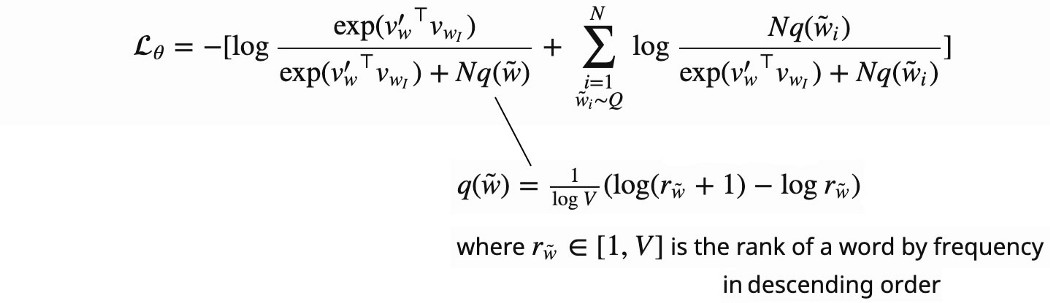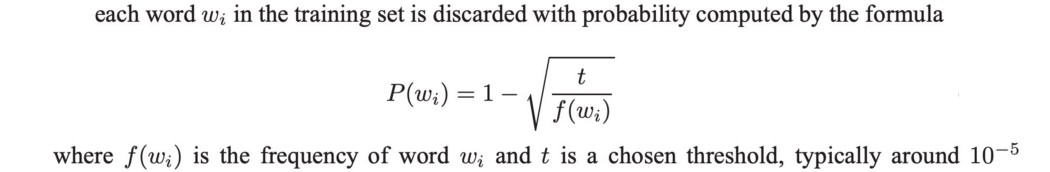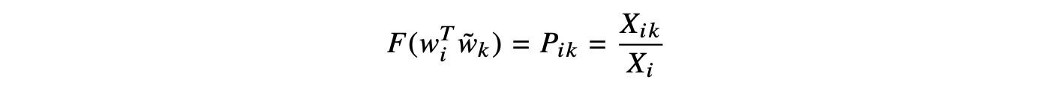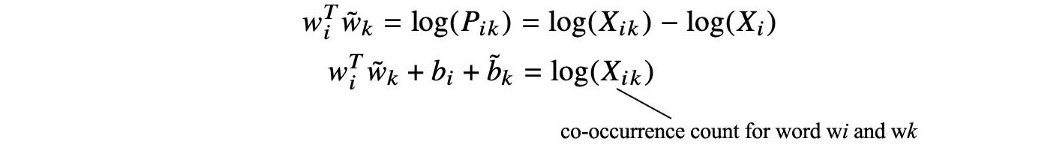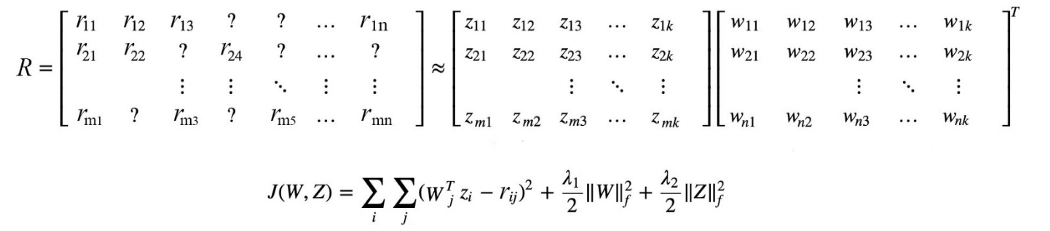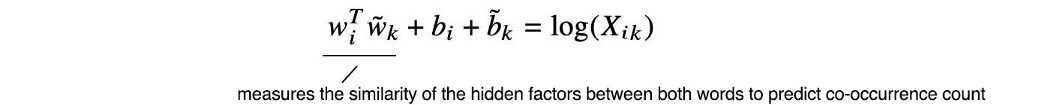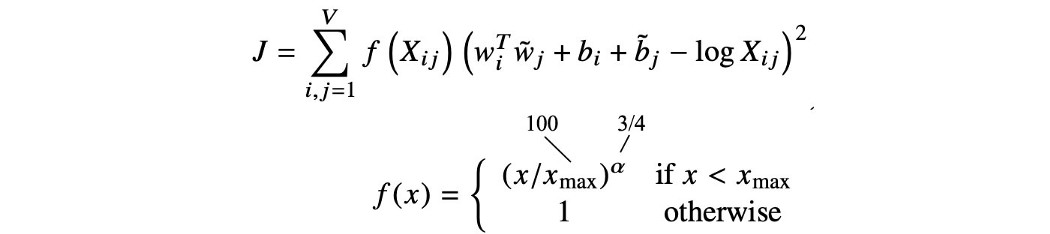|
BERT 是为句子创建向量表示的一个重要里程碑。 但是,我们不会立即介绍 BERT 的确切设计,而是从词嵌入开始,最终将我们引向 BERT之美。 如果我们了解旅程,我们就能更好地理解,并帮助我们解决其他问题。 由于词嵌入是深度学习 (DL) NLP 的基础,我们的第一篇文章将首先介绍它。 词嵌入 有些词经常成对出现,比如nice and easy或pros and cons。 因此,语料库中单词的共现可以教会我们一些关于其含义的信息。 有时,这意味着它们相似,有时意味着它们相反。 在词嵌入中,你与谁联系谁会告诉你你是谁。 我们可以将“hen”一词描述为:
