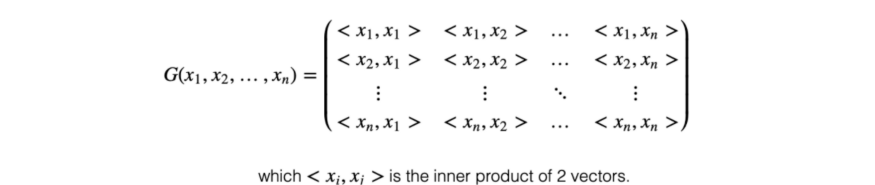在这篇文章中,我们创建了几个TensorFlow模型,其中包括以下几个:
DGCNN DGCNN是GAN网络中最受欢迎的网络设计之一,它由卷积层和转置卷积层组成,没有max pooling或fully connected层。下图是生成器的网络设计。对此进行训练,生成MNIST数字。我们将从这个最基本的GAN模型开始。
MNIST样本的数据集设置:
这是一个generator,我们不会对他做太多的注释,因为网络上有很多的讲解。
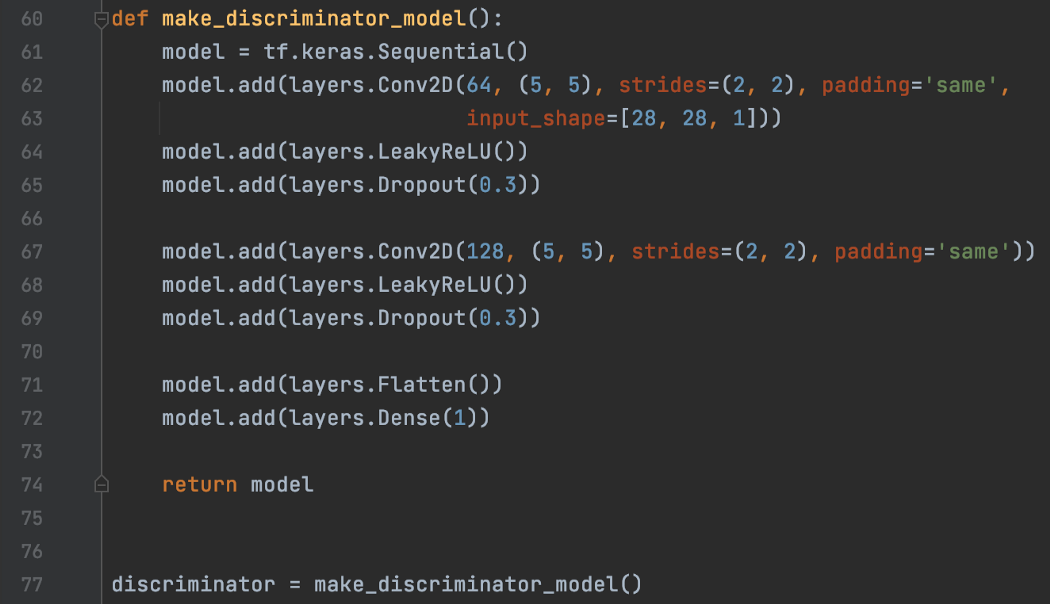
Discriminator:
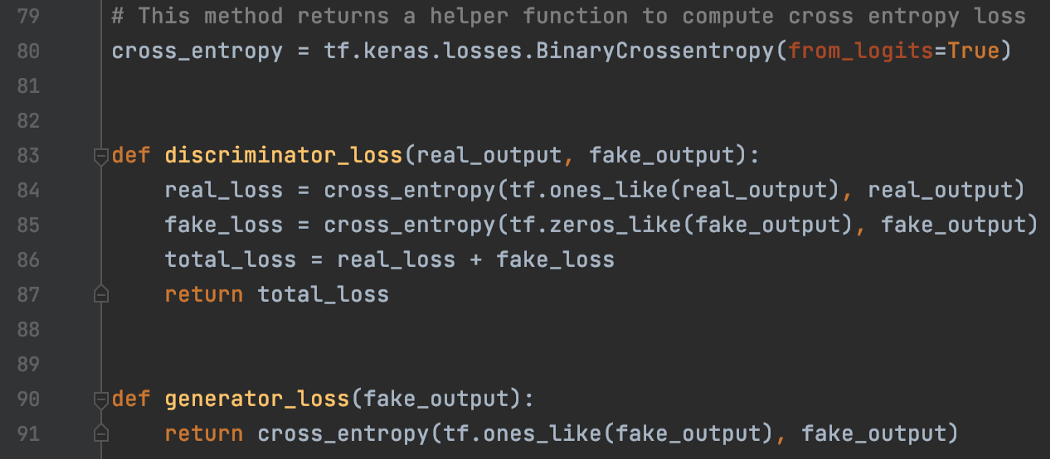
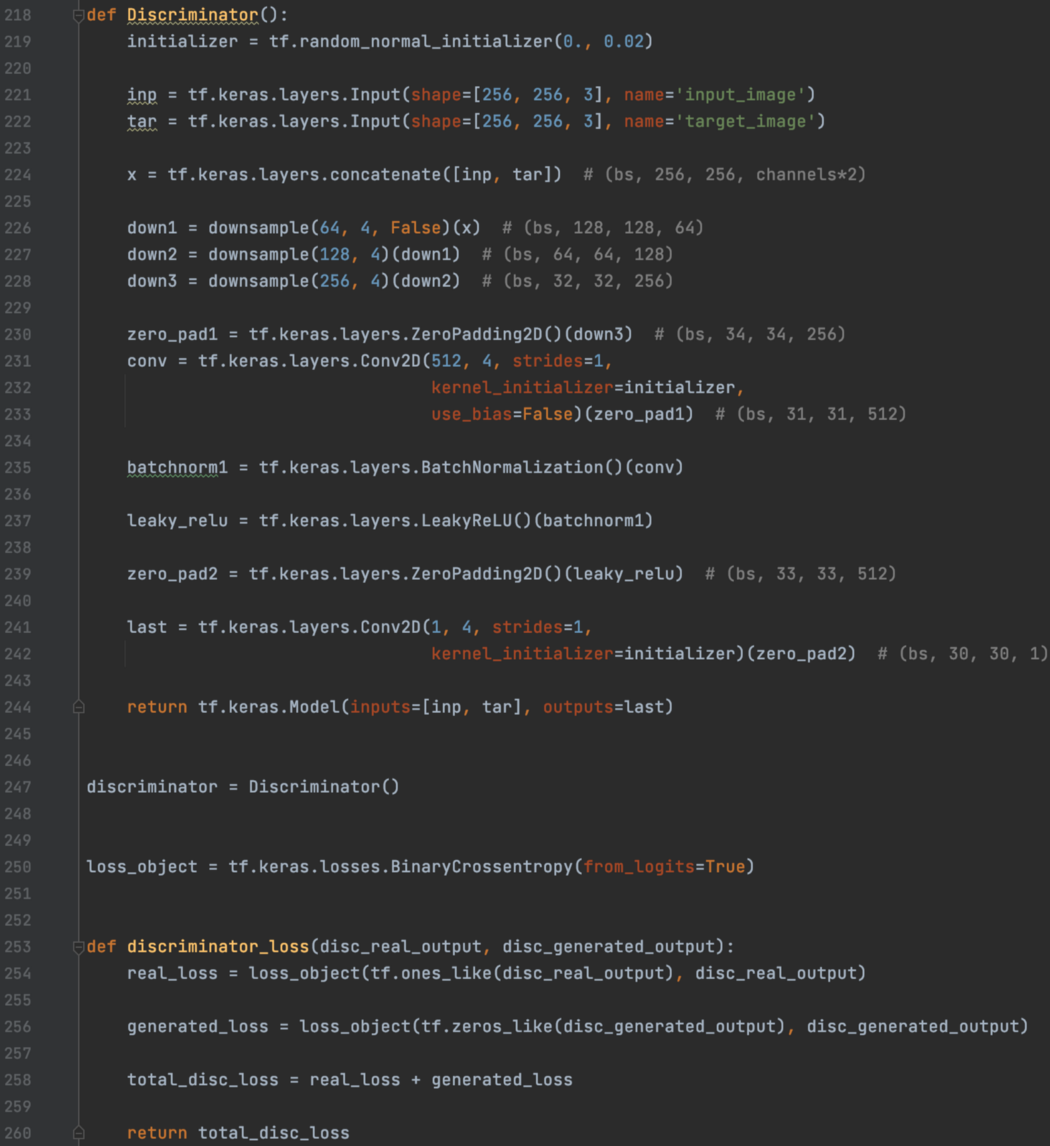
