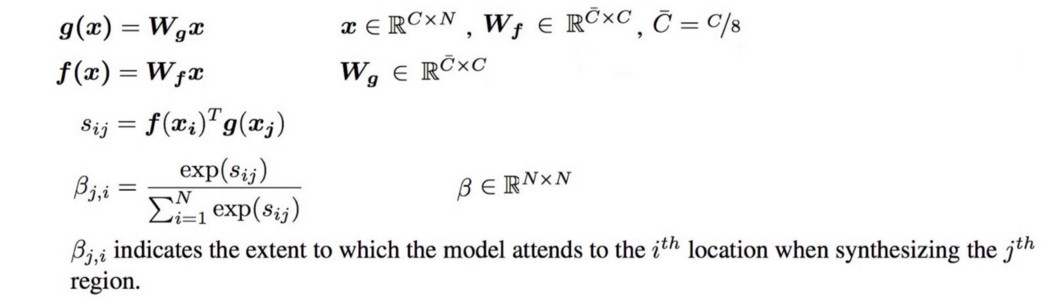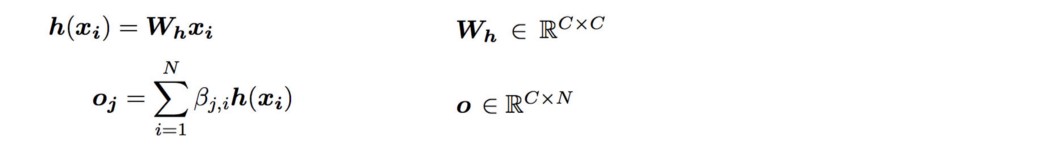|
GAN 如何使用注意力来提高图像质量,例如注意力如何提高语言翻译和图像字幕的准确性? 例如,图像字幕深度网络专注于图像的不同区域以在字幕中生成单词。
下面突出显示的区域是网络在生成特定单词时重点关注的区域。
动机 对于使用 ImageNet 训练的 GAN 模型,它们擅长具有大量纹理(风景、天空)的类,但在结构方面表现更差。 例如,GAN 可以很好地渲染狗的皮毛,但对于狗的腿却很失败。 虽然卷积滤波器擅长探索空间位置信息,但感受野可能不足以覆盖更大的结构。 我们可以增加滤波器大小或深度网络的深度,但这会使 GAN 更难训练。 或者,我们可以应用注意力概念。 例如,为了细化眼睛区域(左图的红点)的图像质量,SAGAN 只使用了中图高亮区域的特征图区域。 如下图所示,这个区域的感受野更大,上下文更集中,更相关。 右图显示了嘴部区域(绿点)的另一个示例。
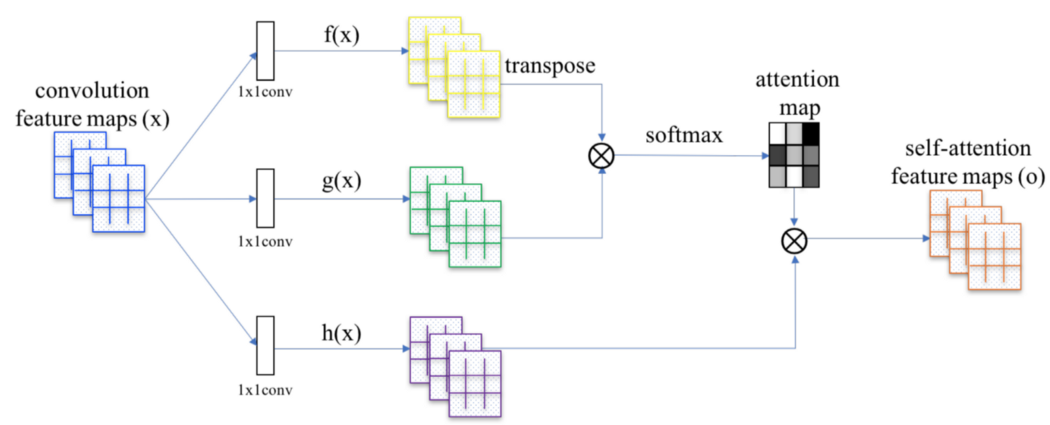
设计 对于每个卷积层,
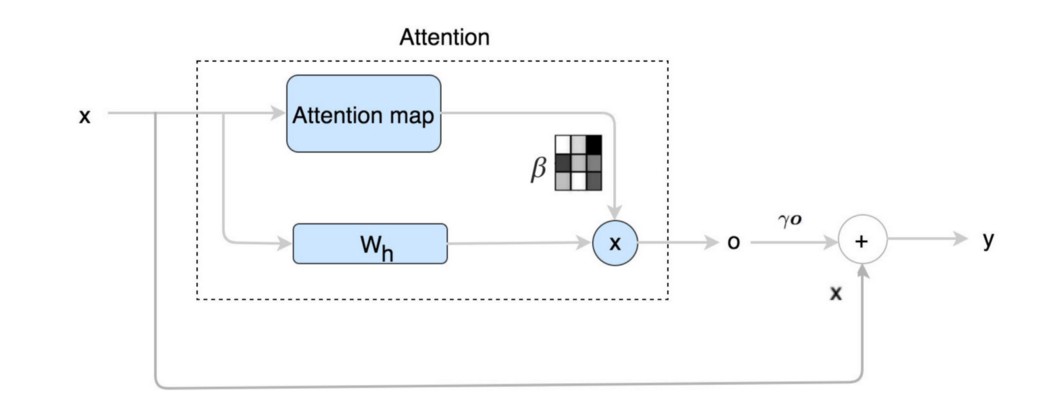
