|
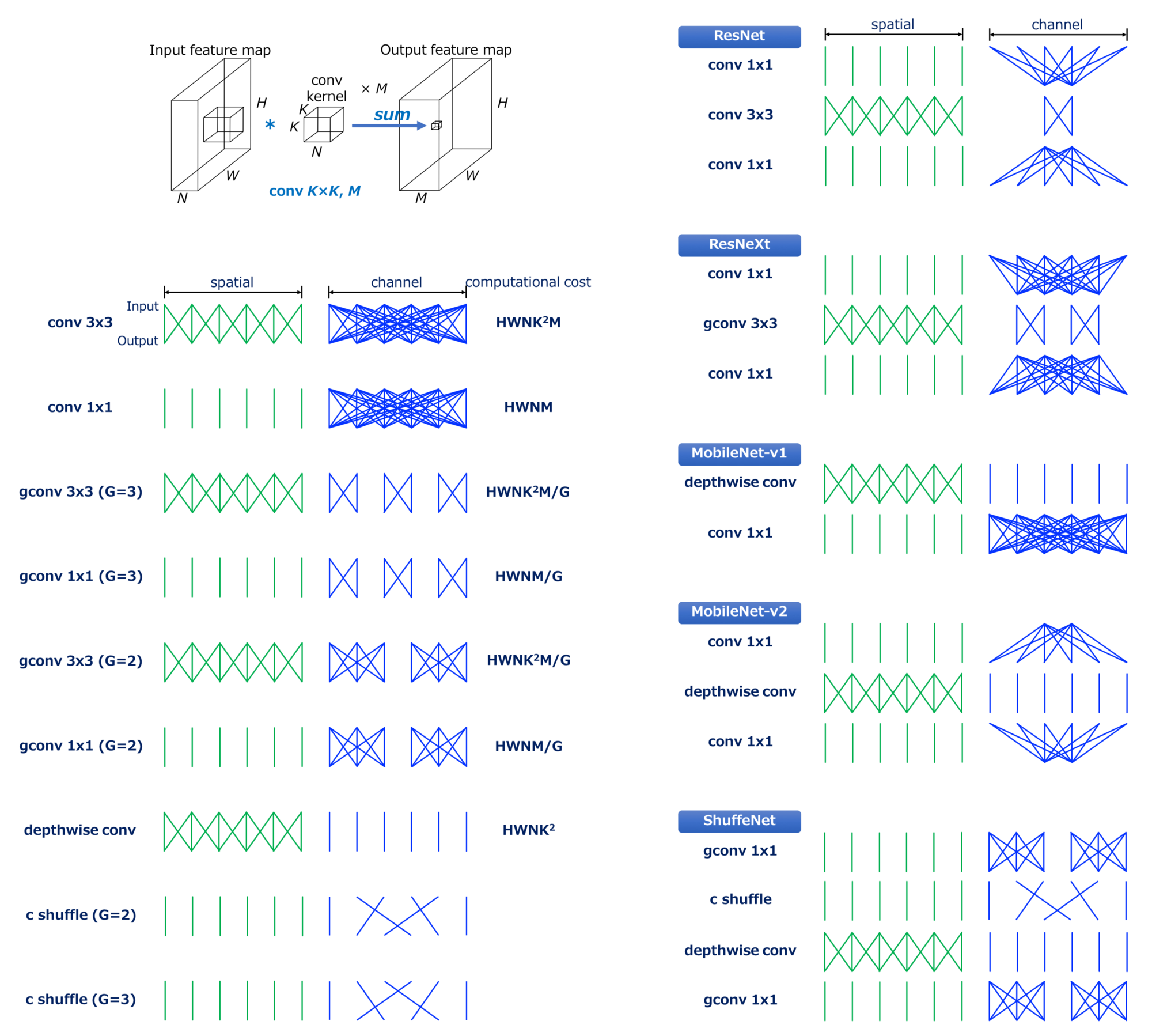
介绍 在本文中,概述了 MobileNet 等高效 CNN 模型及其变体中使用的构建块,并解释了它们为什么高效。 特别是,提供了有关为什么在空间域和通道域中完成卷积的直观说明。 高效模型中使用的构建块 在解释具体的高效 CNN 模型之前,检查一下高效 CNN 模型中使用的构建块的计算成本,看看卷积是如何在空间域和通道域中执行的。
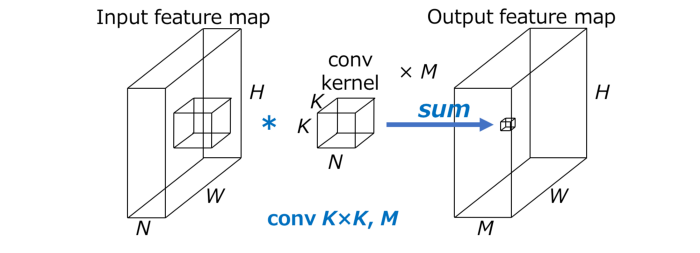
设HxW表示输出特征图的空间大小,N表示输入通道数,KxK表示卷积核大小,M表示输出通道数,标准卷积的计算成本变为HWNK²M。 这里重要的一点是标准卷积的计算成本与(1)输出特征图 HxW 的空间大小,(2)卷积核 K² 的大小,(3)输入和输出通道数 NxM 成正比 . 当在空间域和通道域上都执行卷积时,需要上述计算成本。 CNN 可以通过分解这个卷积来加速,如下所示。 Convolution 首先,下面是一个关于标准卷积如何在空间和通道域中进行卷积的直观说明,其计算成本为 HWNK²M。 我们在输入和输出之间连线以可视化输入和输出之间的依赖关系。 行数分别粗略表示空间域和通道域卷积的计算成本。
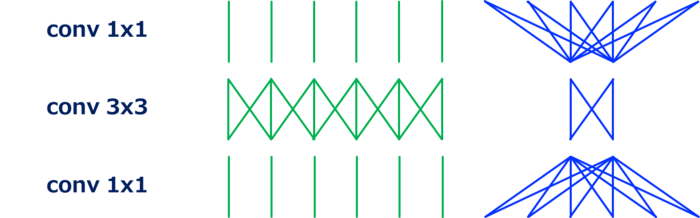
例如,最常用的卷积 conv3x3 可以如上图所示进行可视化。 我们可以看到,输入和输出在空间域中是局部连接的,而在通道域中,它们是全连接的。
接下来,conv1x1 [1],或逐点卷积,用于改变通道的大小,如上图所示。 这个卷积的计算成本是HWNM,因为kernel 的大小是1x1,与conv3x3相比,计算成本降低了1/9。 这种卷积用于在通道之间“混合”信息。 Grouped Convolution 分组卷积是卷积的一种变体,其中输入特征图的通道被分组,每个分组通道独立执行卷积。 用G表示组数,分组卷积的计算成本为HWNK²M/G,与标准卷积相比,计算成本降低了1/G。
G=2 的分组 conv3x3 的情况。 我们可以看到通道域中的连接数变得比标准卷积小,这表明计算成本更小。
G=3 的分组 conv3x3 的情况。 连接变得更加稀疏。
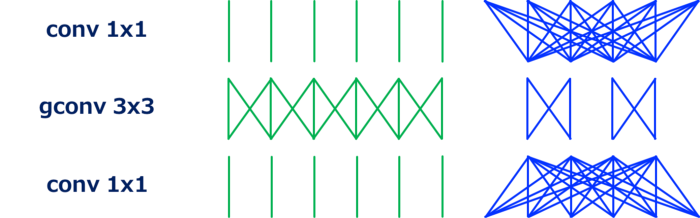
G=2 的分组 conv 1x1 的情况。 这个,conv 1x1 也可以分组。 ShuffleNet 中使用了这种类型的卷积。
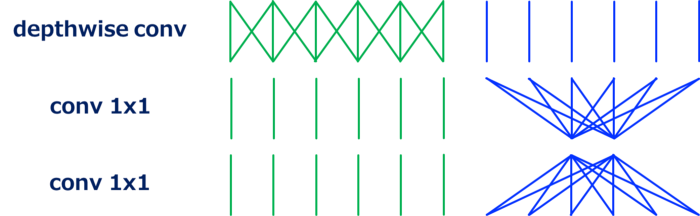
G=3 的分组 conv1x1 的情况。 Depthwise Convolution 在Depthwise卷积 [2,3,4] 中,每个输入通道独立执行卷积。 它也可以定义为分组卷积的一种特殊情况,其中输入和输出通道的数量相同并且 G 等于通道的数量。
如上所示,depthwise 卷积通过省略通道域中的卷积显着降低了计算成本。 Channel Shuffle Channel shuffle 是一个操作(层),它改变了 ShuffleNet [5] 中使用的通道的顺序。 这个操作是通过张量reshape和转置来实现的。 更准确的说,让GN'(=N)表示输入通道数,输入通道维度先reshape为(G,N'),再将(G,N')转置为(N',G),最后 展平成与输入相同的形状。 这里,G 表示分组卷积的组数,在 ShuffleNet 中与通道 shuffle 层一起使用。 虽然无法根据乘加运算 (MAC) 的数量来定义通道 shuffle 的计算成本,但应该有一些开销。