这是损失函数。对于discriminator,我们期望真实图像被标记为1,生成的图像为0。对于generator 损失,我们希望discriminator 将其分类为1。
优化器 和 the checkpoint:
以下是训练步骤:
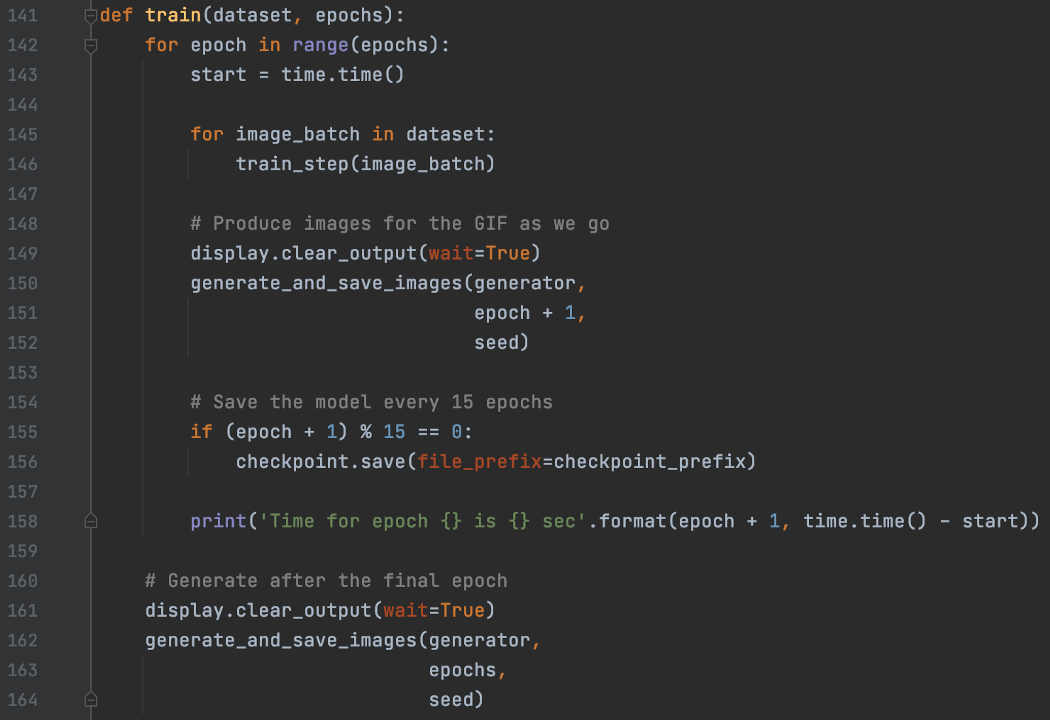
训练loop:
接下来,我们开始训练模型。首先,我们随机抽样16个z值。在每个epoch训练结束时,我们为这16z值生成16幅图像。我们保存这些图像,一旦训练完成,我们将它们拼接成一个GIF动画。因此,对于每个采样z,我们可以看到生成的图像是如何随着训练的进展而变化的。
这是显示训练进度的动画:
CycleGAN CycleGAN是应用深度网络G将一种图像转换成另一种类型,例如从照片到梵高类绘画。为了训练这个模型,我们还训练了一个判别器来区分真正的梵高画和生成的画。