|
AP(Average Precision)是衡量目标检测器(如 Faster R-CNN、SSD 等)精度的流行指标。平均精度计算召回值超过 0 到 1 的平均精度值。看起来很复杂,但实际上很简单,我们用一个例子来说明。 在此之前,我们先快速回顾一下精度、召回率和 IoU。 准确率和召回率 精度衡量你的预测的准确程度。 即你预测的百分比是正确的。 召回衡量你发现所有正样本的多少。 例如,我们可以在前 K 个预测中找到 80% 的可能正样本。 以下是它们的数学定义:
例如,在癌症检测中:
IoU (Intersection over union) IoU 衡量两个边界之间的重叠。 我们用它来衡量我们的预测边界与真实对象边界(真实对象边界)的重叠程度。 在一些数据集中,我们预先定义了一个 IoU 阈值(比如 0.5)来分类预测是正样本还是负样本。
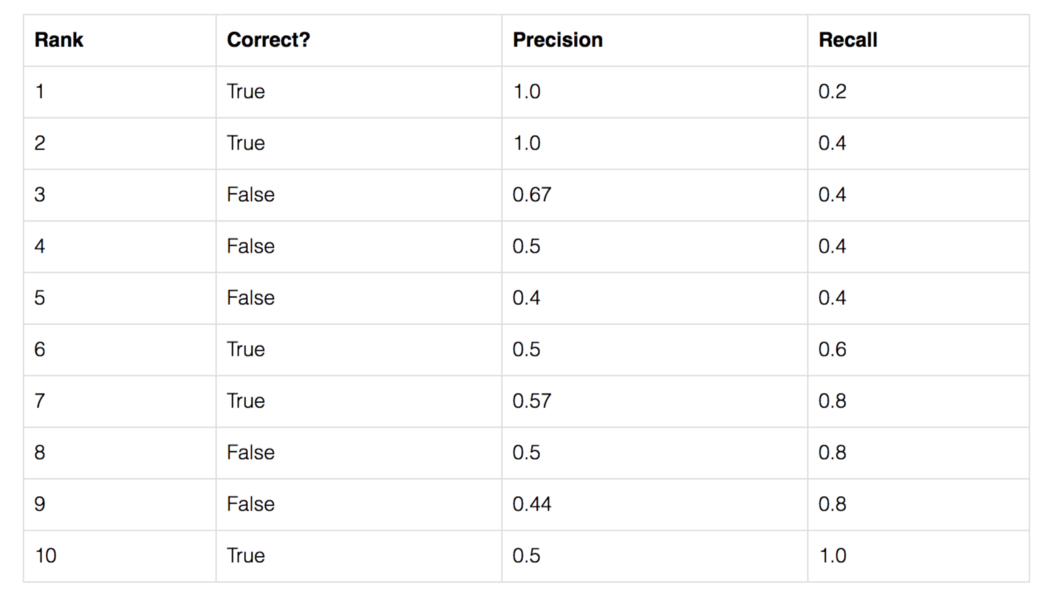
AP 让我们创建一个简化的示例来演示平均精度的计算。 在这个例子中,整个数据集只包含 5 个苹果。 我们收集所有图像中对苹果所做的所有预测,并根据预测的置信度按降序排列。 第二列表示预测是否正确。 在这个例子中,如果 IoU ≥ 0.5,则预测是正确的。
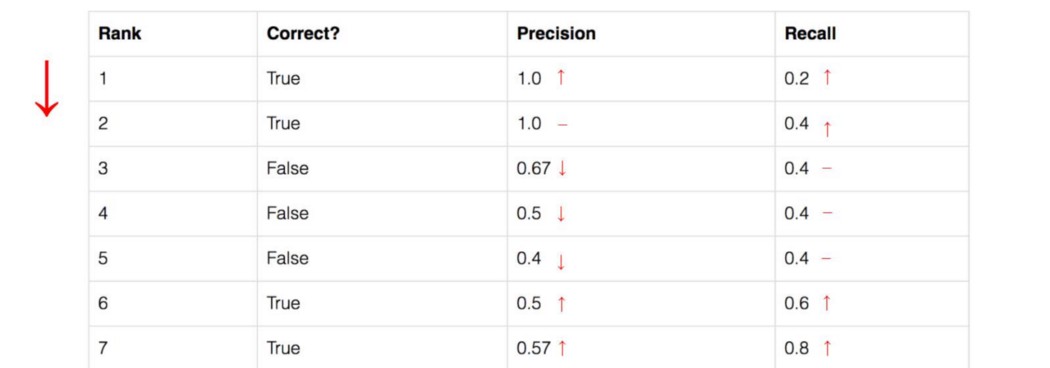
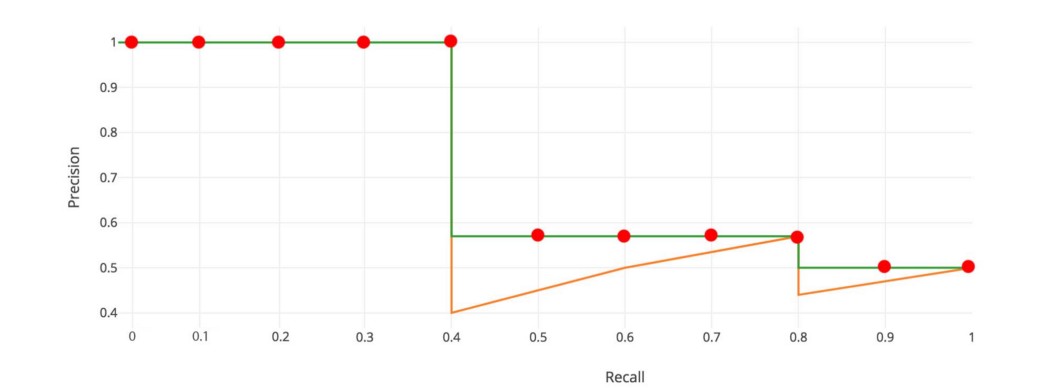
