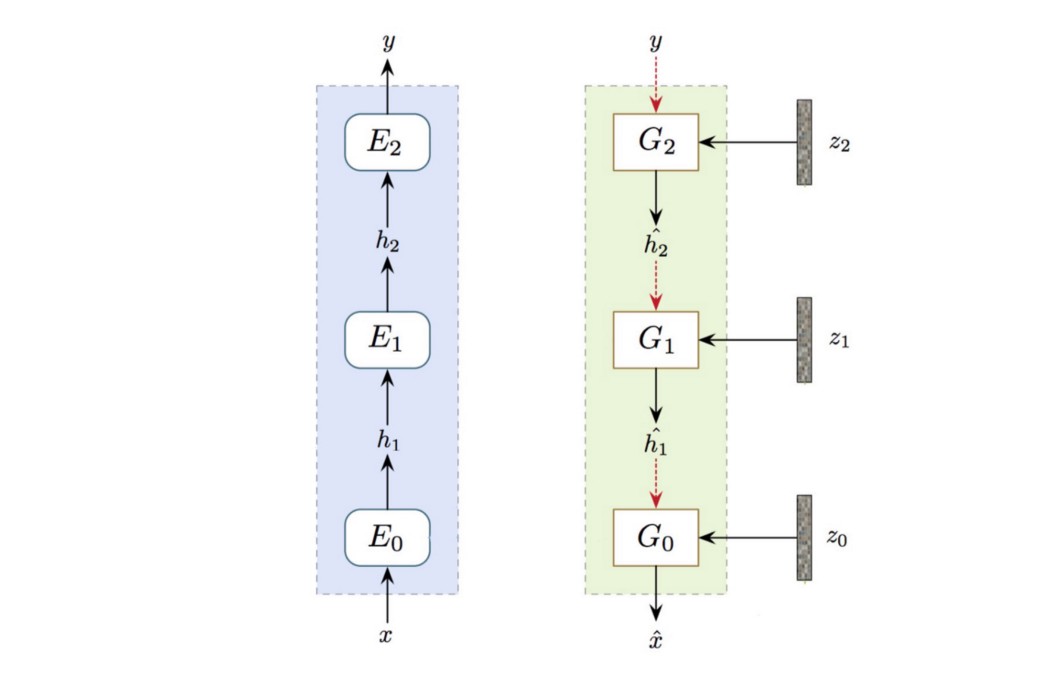
在进入细节之前,我们修改图中的标签。 在多级堆栈中,h 是分别从编码器和生成器提取和生成的特征。
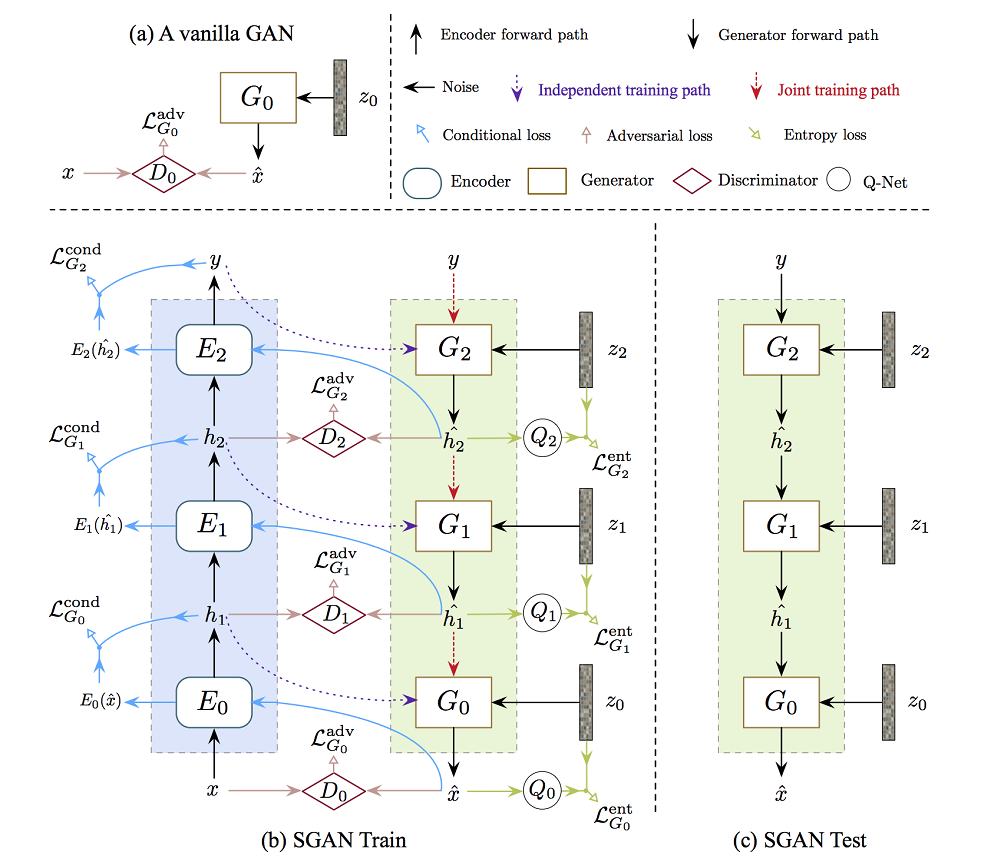
对抗性损失 对抗性损失与任何 GAN 没有什么不同。 我们已经看过很多次了,因此我们不会进一步详细说明。
条件损失 我们比较了编码器使用真实图像和生成图像(下面的蓝线)编码的特征。
我们使用函数 f 计算它们的距离,比如欧几里得距离。 这确保了我们的生成器和编码器创建和编码与其对应物相似的特征。
熵损失 上面的条件损失降低了图像的多样性。 条件损失鼓励 G 使用 G1(h2) 而不是 G1(h2, z1) 创建图像。 如果 G 忽略噪声,它会减少条件损失。
我们创建另一个网络 Q,它与 D 共享所有层,除了最后一个输出dense层来估计:
其中 P 是在给定特征 h 的情况下观察 z 的机会。 这是我们为训练生成器而添加的熵损失
