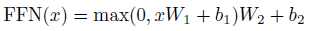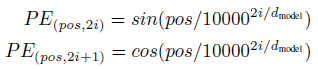|
使用Transformer,Attention 性能优于ByteNet、Deep Att、GNMT和CONVS2
Attention Is All You Need 在本文中,Attention Is All You Need,(Transformer),由谷歌大脑,谷歌研究院,和多伦多大学审查。在本文中:
这是2017年NeurIPS的一篇论文,引文超过31000篇。Transformer是一种非常著名的深度学习体系结构和技术,因为Transformer后来扩展到文本以外的模式,如图像、视频和音频:NL:非局部神经网络、图像Transformer、SAGAN。 概述
1.Transformer:模型架构
Transformer:模型架构 1.1. 框架
Transformer遵循这种整体架构,使用堆栈的self-attention 和 point-wise,编码器和解码器的全连接层。 1.2. 编码器 编码器由N=6个相同层的堆栈组成 每层有两个子层。第一种是多头自我注意机制,第二种是简单的、位置相关的全连接前馈网络。
1.3. 解码器 解码器也由N=6个相同层的堆栈组成。 除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头注意。
2.多头Attention
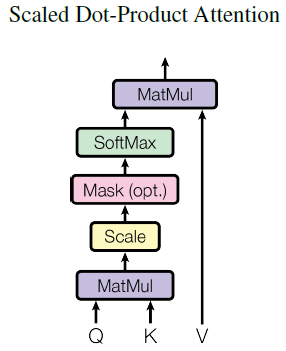
2.1. Scaled Dot-Product Attention
Scaled Dot-Product Attention (1-Head,Mask layer可选,仅用于解码器) 2.1.1.程序 输入包括维度dk的queries 和keys 以及维度dv的values 。 计算 query与所有keys的点积,每个点积除以√(dk),并应用softmax函数来获得这些values的权重。
2.1.2.使用Dot Product Attention而非Addition Attention的原因
虽然两者在理论复杂性上相似,但由于可以使用高度优化的矩阵乘法代码来实现,因此在实践中,点积注意速度更快,空间效率更高。
2.2. 多头Attention