我们以排名 #3 的行为例,演示如何首先计算精度和召回率。 精度是TP=2/3=0.67的比例。 召回率是 TP 在可能的正数中的比例 = 2/5 = 0.4。 随着预测排名的下降,召回值会增加。 然而,精度有一个锯齿形模式——它会随着误报而下降,随着正样本再次上升。
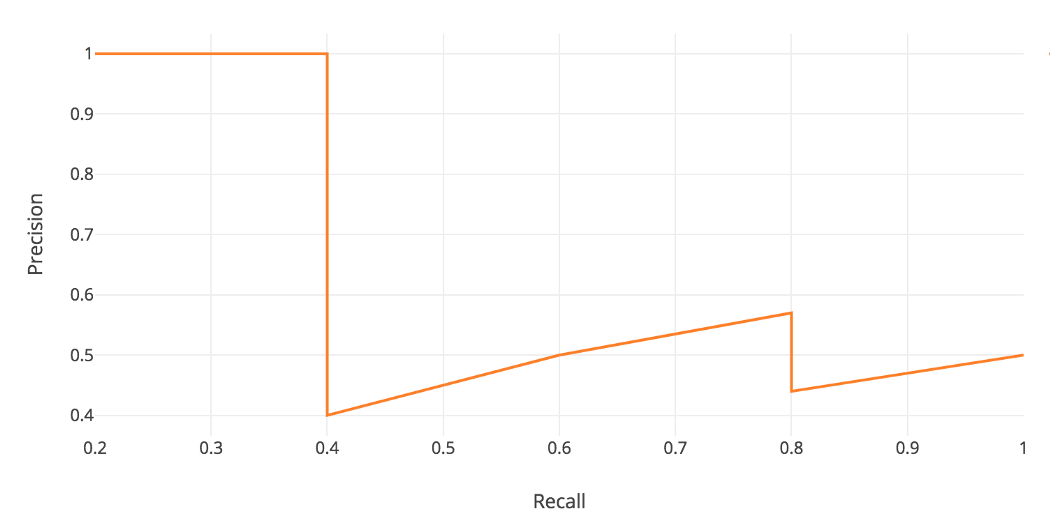
让我们根据召回值绘制精度以查看此锯齿形图案。
平均精度 (AP) 的一般定义是找到上面的精度-召回曲线下的面积。
准确率和召回率总是在 0 和 1 之间。因此,AP 也在 0 和 1 之间。 在计算目标检测的 AP 之前,我们通常先平滑锯齿形图案。
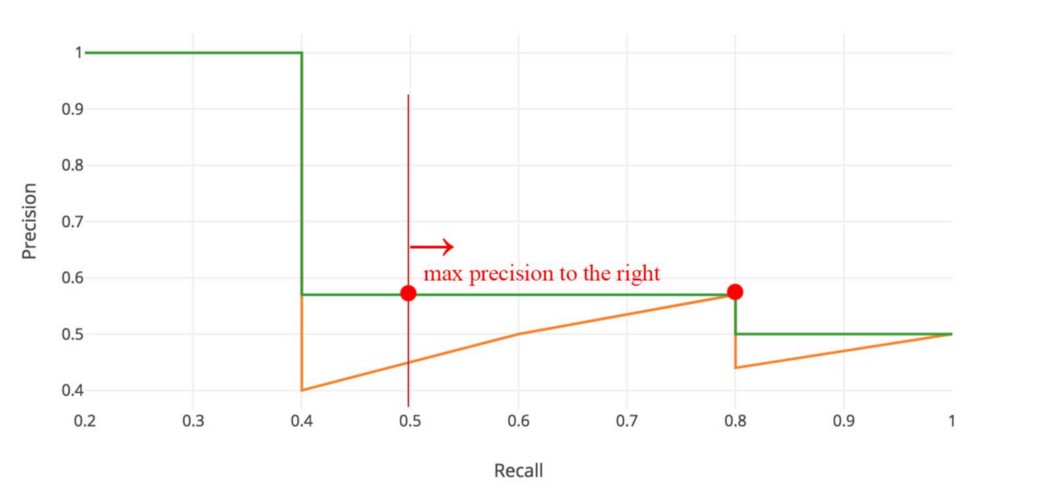
从图形上看,在每个召回级别,我们用该召回级别右侧的最大精度值替换每个精度值。
所以橙色线转化为绿色线,曲线将单调递减,而不是锯齿形。 计算出的 AP 值对排名中的微小变化的怀疑程度较低。 在数学上,我们用任何召回 ≥ ȓ 的最大精度替换召回 ȓ 的精度值。
内插AP PASCAL VOC 是一种流行的目标检测数据集。 对于 PASCAL VOC 挑战,如果 IoU ≥ 0.5,则预测为正。 此外,如果检测到同一对象的多次检测,则将第一个检测为正,其余为负。 在 Pascal VOC2008 中,计算了 11 点内插 AP 的平均值。
首先,我们将召回值从 0 到 1.0 分为 11 个点——0、0.1、0.2、……、0.9 和 1.0。 接下来,我们计算这 11 个召回值的最大精度值的平均值。