如果 z 与 h1 的潜在特征无关,这会惩罚网络,它会强制 h1 = G1(h2, z1)。 这是伪代码。 但是我们使用 MSE 来计算损失而不是交叉熵。 训练编码器 与其他 GAN 模型不同,训练数据集包含图像和标签。 训练编码器与使用监督学习训练分类器相同。
训练过程 剩下的训练过程包括
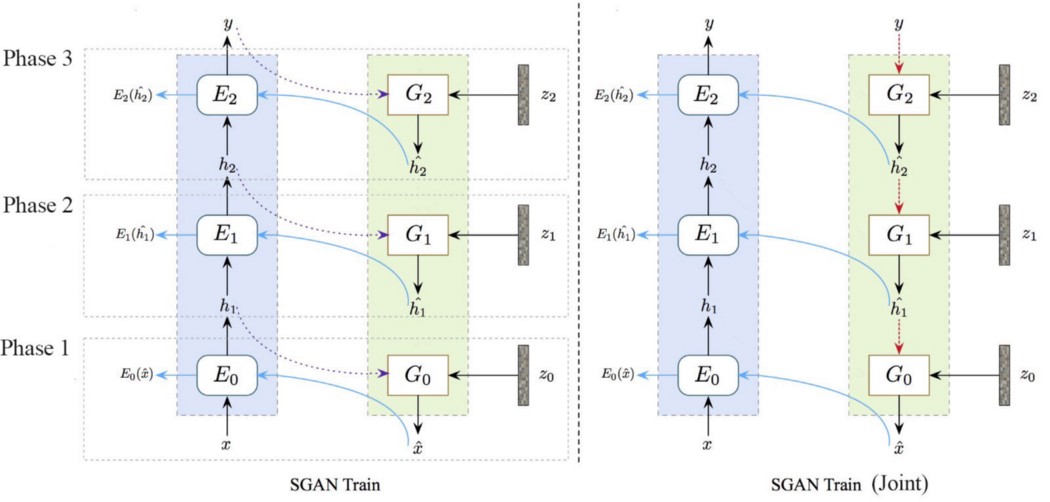
在下图的左侧,我们分别独立地训练每个单独的级别(从阶段 1 到阶段 3)。 然后我们联合训练所有级别(右侧)。
训练堆栈的单个级别 接下来,我们单独训练每个堆栈层。
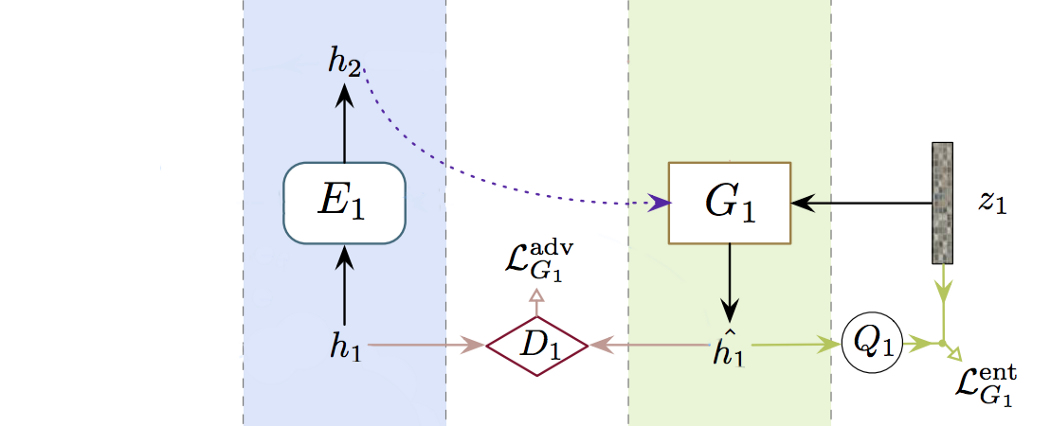
对于下面的 3 层堆栈,我们将从底部到顶部进行三个独立且独立的训练。 我们首先训练层 E0 和 G0。 完成后,我们训练 E1 和 G1。 最后,我们训练 E2 和 G2。
联合训练 最后,我们使用所有层进行联合训练。
但是,我们不会将编码器的输出作为生成器的输入。 我们使用生成器上层的输出来代替:
测试 这是创建标签 y 图像的流程。
最后,这张图总结了整个流程,供大家参考。
结论 训练 GAN 很困难。 通过将训练分成多个层,我们可以使用分治法来获得比单层更高的图像质量。 |