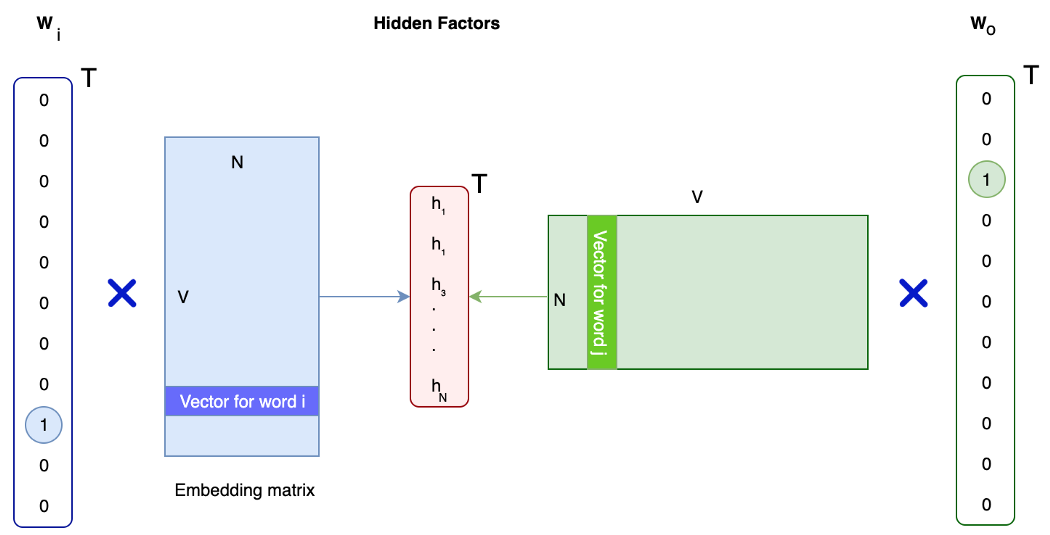
直观地说,我们可以创建一个描述单词的属性列表。然而,手动定义一套通用的属性来容纳词汇表中的所有单词是不可能的。 Word Embedding 是一种用于导出单词向量表示的深度学习 DL 方法。例如,单词“hen”可以用 512D 向量表示,例如 (0.3, 0.2, 1.3, ...)。从概念上讲,如果两个词相似,它们在这个投影向量空间中应该有相似的值。 如果我们用 one-hot 向量对一个词进行编码,一个 40K 词的词汇表需要一个 40,000-D 向量。在这个向量中,只有一个分量等于 1,而其他分量都为零。这个非零分量标识一个唯一的词。这是非常低效的,但它是寻找更密集表示的良好开端。 让我们强制执行另一个约束。我们使用线性变换将这个 one-hot 向量投影到这个更密集的表示中。即,为了创建向量 h,我们将 one-hot 向量与矩阵相乘。向量 h 的维度要低得多,我们将 one-hot 向量投影到这个向量空间中。 给定下面两个单词 wᵢ 和 wₒ,如果它们相似,我们希望它们在投影空间中尽可能接近。
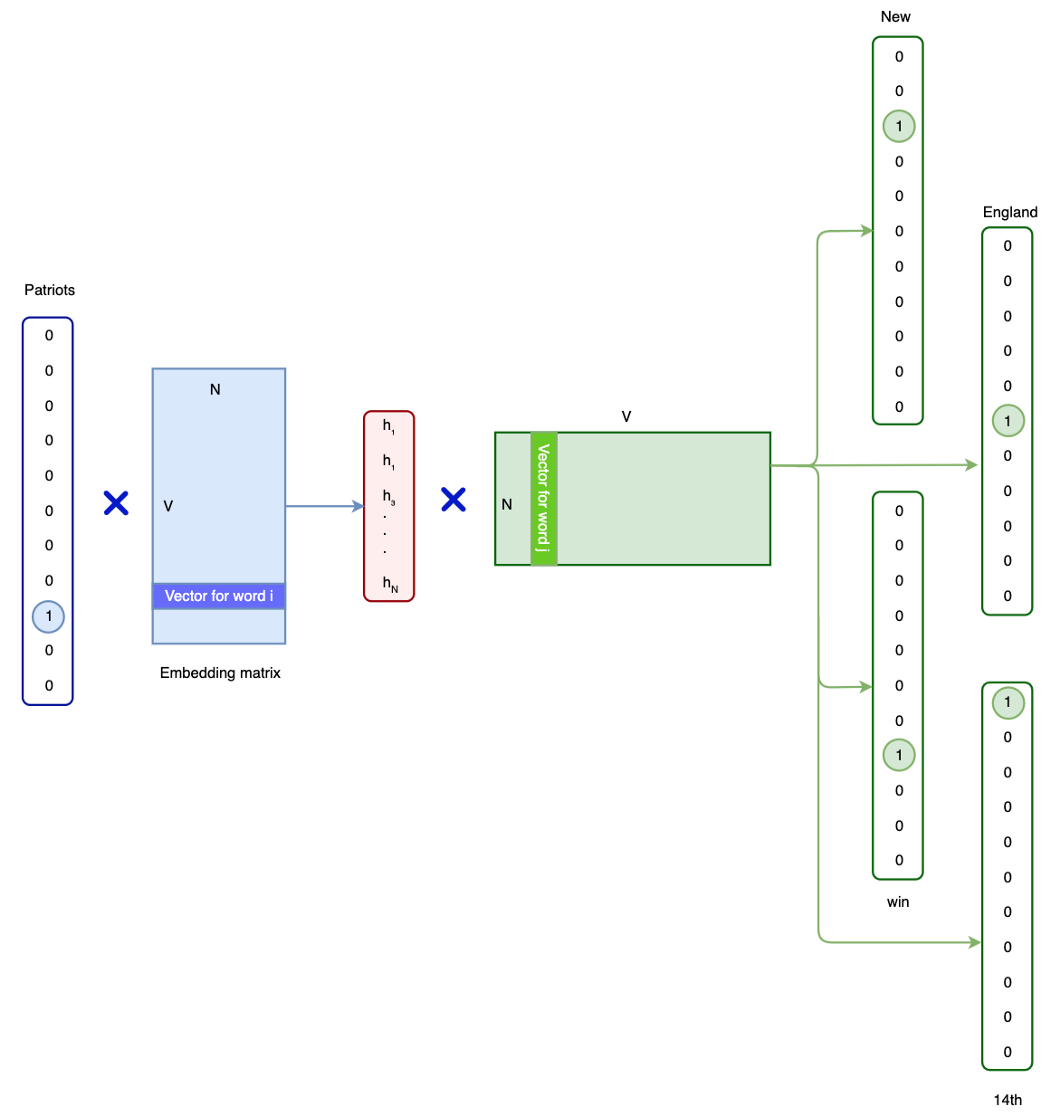