在我们的例子中,AP = (5 × 1.0 + 4 × 0.57 + 2 × 0.5)/11 这里有更精确的数学定义。
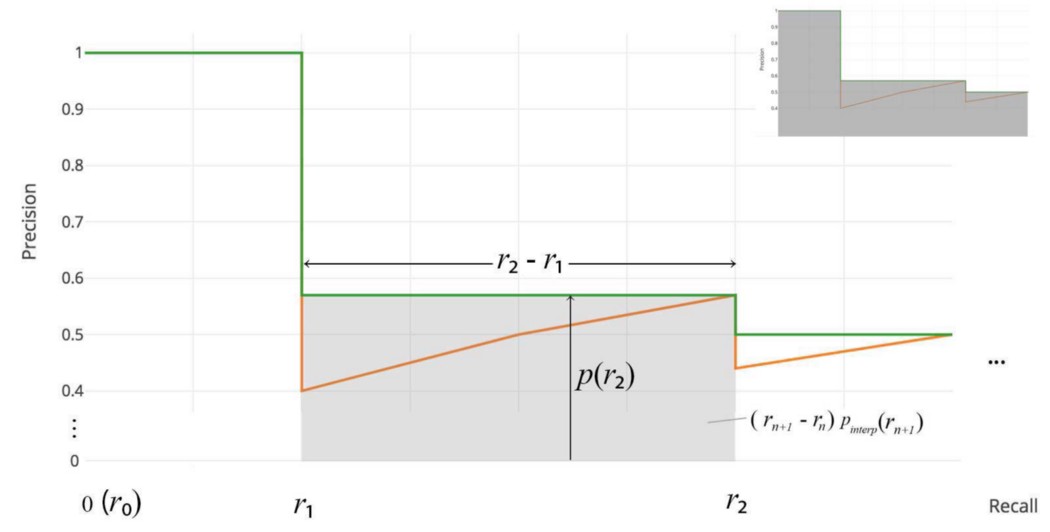
当 APᵣ 变得非常小时,我们可以假设剩余的项为零。 也就是说,在召回率达到 100% 之前,我们不一定会做出预测。 如果可能的最大精度水平下降到可以忽略不计的水平,我们可以停止。 对于 PASCAL VOC 中的 20 个不同类别,我们为每个类别计算一个 AP,并提供这 20 个 AP 结果的平均值。 根据原研究者的说法,在计算AP时使用11个插值点的意图是 “以这种方式插入精度/召回曲线的目的是减少精度/召回曲线中“摆动”的影响,这是由示例排名的微小变化引起的。” 然而,这种内插方法是一种近似方法,它存在两个问题。 它不太精确。 其次,它失去了测量低AP方法差异的能力。 因此,2008 年后对 PASCAL VOC 采用了不同的 AP 计算。 AP(曲线下面积 AUC) 对于后来的 Pascal VOC 比赛,只要最大精度值下降,VOC2010-2012 就会在所有唯一召回值(r₁、r₂、...)处对曲线进行采样。 通过这种变化,我们正在测量去除锯齿形后精确召回曲线下的确切面积。
不需要近似或插值。 我们没有采样 11 个点,而是在 p(rᵢ) 下降时采样,并将 AP 计算为矩形块的总和。
此定义称为曲线下面积 (AUC)。 如下图,由于插值点没有覆盖精度下降的地方,两种方法都会发散。