我们使用由自注意力机制计算的额外项 o 来优化每个空间位置输出。
其中 x 是原始层输出,y 是新输出。
(注意,我们将自注意力机制应用于每个卷积层。) 自注意力包括
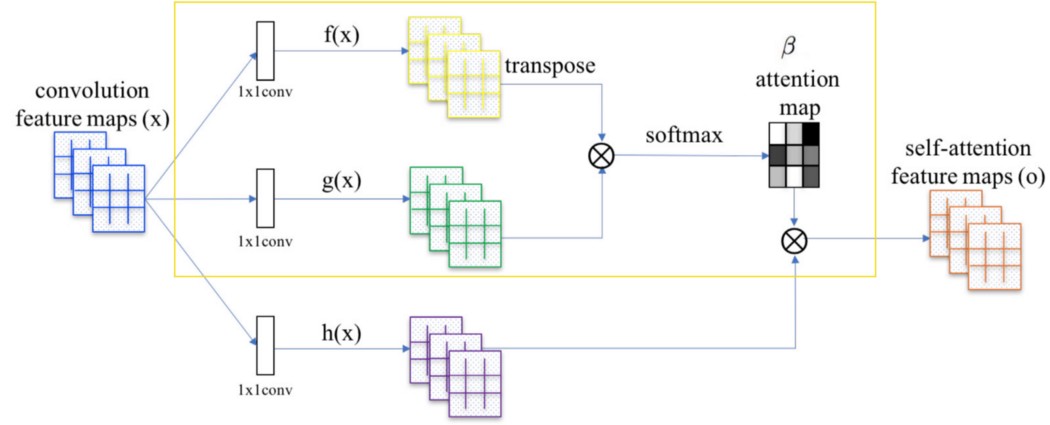
注意力图
我们将 x 与 Wf 和 Wg(这些是要训练的模型参数)相乘,并使用它们通过以下公式计算注意力图 β:
对于每个空间位置,都会创建一个充当掩码的注意力图。 βij 被解释为在渲染位置 j 时位置 i 的影响。
注意力输出 接下来,我们将 x 与 Wh(模型参数也将被训练)相乘,并将其与注意力图 β 合并以生成自注意力特征图输出 o。
这个卷积层的最终输出是:
其中 γ 初始化为 0,因此模型将首先探索局部空间信息,然后再通过 self-attention 对其进行细化。 损失函数 SAGAN 使用铰链损失来训练网络:
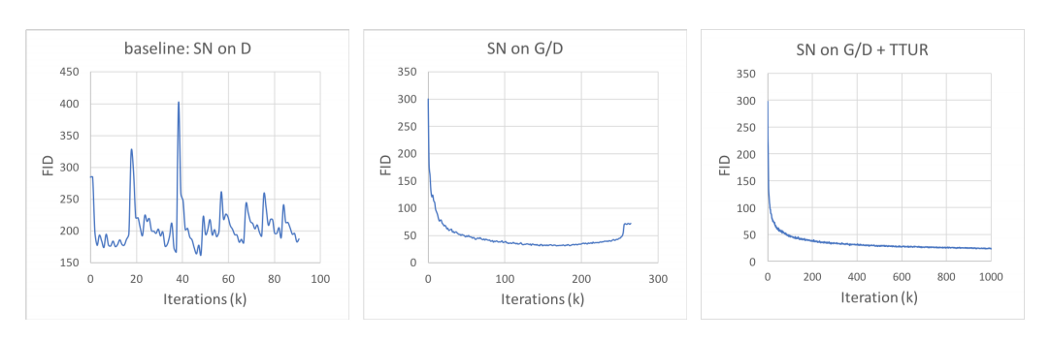
Implementation 自注意力不仅仅适用于生成器。 生成器和判别器都使用自注意力机制。 为了改进训练,判别器和生成器使用不同的学习率(在论文中称为 TTUR)。 此外,spectral normalization(SN)用于稳定 GAN 训练。 这是 FID 中的性能度量(越低越好)。
|