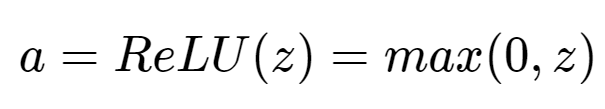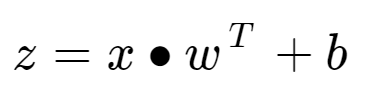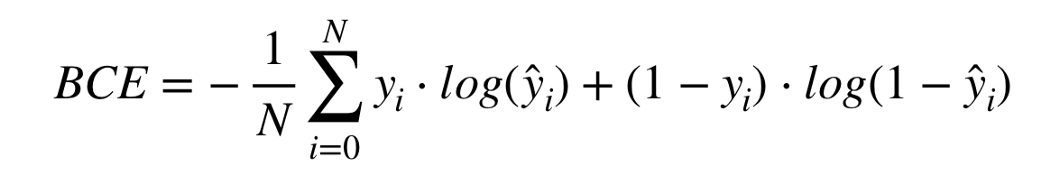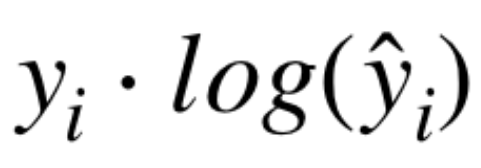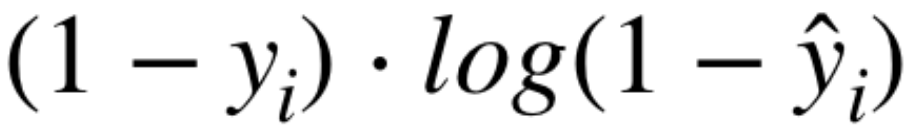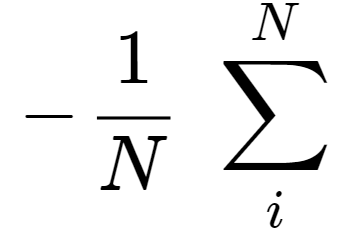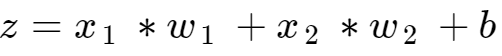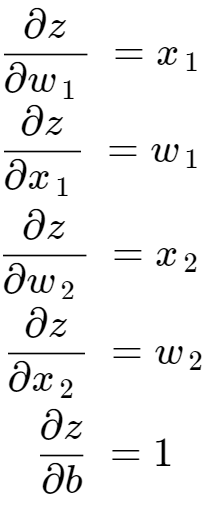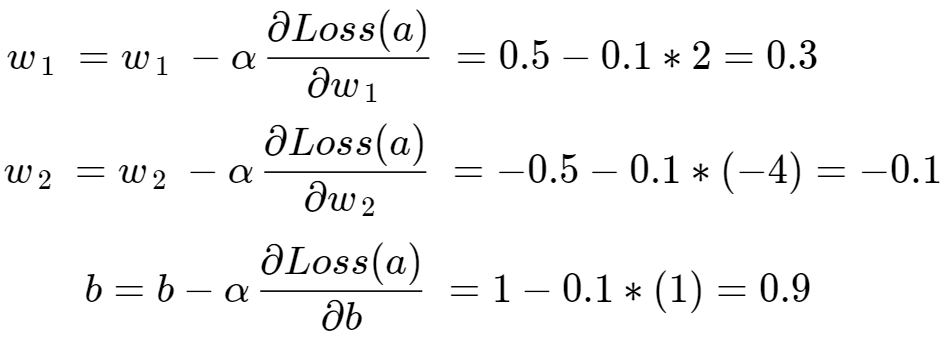|
随着神经网络改变世界,了解神经网络原理也是很重要的。 在本文中,将介绍如下内容:
要对神经网络背后的数学有一个基本的了解,可能需要了解一点线性代数的前馈方法和导数知识(我们将使用基本的偏导数)。 前馈 前馈方法建立在点积和非线性激活函数的基础上。 每个神经网络都有一个输入向量、一些隐藏层和一个输出层。 请注意,输入可能会被混淆为一层,但由于不涉及计算,因此它们仅被视为数据的向量或矩阵。
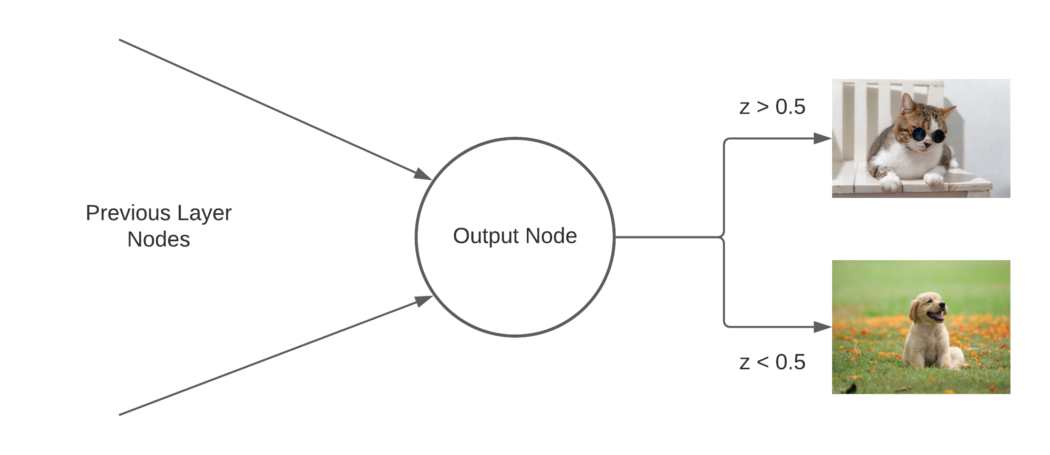
每层由许多节点组成。 注意,第一个隐藏层有 4 个节点,第二个隐藏层有 4 个节点,输出层有 1 个节点。 每层可以有任意数量的节点,但随着节点数量的增加,训练网络所需的计算能力也会增加。 另外,请注意每个节点有多条线将该节点连接到下一层中的所有节点以及前一层中的所有节点。 这些线称为权重,是我们希望在神经网络中调整的参数。 在进入神经网络前馈部分的公式之前,让我们回顾一下一些符号:
下面是一个节点表示的图片。 如果不了解,下面我们将逐步分解它。
上面的节点有 3 个输入(x 值),这意味着它也有 3 个权重。 你可以想象这个节点是某个隐藏层的一部分,前一个隐藏层包含 3 个节点。 请记住,一个节点连接到它之前的所有节点,这就是我们有 3 个输入的原因。 每个输入都有一个相应的权重,用于计算 z 值,这是节点中的第一个计算。 下面的公式可以用来计算上图节点的z值:
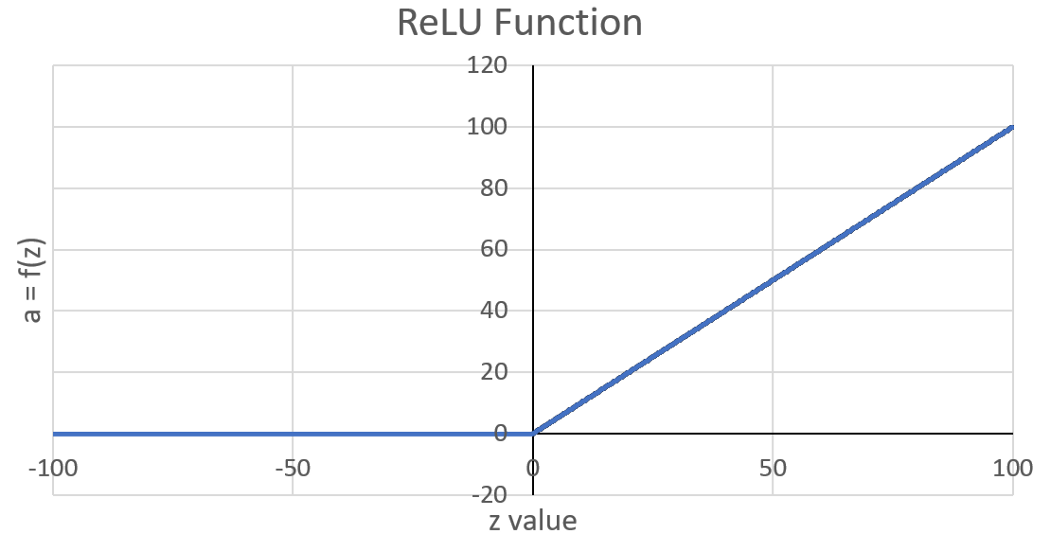
所以要计算 z 值,每个输入都要乘以它对应的权重。 将所有这些值相加,然后添加到偏差中。 在计算 z 值后,将激活函数应用于总数,为我们提供节点的最终输出。 隐藏层节点中常用的一些激活函数是 ReLU、Tanh 或 Sigmoid,而输出层中常用的一些激活函数是 Sigmoid 或 Softmax。 我将在本文中的示例中使用 ReLU,因为它很容易区分。 下面是绘制时 ReLU 函数的样子:
ReLU 函数取 0 和 z 值之间的最大值,如下所示:
在计算出 a 值之后,节点计算就完成了,这个值可以传递给后续层。 我们刚刚计算的 a 计算仅针对层中的一个节点。 层往往有多个节点,因此您可以想象对层中的每个节点进行多次计算。 这就是神经网络的前馈部分的全部内容。 网络只是由节点组成的层构成,每个节点都遵循上面指定的公式。 为了获得更好的计算速度,点积用于对整个层进行 z 计算,而不是根据以下公式对单个节点进行 z 计算:
因此,我们可以根据输入的点积和转置权重(T 上标表示转置值)加上每个节点的偏差来计算层的 z 值。 然后可以将 ReLU 函数应用于这些 z 值。 以下是使用 numpy 在 Python 中编写代码的示例:
这个损失函数有三个主要部分,我们将分解每个部分。 第一部分如下图所示:
该公式将真实标签乘以预测标签的对数。假设我们想预测一张图片是一只猫。那么 yᵢ 将是 1,因为我们 在上述示例中将猫表示为 1。因此,如果我们的网络以 100% 的确定性预测图像是一只猫,那么 ŷᵢ 也将 为 1。由于 1 的对数为 0,因此该项将变为 0。 如果我们的网络预测图像是一只猫,值为 0.75,那么 ŷᵢ 为 0.75。 0.75 的对数约为 -0.28,因此此项变为 -0.28。 如果我们的网络预测图像是输出为 0 的狗,则 ŷᵢ 为 0。0 的对数为负无穷大,因此该项变为负无穷大。 请注意,随着预测值 ŷᵢ 与真实标签 1 的进一步偏移,该项变得更加负数。因此,该项将损失减少了 预测与实际值相差多远的因子。 如果 yᵢ 为 0,这意味着我们希望网络预测图像是狗,那么该项始终为 0。 下一个公式如下:
这一项看起来与上一项非常相似,但 y 值是从 1 中减去的。在前面的示例中,yᵢ 为 1,因为我们 希望网络预测图像是一只猫。 对于此项,如果 yᵢ 为 1,则该项将始终为 0。 如果 yᵢ 为 0,则该公式将遵循前一个公式在 yᵢ 为 1 时的工作方式,但方向相反。 所以 如果 ŷᵢ 为 0,那么 log 值为 0,因为 1-0 的 log 为 0。 如果 ŷᵢ 为 0.75,则对数值为 log(0.25),约为 -1.38 如果 ŷᵢ 为 1,则日志值为 log(0),即负无穷大 如您所见,当真实标签 yᵢ 为 0 时,该公式随着预测值远离 0 而减小。
