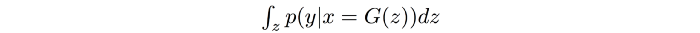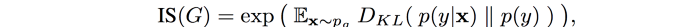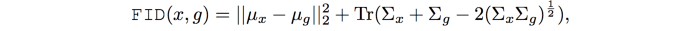|
在 GAN 中,生成器和鉴别器的目标函数通常衡量它们相对于对手的表现。 例如,我们测量生成器愚弄鉴别器的程度。 它不是衡量图像质量或其多样性的好指标。 作为 GAN 系列的一部分,我们研究了如何比较不同 GAN 模型的结果的 Inception Score 和 Fréchet Inception Distance。 Inception Score(IS) IS 使用两个标准来衡量 GAN 的性能:
熵可以被视为随机性。 如果随机变量 x 的值是高度可预测的,则它的熵较低。 相反,如果它是高度不可预测的,那么熵就很高。 例如,在下图中,我们有两个概率分布 p(x)。 p2 具有比 p1 更高的熵,因为 p2 具有更均匀的分布,因此对于 x 的可预测性更小。
在 GAN 中,我们希望条件概率 P(y|x) 是高度可预测的(低熵)。 即给定图像,我们应该很容易知道对象类型。 因此,我们使用 Inception 网络对生成的图像进行分类并预测 P(y|x)——其中 y 是标签,x 是生成的数据。 这反映了图像的质量。 接下来我们需要测量图像的多样性。 P(y) 是计算的边际概率:
如果生成的图像多种多样,则 y 的数据分布应该是均匀的(高熵)。 下图形象化了这个概念。
为了结合这两个标准,我们计算了它们的 KL 散度并使用下面的等式来计算 IS。
IS 的一个缺点是,如果每个类只生成一张图像,它可能会歪曲性能。 即使多样性很低,p(y) 仍然是统一的。 Fréchet Inception Distance (FID) 在 FID 中,我们使用 Inception 网络从中间层提取特征。 然后我们使用具有均值 μ 和协方差 Σ 的多元高斯分布对这些特征的数据分布进行建模。 真实图像 x 和生成图像 g 之间的 FID 计算如下:
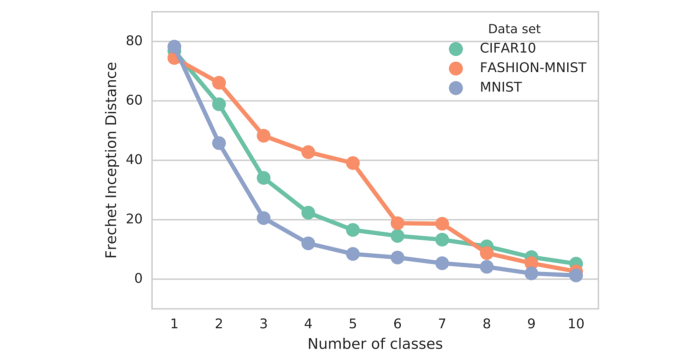
其中 Tr 汇总了所有对角线元素。 较低的 FID 值意味着更好的图像质量和多样性。 FID 对模式崩溃很敏感。 如下图所示,距离随着模拟的缺失模式而增加。
FID 对噪声的鲁棒性比 IS 强。 如果模型每个类只生成一张图像,距离会很大。 所以 FID 是一个更好的图像多样性度量。 FID 有一些相当高的偏差但低方差。 通过计算训练数据集和测试数据集之间的 FID,我们应该期望 FID 为零,因为两者都是真实图像。 但是,使用不同批次的训练样本运行测试显示非零 FID。
此外,FID 和 IS 都基于特征提取(特征的存在与否)。 如果不保持空间关系,生成器是否会有相同的分数?
准确率、召回率和 F1 分数 如果生成的图像平均看起来与真实图像相似,则精度很高。 高召回率意味着生成器可以生成在训练数据集中找到的任何样本。 F1 分数是准确率和召回率的调和平均值。 在 Google Brain 的研究论文“Are GANs created equal”中,创建了一个使用三角形数据集的玩具实验来测量不同 GAN 模型的精度和召回率。
这个toy datasets可以衡量不同 GAN 模型的性能。 我们可以用它来衡量不同成本函数的优点。 例如,新功能是否擅长制作覆盖率高的高质量三角形? |