我们还训练了另一个深层网络F来恢复原始图像。对整个模型进行了训练,以降低generator和discriminator 的loss以及reconstruction的loss。所以,G会把一种图像转换成另一种,即使是discriminator D也很难从真实的图像中区分出来.
下面是一些将一种图片转换为另一种图片的应用程序:
这是一般的设置和samples准备。在本例中,我们将马的图片转换为斑马。
在本文中,我们将不详细介绍TensorFlow中常见的sample代码. 图像准备和数据增强:
准备数据集:
下面是TensorFlow_examples.model中的generator 和discriminator 模型。
这是损失函数。它由generator loss和discriminator loss组成。它还有两个损失函数。cycle loss是一种reconstruction loss。下面的“real x”是一个真实的马图像,而“real y”是一个真实的斑马图像。如果一匹真正的马通过G和F,我们应该得到马的图像。如果我们通过一个真正的斑马通过F和G,我们应该得到斑马回来。什么是身份损失?把马变成斑马。但是如果我们把斑马喂给G,我们仍然应该正确地处理它并生成斑马。身份的丧失确保了。这是损失函数。
优化器和checkpoints 代码:
我们将训练40epoch的模型。下面是从马的图像生成斑马图像并绘制出来的代码
训练步骤的第一部分是为不同的场景生成图像并计算相关的损失。
第二部分采用梯度下降法。
训练loop与图像生成:
以下是可能的结果。但要准备更长时间的训练。
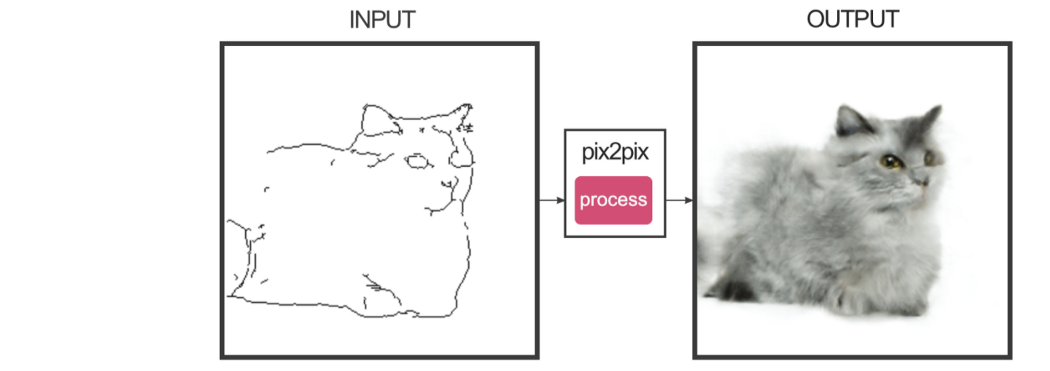
Pix2Pix Pix2Pix生成给定条件图像x的图像。此图像指导要生成的图像。