我们可以稍微不同地概念化这个问题。 让我们从 wᵢ 这个词开始。 我们首先用嵌入矩阵计算它的向量表示。 然后,我们将它与另一个矩阵相乘以预测另一个与之相似的单词,比如 wₒ。 输出不会是单热向量。 但是我们可以运行一个 softmax 来找到最有可能的词。 这在链接与 wᵢ 相关的单词时创建了一个很好的概念。 它给我们带来了什么? 相关词的手动标记是昂贵的。 相反,我们解析文本语料库并使用上下文窗口内的共现词(比如在 2 个词范围内)作为我们的训练数据。 我们的重点是学习第一个嵌入矩阵来为一个词创建一个密集的向量表示。 但是有两种可能的方法来做到这一点。 Skip-gram model 第一个是skip-gram模型。 给定一个词,我们可以预测它在文本语料库中的相邻词吗? 比如说,我们使用 5-gram 模型(5 个连续单词)。 给定“Patriots”这个词,我们可以用训练数据预测相邻的词吗,比如: New England Patriots win 14th straight regular-season game at home in Gillette stadium. 在下图中,我们在词嵌入模型中拟合了“Patriots”一词的 one-hot 向量。 它产生 4 个关于其可能邻居的预测。
给定目标词 t(“Patriots”)的预测词的对数似然将是:
对于这个 5-gram 模型,我们要预测右侧的这 4 个单词。
为了计算概率 p(wₒ | wᵢ),我们在相应的矩阵中找到与 wᵢ 和 wₒ 相关的相应行和列条目。 然后,条件概率可以计算为:
使用点积测量相似度。 我们训练模型使得两个相似的词应该产生最大的点积值。 分母将所有分数加在一起,以将分子重新归一化为概率值。 简而言之,对于相似的词,我们将它们的向量表示更接近。 我们希望这对与涉及 wI 的其他组合对相比具有最大的相似性。 连续词袋(CBOW) 第二个概率是 CBOW。 给定上下文,我们想要预测目标词。 例如,给定“New”、“England”、“win”和“14th”,我们想要预测目标词“Patriots”。
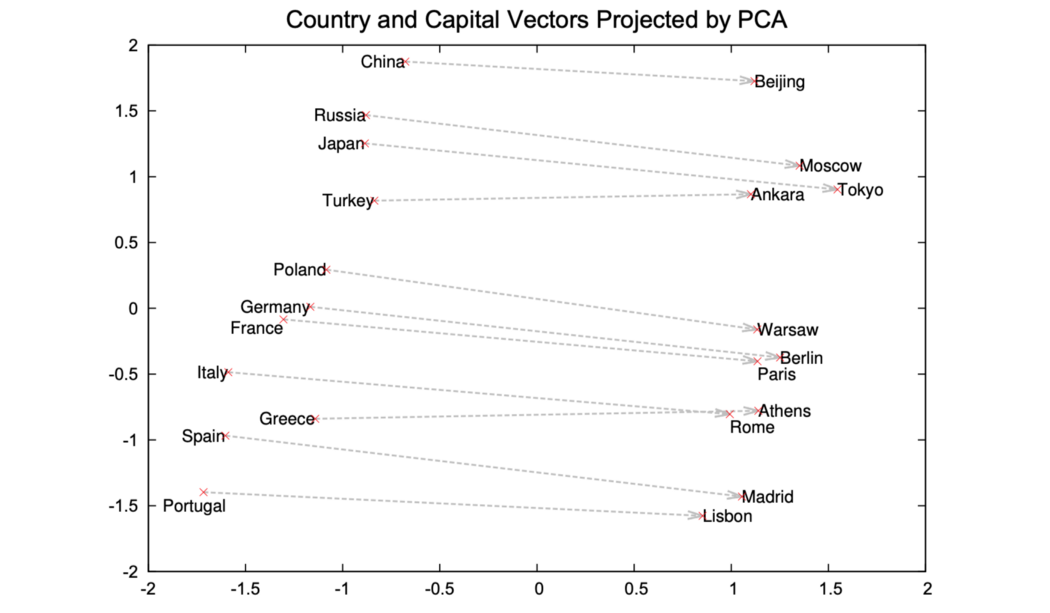
Vector Arithmetic 让我们将关于训练的讨论推迟一秒钟,并首先检查这些经过训练的向量。 由于在高维空间中可视化向量太难,我们使用 PCA 将其投影到二维空间中。 该图绘制了这个二维空间中的一些单词。 一个重要的观察是,这个过程可以用简单的线性代数发现单词关系!