结合这两项,当真正的标签 (yᵢ) 为 1 时,第一项 (yᵢ ∙ log(ŷᵢ)) 是活动的。 在这种情况下, 随着 ŷᵢ 越来越接近 0(接近错误标签),两项之和越来越接近负无穷大。 当真实标签 (yᵢ) 为 0 时,第二项 ((1-yᵢ) ∙ log(1-ŷᵢ)) 处于活动状态。 在这种情况下,随着 ŷᵢ 越来越接 近 1(接近错误标签),两项之和也越来越接近负无穷大。 这些项可以给出的值范围是 [-∞, 0],其中 0 表示 ŷᵢ=yᵢ,-∞ 表示 ŷᵢ=(1-yᵢ)。 所以这些术语基本上是说随着预测值 ŷᵢ 离实际值 yᵢ 越来越远,损失越来越接近负无穷大。 最终公式如下:
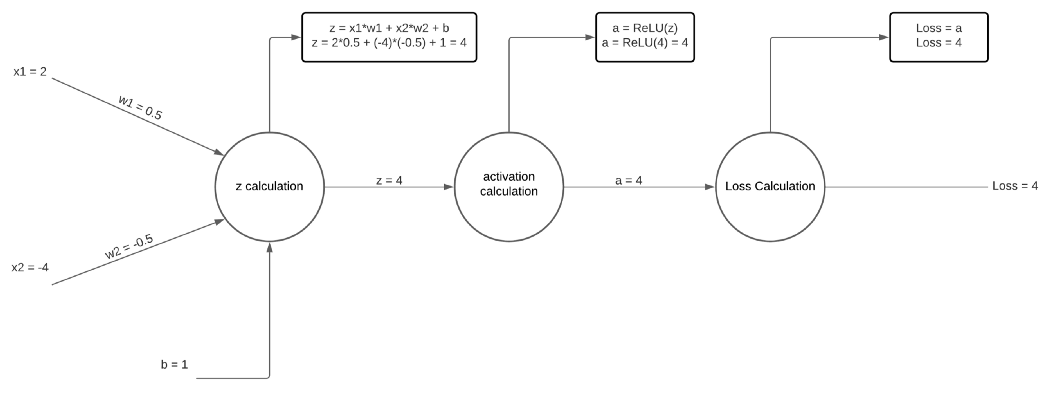
在训练神经网络时,你不想给网络一个例子,然后让它从那个例子中学习。您希望网络从 几个示例中学习。这就是为什么存在从 i 到 N 的总和,其中 i 从第 0 个示例开始,到 最后第 N 个示例结束。然后在将所有损失值相加之后,我们取平均值(这就是为什么存在 1/N 项)。 记住,此损失函数可以在 [-∞, 0] 的范围内,其中 -∞ 表示网络性能尽可能差,0 表示网络性 能尽可能好。问题是负无穷大是非常不直观的,因为更多的负值似乎表明网络表现良好,而实 际上,它的表现非常糟糕。请记住,0 是损失函数中的“低”值,而 -∞ 和 ∞ 是损失函数中 的“高”值。因此,负号将范围翻转到 [0, ∞] 使其更加直观。应用负号后,当损失为较大的 正值时网络表现更差,当损失接近 0 时表现非常好。负号对神经网络的训练没有任何重要作用 ,但它使损失函数更直观,更容易调试。 BCE 损失函数是众多损失函数之一。事实上,任何函数都可以是损失函数,但该函数可能不能代表 网络学习的内容。在下一节中,我们将简要介绍反向传播的工作原理。 反向传播 反向传播是稍微更新神经网络中的权重以帮助其更好地执行并希望学习所需任务的过程。 