Multi-Head Attention 与使用dmodel维度keys, values和queries执行单一注意功能不同,我们发现使用不同的学习线性投影将keys, values和queries线性推断h次,分别投影到dk、dk和dv维度是有益的。
3.在Transformer中Attention的应用
Left: Encoder-Decoder Attention, Middle: Self-Attention at Encoder, Right: Masked Self-Attention at Decoder 回到整体框架,Transformer以三种不同的方式使用了多头注意(3个橙色块):
4.位置前馈网络
位置前馈网络 除了attention 子层之外,编码器和解码器中的每一层都包含一个全连接的前馈网络,该网络由两个线性变换和一个ReLU激活层组成:
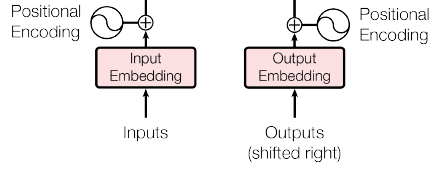
5.其他细节 5.1. Embeddings and Softmax 学习的Embeddings用于将输入tokens和输出tokens转换为维度dmodel的向量。
5.2. 位置编码
Positional Encoding at Encoder (Left) and Decoder (Right)
使用不同频率的正弦和余弦函数:
5.3. 为什么Attention
Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types 有三个因素促使self-attention的使用:
一个self-attention层用一个恒定数量的顺序执行的操作连接所有位置,而一个recurrent层需要O(n)个顺序操作。 在计算复杂度方面,当序列长度n小于表示维数d时,self-attention层比recurrent层快 kernel宽度k<n的单个卷积层不能连接所有输入和输出位置对。在连续kernel的情况下,这样做需要O(n=k)个卷积层的堆栈,或者在扩展卷积的情况下需要O(logk(n))个卷积层的堆栈。 6.实验结果 6.1. 数据集
6.2. SOTA比较
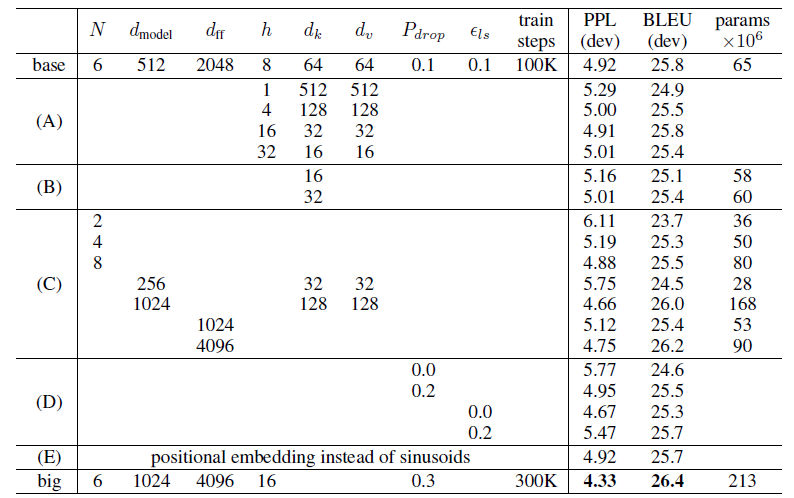
English-to-German and English-to-French newstest2014 tests 使用Beam尺寸为4的Beam搜索,长度惩罚α=0.6。 在WMT 2014年英语到德语翻译任务中,big transformer模型(big transformer)的BLEU分数超过了之前的最佳模型(包括ensembles),达到了28.4分。