例如,
这就是词嵌入的魅力,因为我们创建了一个简单的线性数学模型来对词进行语义操作。 如果我们知道波兰、北京和中国的矢量表示,我们就可以回答诸如波兰首都是什么之类的问题。 这种线性行为主要是通过使用矩阵(线性模型)将单词投影到密集空间中产生的。 接下来,我们将详细检查训练的成本函数。 交叉熵 假设我们使用的是二元组(2-gram)模型,则基本事实和预测之间的交叉熵将为。
如上式所示,中间的项希望最大化我们观察到的词对(分子)之间的分数,同时最小化涉及 wI(分母)的其他词对之间的分数。 损失函数的梯度为:
我们可以从分布 Q(即分布 p(wi|wI))中抽取样本来估计第二项。 这是个好消息,因为我们找到了一种估计方法,而不是用 wI 计算所有可能的词对的确切值。 噪声对比估计 (NCE) 如果我们将训练视为逻辑回归问题,则词嵌入的损失函数为:
即,我们希望将基本事实分类为真实,而将其他事实分类为虚假。 这类似于交叉熵,损失函数变为:
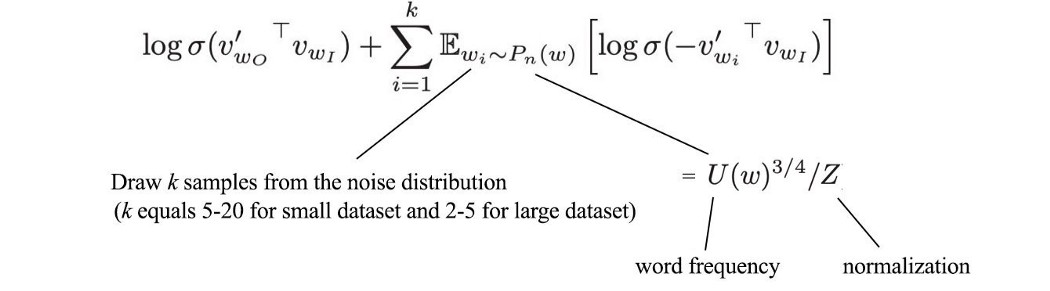
从 Q (p(wi|wI)) 采样并不是那么简单。 对于一些不太常见的词对,我们需要一个大的语料库来使估计更准确。 甚至有可能训练数据集中可能不存在合法词对。 但是在上面的等式中,我们可以将 Q 简化为 q,其中 q 是单个单词根据其在语料库中的出现排名的单词分布。 由于它仅依赖于单个单词,因此使用较少的语料库数据更容易进行估计。 负采样 (NEG) NEG 是 NCE 的一种变体,我们将逻辑函数应用于相关性得分。 因此,我们没有将其视为回归问题(估计条件概率),而是将其视为分类问题。
对应的目标函数变为:
这是词嵌入训练中使用的函数。 在接下来的几节中,我们将讨论一些实现细节。 频繁词的二次抽样 要选择训练集中的单词 wI 作为下一个训练数据,我们可以使用以下等式选择样本数据:
显然,我们选择频率更高的词。 设计权衡 以下是词嵌入的不同权衡和决策选择。 例如,我们应该使用 skip-gram 还是 CBOW? 以下是 Google 团队的一些建议。
GloVe(全局向量) GloVe 是另一种词嵌入方法。 但它使用不同的机制和方程来创建嵌入矩阵。 为了研究 GloVe,我们首先定义以下术语。
并且共现概率的比率为:
这个比率让我们对探测词 wk 与词 wᵢ 和 wⱼ 的共同关系有了一些了解。