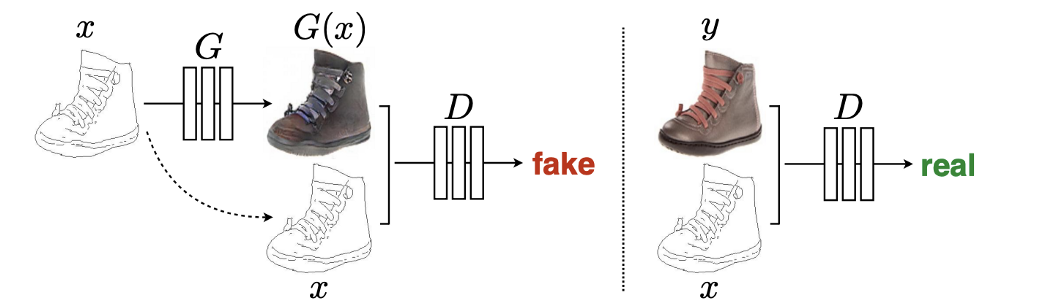
和其他GANS一样,它训练一个discriminator 来区分真实的和生成的,并从这个条件图像中添加额外的输入:
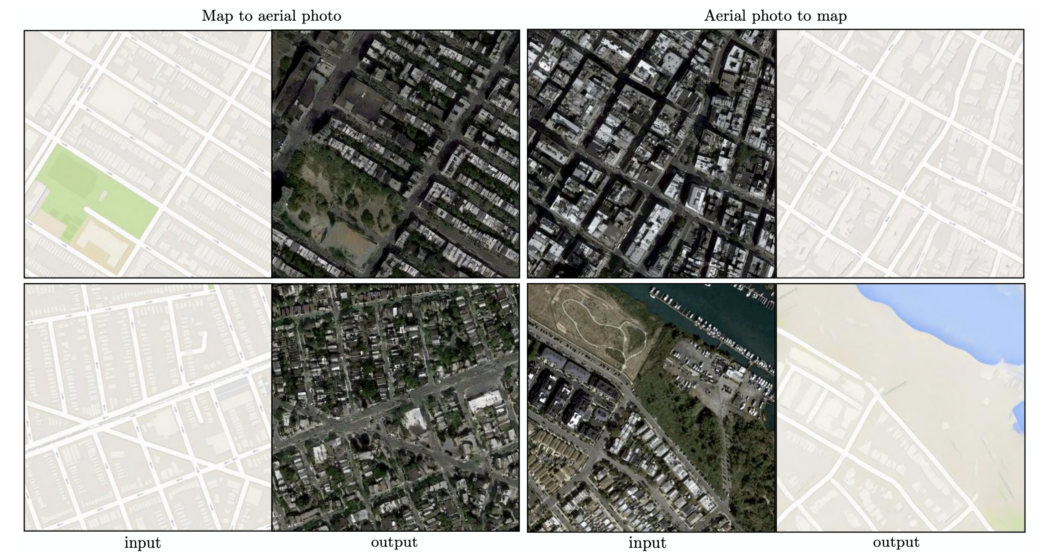
以下是其他一些潜在的应用:
数据文件设置:
以下是加载、操作和增强图像的功能:
接下来,我们准备数据集:
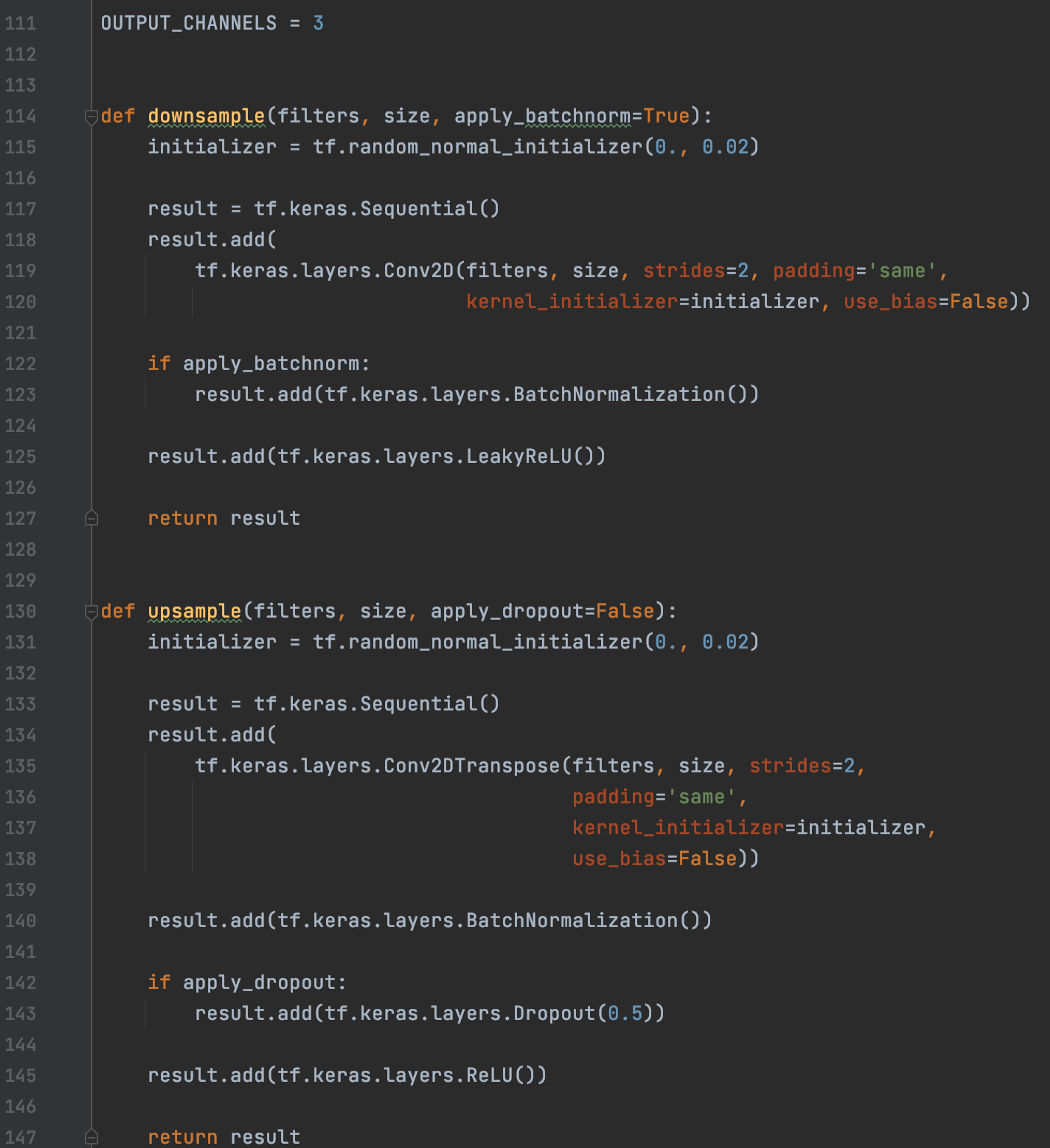
这里是使用卷积和转置卷积的下采样和上采样层。:
这是generator。跳过连接以相同的空间分辨率从下采样层应用到上采样层。
下面是一些跳过的连接:
The generator loss:
这里是discriminator 和损失函数。
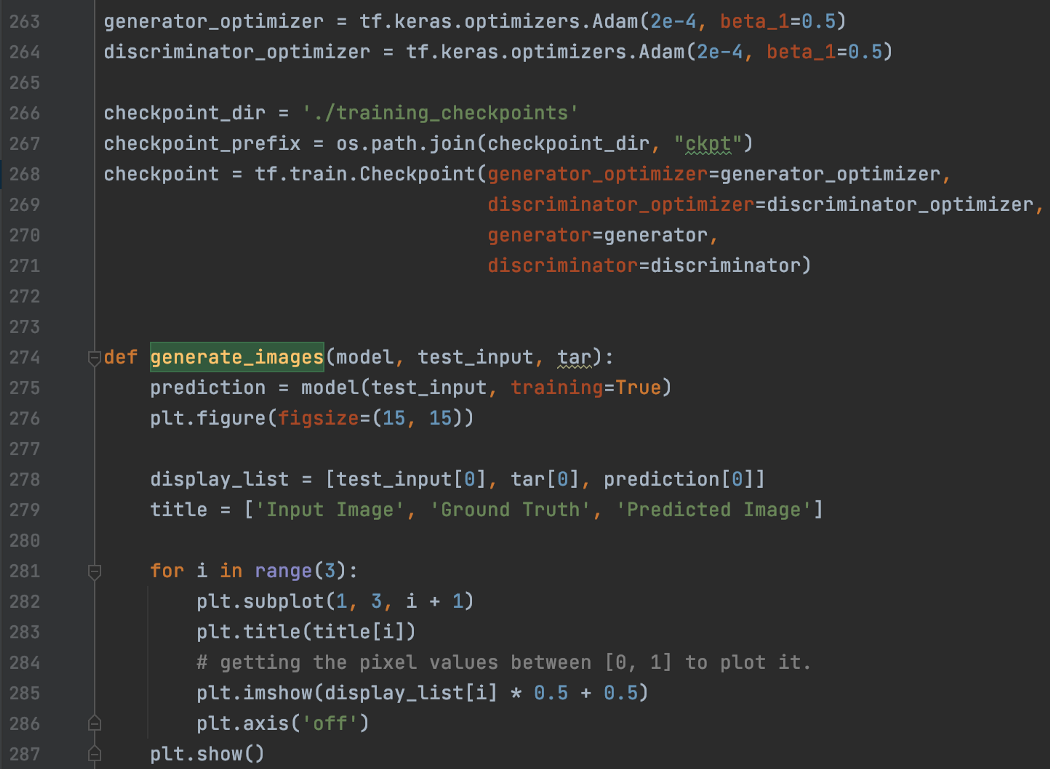