G=2 的 channel shuffle 的情况。 不执行卷积,只是改变了通道的顺序。
G=3 的 channel shuffle 的情况。 Efficient Models 在下文中,对于高效的 CNN 模型,这里提供了有关它们如何高效以及如何在空间和通道域中进行卷积的直观说明。 ResNet (Bottleneck Version) ResNet [6] 中使用的具有bottleneck架构的残差单元是与其他模型进一步比较的好基点。
如上所示,具有bottleneck架构的残差单元由 conv1x1、conv3x3 和 conv1x1 组成。 第一个conv1x1降低了输入通道的维度,降低了后续相对复杂的conv3x3的计算成本。 最后的 conv1x1 恢复输出通道的维度。 ResNeXt ResNeXt [7] 是一个高效的 CNN 模型,可以看作是 ResNet 的一个特例,其 conv3x3 被分组的 conv3x3 替换。 通过使用高效的分组 conv,与 ResNet 相比,conv1x1 中的通道减少率变得适中,从而在相同的计算成本下获得更好的准确性。
MobileNet (Separable Conv) MobileNet [8] 是由depthwise conv 和conv1x1(pointwise conv)组成的可分离卷积模块的堆栈。
separable conv 在空间域和通道域中独立执行卷积。 这种卷积分解显着降低了从 HWNK²M 到 HWNK²(深度方向)+ HWNM(conv1x1),HWN(K² + M)的计算成本。 一般来说,M>>K²(例如K=3且M≥32),减少率大约为1/8-1/9。 这里重要的一点是,计算成本的bottleneck现在是 conv1x1! ShuffleNet ShuffleNet 的动机是 conv1x1 是上面提到的可分离 conv 的bottleneck。 虽然 conv1x1 已经很有效,而且似乎没有改进的余地,但是分组 conv1x1 可以用于此目的!
上图说明了 ShuffleNet 的模块。 这里的重要构建块是通道shuffle层,它在分组卷积中“shuffle”组间通道的顺序。 如果没有通道 shuffle,分组卷积的输出永远不会在组之间被使用,从而导致精度下降。 MobileNet-v2 MobileNet-v2 [9] 采用了类似于 ResNet 的具有bottleneck架构的残差单元的模块架构; 残差单元的修改版本,其中 conv3x3 被深度卷积替换。
从上面可以看出,与标准的bottleneck架构相反,第一个conv1x1增加了通道维度,然后进行了depthwise conv,最后最后一个conv1x1减少了通道维度。
通过对上述构建块进行重新排序并将其与 MobileNet-v1(separable conv)进行比较,我们可以看到该架构是如何工作的(这种重新排序不会改变整体模型架构,因为 MobileNet-v2 是该模块的堆栈)。 也就是说,上面的模块可以看作是 separable conv 的修改版本,其中 separable conv 中的单个 conv1x1 被分解为两个 conv1x1。 用T表示通道维度的扩展因子,两个conv1x1的计算成本是2HWN²/T,而可分离conv中的conv1x1的计算成本是HWN²。 