给定一个探测词,该比率可以小、大或等于 1,取决于它们的相关性。 例如,如果比率很大,则探测词与 wᵢ 相关,但与 wⱼ 无关。 这个比率为我们提供了三个不同单词之间关系的提示。 直观地说,这介于二元组和三元组之间。 现在,我们想为 F 开发一个模型,给定我们想要的嵌入向量 w 的一些理想行为。 如前所述,线性在词嵌入概念中很重要。 因此,如果一个系统根据这个原则进行训练,我们应该期望 F 可以重新表述为:
我们只需要计算 F 中参数的词嵌入的差异和相似度。 此外,它们的关系是对称的。 (又名关系(a,b)=关系(b,a))。 为了加强这种对称性,我们可以有
直观地说,我们保持所有这些嵌入向量之间的线性关系。 为了满足这个关系,F(x) 将是一个指数函数,即 F(x) = exp(x)。 结合最后两个方程,我们得到
由于 F(x) = exp(x),
我们可以把 log(Xᵢ) 作为常数偏差项,因为它是 k 不变的。 但是为了保持 i 和 k 之间的对称要求,我们将其拆分为上面的两个偏置项。 这 w 和 b 形成嵌入矩阵。 因此,两个嵌入矩阵的点积可以预测对数共现计数。 直觉 让我们通过推荐系统中的矩阵分解来理解这个概念。 下面的纵轴代表不同的用户,横轴代表不同的电影。 每个条目显示用户给出的电影评级。
这可以作为矩阵分解问题来解决。 我们想为用户和电影发现隐藏的因素。 这个因素描述了用户喜欢什么或电影的隐藏特征(如类型)。 如果他们的因素匹配,电影评分会很高。 例如,如果用户喜欢浪漫和老电影,他们会很好地匹配电影《当哈利遇到莎莉》(80 年代的浪漫电影)。 用户和电影的向量表示应该为他们的点积产生高价值。
因此,包含所有用户和电影的评分矩阵可以近似为用户隐藏特征和电影隐藏特征的乘积(矩阵 Z 保存所有用户的隐藏因子,w 保存所有电影的隐藏因子)。 在 GloVe 中,我们测量单词之间隐藏因素的相似性以预测它们的共现计数。 从这个角度来看,我们不仅仅预测共现词。 我们希望创建可以预测它们在语料库中的共现计数的向量表示。
cost函数 接下来,我们将定义成本函数。 我们将使用均方误差来计算基本事实中的误差和预测的共现计数。 但是由于词对在语料库中的出现频率不同,我们需要一个权重来重新调整每个词对的成本。 这是下面的函数 f。 当共现计数高于或等于阈值时,例如 100,权重将为 1。否则,权重将更小,取决于共现计数。 这是训练 GloVe 模型的目标函数。
现在,我们完成了词嵌入。 下一个 词嵌入对词进行编码。 但它没有考虑到它的词上下文。 接下来,我们将研究可用于许多 NLP 任务的句子的向量表示。 BERT 被 Google 用于搜索,适用于许多 NLP 任务。 如果你想为 NLP 学习深度学习,它是最重要的技术之一。 |