|
在这个 GAN 系列中,我们确定了 GAN 如何应用于深度学习问题的一般模式,并研究了 GAN 为何如此难以训练的问题。 我们还查看了一些潜在的解决方案。 通过在一个上下文中回顾它们,让我们了解 GAN 研究的动机和方向以及它们背后的思考过程。 希望到最后,我们可以以某种形式清晰地处理大量信息。 应用
我们创建了 1024 × 1024 的图像(上图右图),可能会骗过星探。 让我们从生成数据 x 的基本思想开始。
在没有任何指导的情况下,生成器只会产生随机噪声。 在 Goodfellow 2014 年的 GAN 论文中,添加了一个鉴别器来提供模仿真实图像的指导。 如果您想了解 GAN 更多,那么我的其他文章会有所帮助。
虽然早期的 GAN 研究侧重于图像生成,但它已经扩展到其他领域,如动漫人物、音乐视频和其他行业,包括医疗。 另一个流行的扩展是跨域 GAN,用于将数据从域 A(例如文本)转换为域 B(图像)。
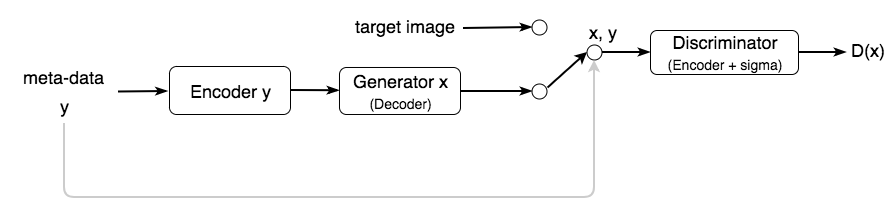
在上面的例子中,我们添加了一个编码器来提取文本的特征,然后是一个生成器来创建图像。 真实和生成的图像被送入鉴别器(又名编码器,后跟 sigma 函数)以识别它是否真实。
这种跨域转移的一个很好的演示是 CycleGAN,它将真实风景转换为Monet风格的绘画(反之亦然)。
许多域转移 GAN 添加了第二条路径来重建原始图像。 添加额外的重建成本以指导编码器更好地从 y 中提取特征。 因此生成的图像类似于原始输入的重要特征。
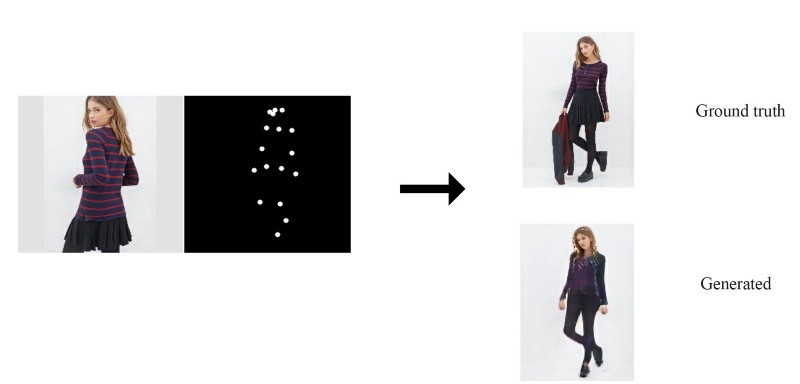
跨域 GAN 有许多潜在的商业应用。 另一种类型的 GAN 使用元数据生成图像。 例如,我们以不同的姿势创建图像或以不同的角度查看它们。
在这个例子中,我们将meta-data作为附加输入添加到编码器以生成图像。 我们还将原始图像(或有时是meta-data)作为附加输入传递给鉴别器以区分图像。
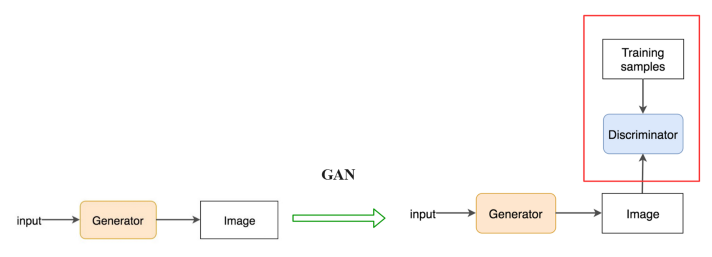
我们最后一种类型的 GAN 并不真的需要是 GAN。 每个人都可以偶尔从critic那里得到建议。 事实上,critic(鉴别器)的概念已经在强化学习中形成了一段时间。 研究人员可以在现有解决方案中应用 GAN,例如对象检测,以改进他们的结果。 在另一个例子中,深度网络编码器和解码器用于重建更高分辨率的图像,并使用均方误差 MSE 来训练网络。
为了介绍 GAN 的概念,我们使用鉴别器来指导生成器的训练。 要了解有关此类应用程序的更多信息,你可以阅读我系列中的超分辨率文章。 它提供了有关应用 GAN 概念生成超分辨率图像的更多细节。 以下是将 GAN 应用于现有解决方案的总体思路。