在 [5] 中,使用 T = 6,将 conv1x1 的计算成本降低了 3 倍(通常为 T/2)。 FD-MobileNet 最后,介绍了 Fast-Downsampling MobileNet (FD-MobileNet)[10]。 在此模型中,与 MobileNet 相比,在较早的层中执行下采样。 这个简单的技巧可以降低总计算成本。 原因在于传统的下采样策略和separable conv的计算成本。 从 VGGNet 开始,很多模型都采用相同的下采样策略:先进行下采样,然后将后续层的通道数加倍。 对于标准卷积,下采样后计算成本不会改变,因为它是由 HWNK²M 定义的。 但是,对于separable conv,下采样后它的计算成本变小了; 它从 HWN(K² + M) 减少到 H/2 W/2 2N(K² + 2M) = HWN(K²/2 + M)。 当 M 不是很大时(即较早的层),这相对占优势。 我用以下图结束了这篇文章
References[1] M. Lin, Q. Chen, and S. Yan, “Network in Network,” in Proc. of ICLR, 2014. [2] L. Sifre, “Rigid-motion Scattering for Image Classification, Ph.D. thesis, 2014. [3] L. Sifre and S. Mallat, “Rotation, Scaling and Deformation Invariant Scattering for Texture Discrimination,” in Proc. of CVPR, 2013. [4] F. Chollet, “Xception: Deep Learning with Depthwise Separable Convolutions,” in Proc. of CVPR, 2017. [5] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,” in arXiv:1707.01083, 2017. [6] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in Proc. of CVPR, 2016. [7] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated Residual Transformations for Deep Neural Networks,” in Proc. of CVPR, 2017. [8] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications,” in arXiv:1704.04861, 2017. [9] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L. Chen, “MobileNetV2: Inverted Residuals and Linear Bottlenecks,” in arXiv:1801.04381v3, 2018. [10] Z. Qin, Z. Zhang, X. Chen, and Y. Peng, “FD-MobileNet: Improved MobileNet with a Fast Downsampling Strategy,” in arXiv:1802.03750, 2018. |