与 我们在前馈过程中所做的从左到右不同,这个过程是从右到左通过网络并在前馈方法完成之后进行的。 回到前面描述的损失函数,反向传播的目标是尽可能减少损失,并希望它会找到该函数的 全局最小值。 这个过程是通过使用带有偏导数的链式法则来完成的。 让我们从一个具有 2 个输入和 1 个输出的基本神经网络的可视化开始:
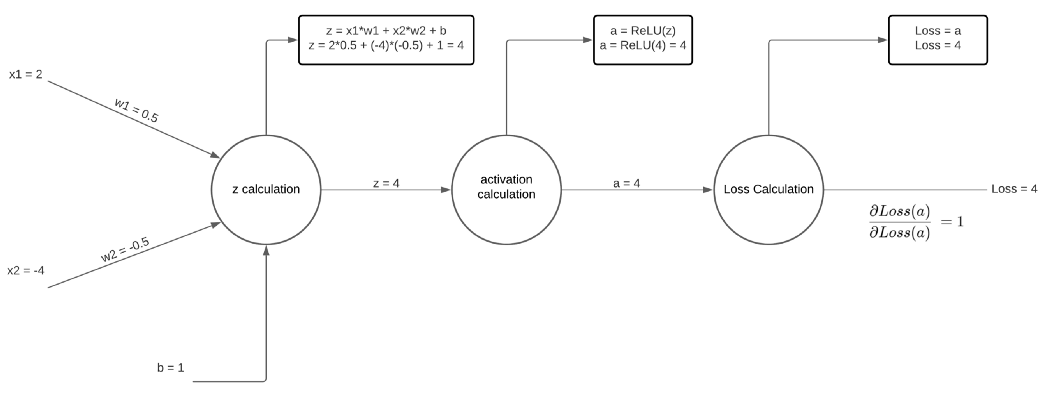
上图可能看起来有点奇怪,但那是因为 z 和 a 计算被分解为不同的节点。 为简单起见, 损失等于 z 值,但同样的数学适用。 已经计算了前向馈送,其中损失最终为 4。 反向传播的目标是根据损失值对权重和偏差进行偏导,然后使用它们的导数更新权重和偏差。 我们通过使用链式法则来做到这一点。 首先,让我们取损失对损失的偏导数:
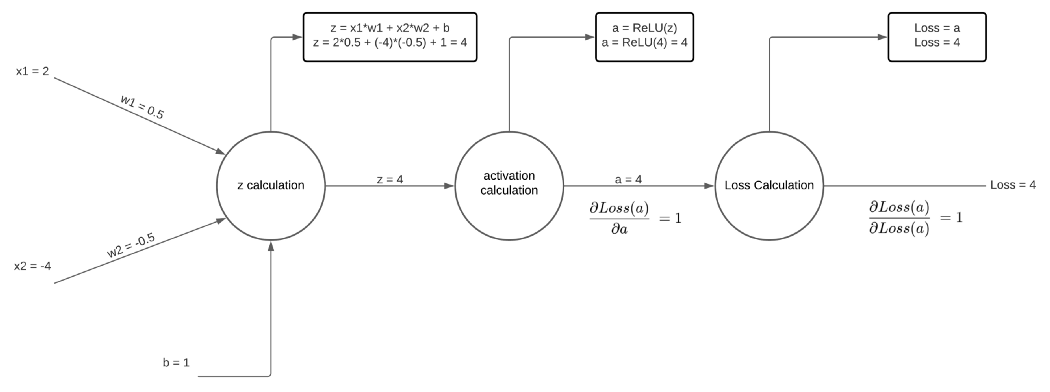
当然,这个值等于 1,而且由于 loss 对 loss 的导数总是 1,所以在推导其他变量时不会使用这个值。 继续向后,让我们计算 a 关于损失的偏导数。
再一次,这是 1。由于损失函数只是 a,因此损失函数关于 a 的偏导数只是 1。与损失的先前导数不同, 这个值很重要,即使它只是 1。想象一下 BCE 损失对 ŷᵢ 的导数。 该值不仅是 1,还会影响所有其他导数。 现在让我们计算激活函数 ReLU 的导数。 ReLU 的导数非常简单,z<0 时为 0,z>0 时为 1。 当 z 为 0 时, 导数是未定义的,所以一般来说,我们说该点的导数是 0。下面是更新后的图,其中包含 Loss 对 z 值的导数:
由于 z 的值为 4,大于 0,因此 z 值的导数为 1。但这只是 z 值在激活函数方面的导数。 我们想要的 是 z 值相对于损失函数的导数。 为此,我们使用链式法则。 对于链式法则,我们所要做的就是将先前 计算的导数乘以新的导数,以获得损失相对于 z 值的导数。 最终的值仍然是 1,但那是因为激活函数的导数是 1。 现在让我们计算权重和偏差的导数。 回想一下本例中z值的公式如下:
以下是此函数中所有值的导数:
x 的导数实际上是无用的。 没有理由更新 x 值,因为 x 值是网络的输入,每次迭代都会改变。 另一方面, 权重和偏差的导数是我们想要用来更新网络的。 使用链式法则,我们根据 x、w 和 b 值得到以下损失函数的导数:
让我们用这些新的数据更新图表:
现在我们有了权重和偏差的导数,我们可以更新权重和偏差。 由于我们想最小化损失, 我们通过它们的导数减去权重和偏差的值。 在实践中,权重和偏差的导数乘以一个名为 α (alpha) 的常数,用于进行更稳定的更新。 α 通常介于大于 0 到 1 的某个值之间。 这样,我们减少了权重和偏差的更新量。 在这种情况下,让我们使用 α = 0.1。 以下 是用于更新每个参数的公式:
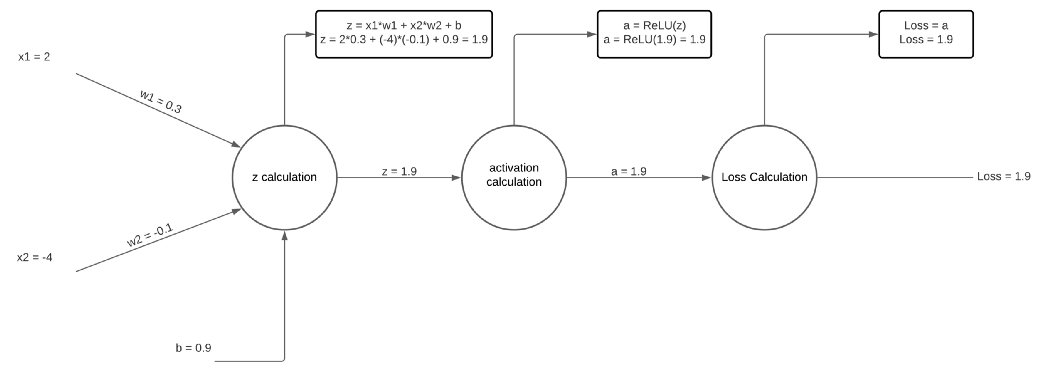
所以让我们用新的权重和偏差更新图表:
你可能想知道为什么我们做了所有这些工作来更新权重和偏差。 此更新可能看起来很小,但请 记住我们希望将损失降到最低。 让我们看看现在的损失是多少:
更新前损失为4,更新后损失为1.9。 如果我们使用新的损失值进行另一次更新,我们会发现损失再次减少, 并且在每次连续更新后都会继续这样做。 这就是反向传播如此有用的原因,也是它如此擅长优化损失函数的原因。 我们刚刚所做的计算是针对层中的单个节点的,但是相同的数学运算适用于所有其他层中的所有其他节点。 下面是一些更新网络 100 次的 Python 代码。 请注意损失如何减少并接近 0,这是该损失值可以达到的最低值。
|