使用带有条件测试图像的模型生成图像的优化器、checkpoint,和实用函数
Generate_Image还绘制了一个样本、它的实际情况和模型预测。:
Training step:
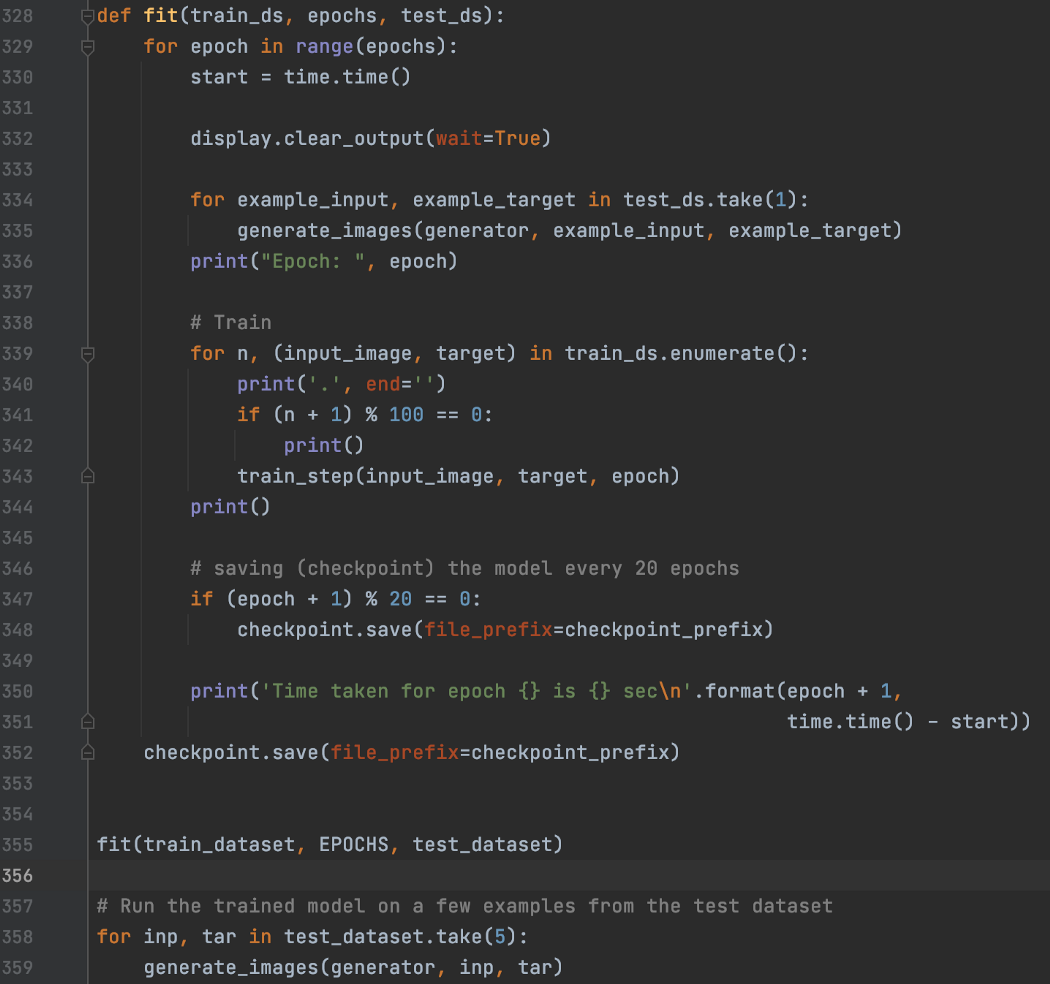
训练和图像生成:
以下是一些生成的图像:
Neural style transfer “Neural style transfer”将图像的样式转移到另一个图像上,同时保持其图像内容不变。
在本例中,我们使用vgg 19从目标内容图像中提取内容特征,并从目标样式图像中提取样式特征,然后,我们使用内容映像作为起始。我们提取源内容和样式特征,并将它们与目标内容和目标样式特征进行比较。计算相应的均方误差(MSE),利用损失梯度将源图像推到目标样式,同时保持内容特征与原始图像接近。 设置:
以下是加载和显示图像的实用代码。