在本节中,我将不同的 GAN 应用程序组合在一起以说明它们的相似性 问题 训练 GAN 并不容易。 GAN 模型可能会遇到以下问题:
模式 当生成的图像收敛到相同的图像(相同的最佳点)时,模式会崩溃。
全模式崩溃并不常见。 但部分崩溃经常发生。 下面大约一半的图像有一张相似的图像。
我们对实践中模式崩溃的完整动态了解有限。 如果发生这种情况,建议采用Mitigation方法来惩罚生成器。 然而,部分崩溃仍然很常见。 生成器梯度 梯度下降依赖于梯度来学习。 这就像将大理石放入碗中一样。 但是,如果我们小心地将弹珠放在下方碗的边缘,它可能不会掉到底部。
优化 GAN 生成器接近于优化 JS 散度。 下图可视化了 JS-divergence 的值函数。 有一个低梯度区域,就像我们碗的边缘一样。 至少在开始的时候,训练是很慢的。
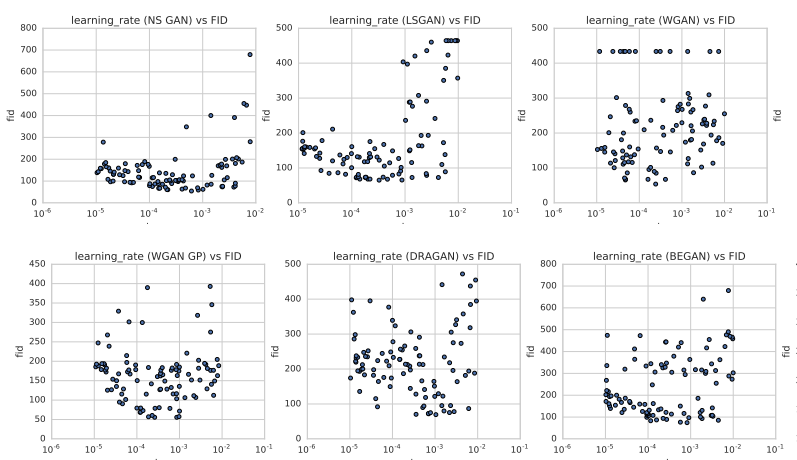
不收敛 GAN 是一种你的对手总是会抵消你的行为的游戏。 最优解被称为纳什均衡,很难找到。 梯度下降不一定是找到这种平衡的稳定方法。 当模式崩溃时,训练变成了模型永远不会收敛的猫捉老鼠游戏。 再想想,也许游戏的本质让 GAN 难以收敛。 其他问题 不收敛和模式崩溃通常被解释为鉴别器和生成器之间的不平衡。 鉴别器可能压倒另一个(反之亦然)。 有很多尝试解决这个问题,但在最初几年没有取得太大进展。 一些研究人员认为,这不是一个可行或理想的目标,因为一个好的鉴别器会提供好的反馈。 然而,最近在平衡训练方面取得了一些进展,采用了更加动态的方案。 GAN 对超参数优化很敏感。 性能可能会在超参数的短范围内波动。 证明代码和模型首先起作用。 然后耐心调整这些参数。 例如下图展示了不同成本函数下各种学习率(x轴)之间的性能(y轴)。 大范围的性能差异可能会影响您对设计是否有效的判断。
如果你对开发改进 GAN 训练的解决方案感兴趣,你可以阅读我后续文章。 测量 GAN 的目标函数衡量生成器和鉴别器之间的竞争。 但是,这些指标不反映图像质量,不适合模型比较、进度监控和性能调整。 在下图中,即使图像质量提高,生成器成本也会增加。
在早期的研究中,我们在视觉上比较了强烈偏向的模型结果。 早期研究论文中的许多“最先进”的说法很难证实或夸大其词。 为了解决这个问题,开发了 Inception Score (IS) 来衡量图像质量和多样性。 如果我们能够正确标记生成的图像,同时生成的图像均匀分布在不同的对象类中,我们会给它们一个高的 IS 分数。 Fréchet Inception 距离 (FID) 测量由 Inception 网络提取的真实图像和生成图像的特征之间的统计差异。 低 FID 距离表示生成的图像是自然的,与真实图像的多样性相似。 为了更多地了解 IS 和 FID 的定义及其弱点,我们提供了另一篇衡量 GAN 性能的文章。 |