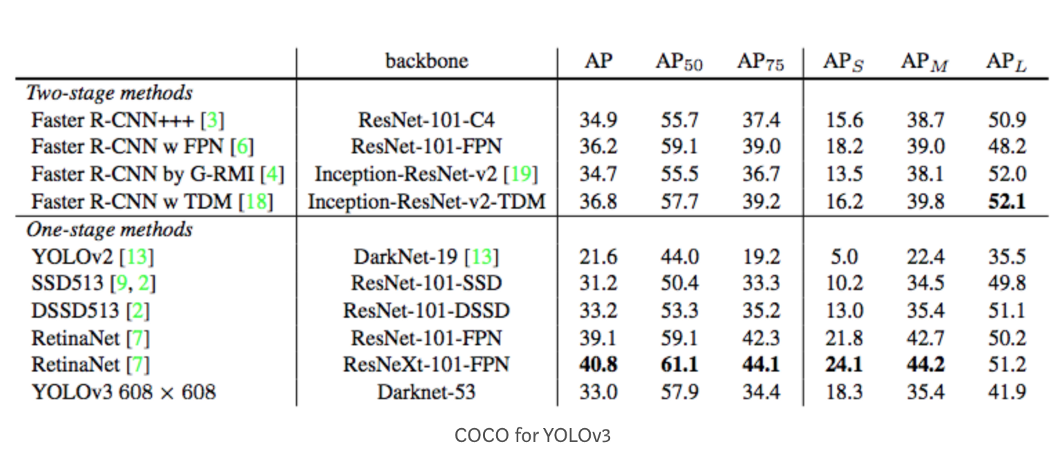
COCO mAP 最新的研究论文往往只给出 COCO 数据集的结果。 在 COCO mAP 中,计算中使用了 101 点插值 AP 定义。 对于 COCO,AP 是多个 IoU(考虑正匹配的最小 IoU)的平均值。 AP@[.5:.95] 对应于 IoU 从 0.5 到 0.95 的平均 AP,步长为 0.05。 对于 COCO 比赛,AP 是 80 个类别的平均超过 10 个 IoU 级别(AP@[.50:.05:.95]:从 0.5 开始到 0.95,步长为 0.05)。 以下是为 COCO 数据集收集的其他一些指标。
并且,这是 YOLOv3 检测器的 AP 结果。
上图中,AP@.75表示IoU=0.75的AP。 mAP(mean average precision)是AP的平均值。 在某些情况下,我们计算每个类的 AP 并将它们平均。 但在某些情况下,它们的意思是一样的。 比如在COCO上下文下,AP和mAP没有区别。 以下是 COCO 的直接引述: AP 是所有类别的平均值。 传统上,这被称为“平均精度”(mAP)。 我们不区分 AP 和 mAP(以及 AR 和 mAR),并假设从上下文中可以清楚地看出区别。 在 ImageNet 中,使用了 AUC 方法。 所以即使它们都遵循相同的测量AP原则,精确的计算可能会因数据集而异。 幸运的是,开发组件可用于计算此指标。 |