我们可以下载一个预先训练的TF Hub模型的风格转移。
这是一幅用一种绘画风格改变了的狗画。
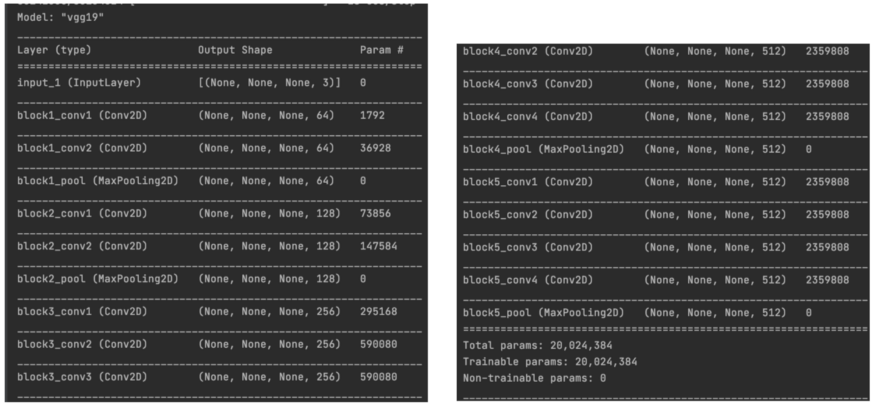
接下来,我们将重新做这个练习。这一次,我们使用一个VGG 19模型(没有分类头)来提取特征并构建代码来执行样式转换。下图是模型摘要。
我们使用更接近输入层的特性来捕获样式(颜色、笔画样式等…)。以及更接近于内容信息输出的特性。
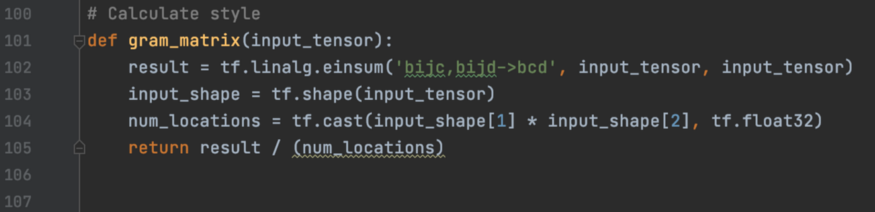
图像的样式特征是一个度量特征之间关系的Gram矩阵。例如,某些笔画与某些颜色的关系。
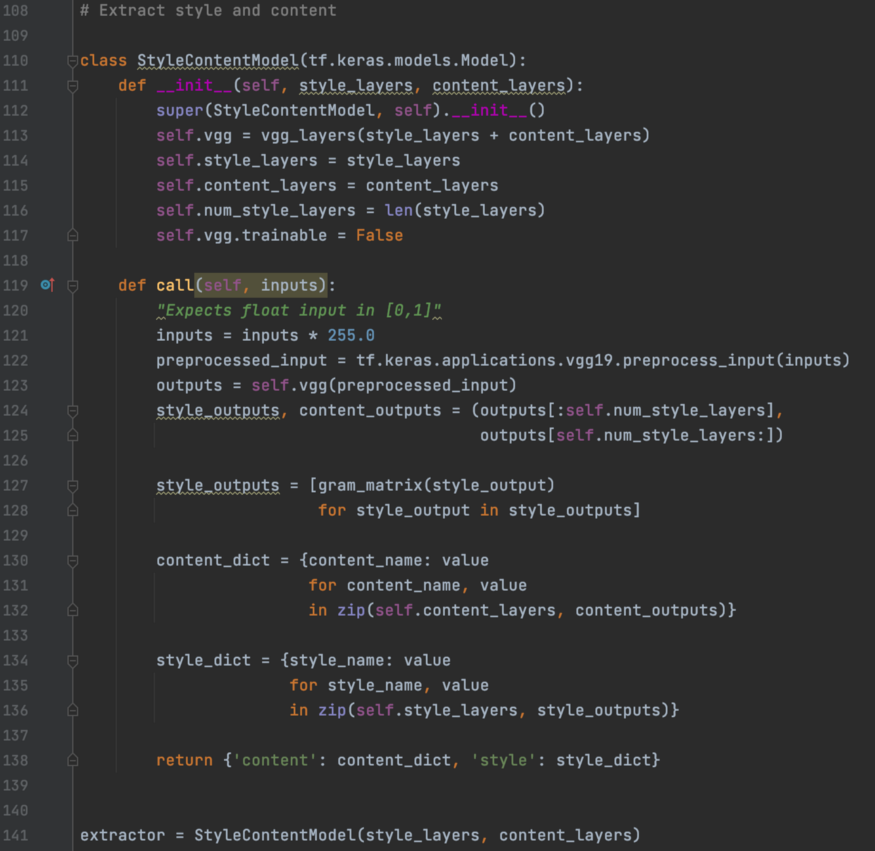
最后,我们建立了一个模型来提取图像的内容和风格特征。
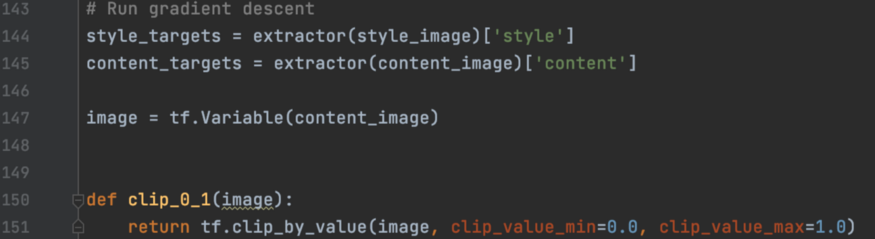