在8个P100 GPU上进行训练需要3.5天。 即使是基本模型也超过了之前发布的所有模型,如ByteNet、Deep Att、GNMT和Convs2。 在WMT 2014英法翻译任务中,提出的大模型的BLEU分数为41.0,优于之前发布的所有单一模型,训练时间不到之前最好模型的1/4。 6.3. 模型变体
Variations on the Transformer architecture on the English-to-German translation development set, newstest2013 (Unlisted values are identical to those of the base model) A.单头注意力比最佳设置差0.9个BLEU,质量也会随着头部过多而下降。
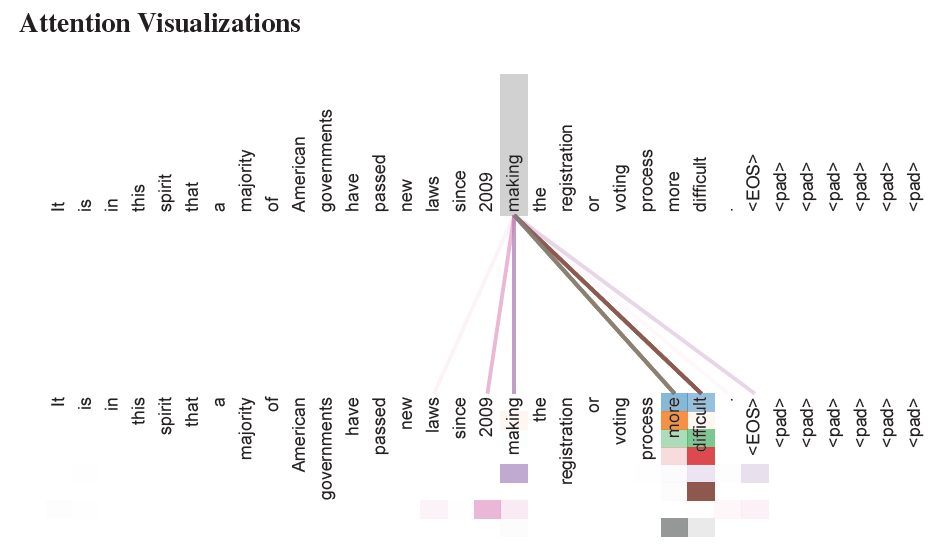
English Constituency Parsing on Wall Street Journal (WSJ) 在这项任务中,输出强烈受到结构约束,并且显著长于输入。 一个dmodel=1024的4层 transformer在 Penn Treebank[25]的Wall Street Journal(WSJ)部分训练,大约有40K个训练句子。 该Transformer可以很好地推广到英语候选分析。 6.5. Attention可视化
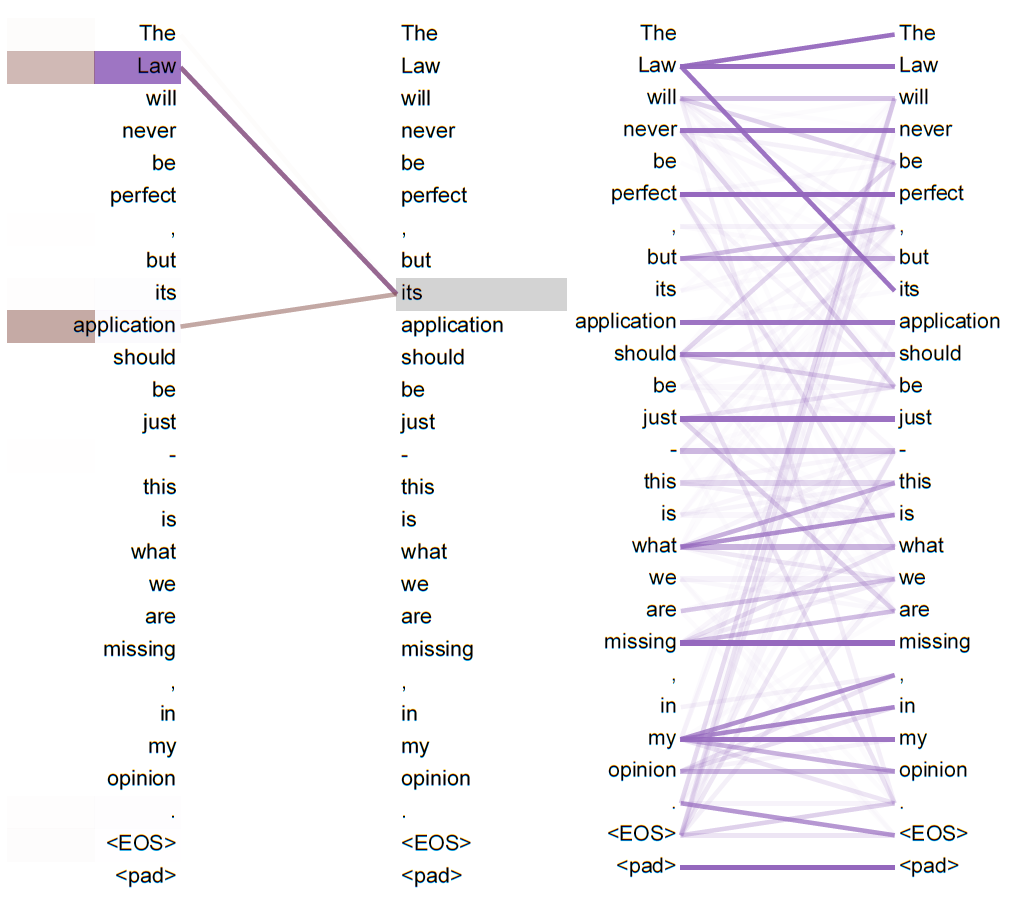
An example of the attention mechanism following long-distance dependencies in the encoder self-attention in layer 5 of 6 许多 attention heads注意到动词“making”的一个较远的依赖关系,完成短语“making…more difficult”。这里显示的attention仅针对“making”一词。不同的颜色代表不同的头部。
Two attention heads, also in layer 5 of 6, apparently involved in anaphora resolution 顶部:Full attentions for head 5 底部:对于attention heads5和6,仅从“its”一词中分离出attentions。 |