接下来,我们从样式图像中提取样式,从内容图像中提取内容。从内容图像作为神经类型迁移的来源。我们也有一个剪辑函数,以确保生成的像素在0和1之内。
我们的总损失是对新生成的图像与目标样式和目标内容之间的样式和内容特征进行加权MSE。
通过渐变下降,我们的训练在减少风格和内容损失方面推动生成的图像。
但是所生成的图像是有噪声的。因此,我们增加了一个变化损失,以减少噪音。首先,我们将图像左上角移动一个像素。然后,我们计算绝对差。差分信号显示高频区域.我们总结这些高通信号,这样我们就可以将可训练的权重转移到更平滑的图像上。
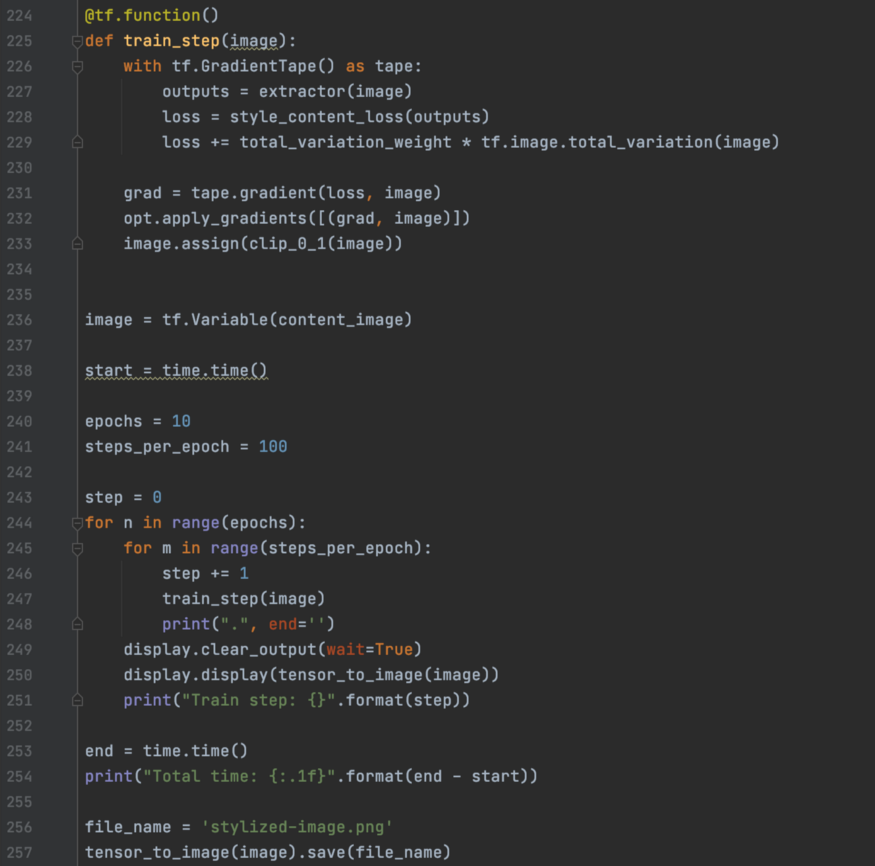
这是附加变分损失的训练loop。但是,我们使用的是内置的tf.Image.Total_Variation,而不是上面的自定义方法。
下面是一个样式传输图像的示例。
|