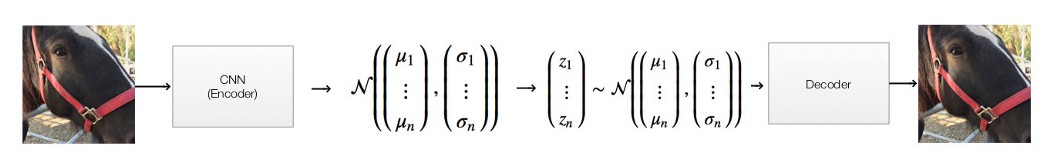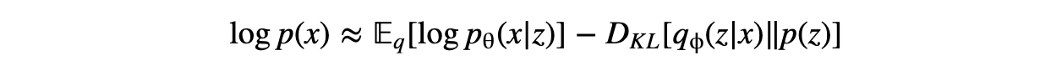|
在本文中,我们将讨论建模、构建和训练模型中的API。 它为我们提供了很大的灵活性,就像前文中的GAN网络那样。 我们还将讨论执行迁移学习的示例。 使用 GradientTape 进行模型训练 Keras 提供了简单的训练和评估方法,fit() 和evaluate()。 通过声明要使用的优化器和损失函数,梯度下降将自动执行。 然而,对于高级优化算法,我们需要访问计算梯度和执行梯度下降的内部机制。 在 TensorFlow (TF) 中,这可以使用 tf.GradientTape 来完成。 本节中的示例使用较低级别的 API 来构建和训练回归模型 (y = wx + b)。 首先,GradientTape 记录(tapes)前向传递。 稍后,为了执行反向传播,我们使用记录的tape t 来计算损失梯度 w.r.t。 w 和 b。 最后,使用梯度下降更新模型参数。 通过详细说明这些额外的步骤,我们可以注入可以为自定义优化算法显式操作和应用梯度的代码。 我们先来看一个自定义模型的代码,一个dense模型。
在 MyModel 的 __init__ 中,我们创建了可训练的参数 w 和 b。 可调用的 __call__ 是一种简单的 Python 机制,用于在调用 model(input) 时生成模型输出。 接下来,我们使用 GradientTape t 记录前向传递操作。 然后,在反向传播中,t.gradient 分别计算损失梯度 w.r.t w 和 b。 (如果需要有关 AutoDiff 的更多信息,请参阅本文。)接下来,我们使用assign_sub 使用梯度下降更新 w 和 b。 代码的最后一部分执行模型训练。
训练完成后,我们将数据和回归模型可视化。
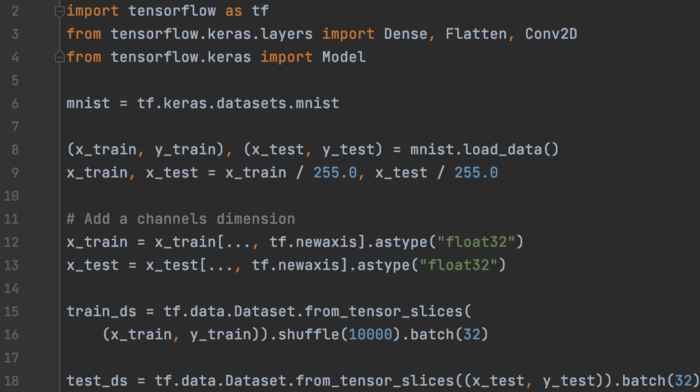
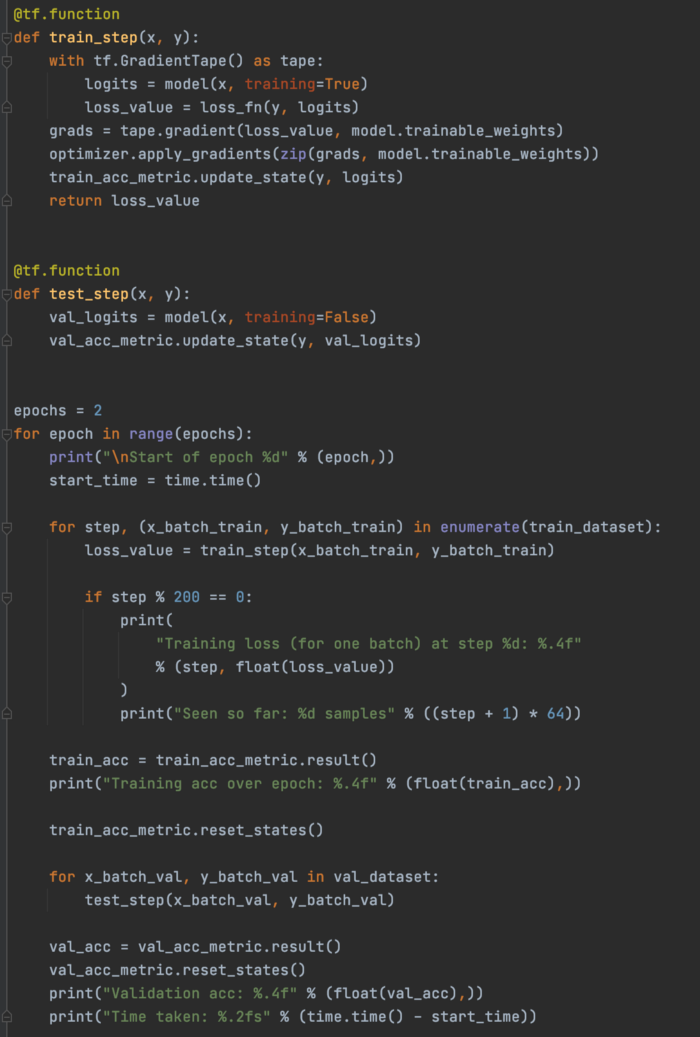
带有 GradientTape 的 MNIST 这是训练神经网络 (NN) 模型的另一个示例,即 MNIST 分类器。 代码的第一部分准备数据集。 它使用 NumPy ndarray x_train 和 y_train 以创建 32 个样本的小批量数据集。
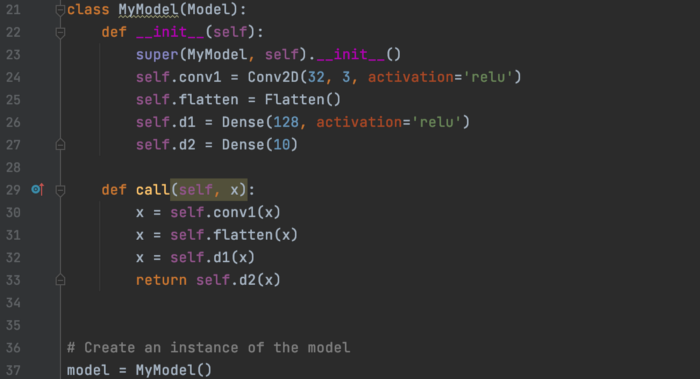
然后,我们创建一个模型。
接下来,我们将定义优化器、损失函数和要使用的指标。
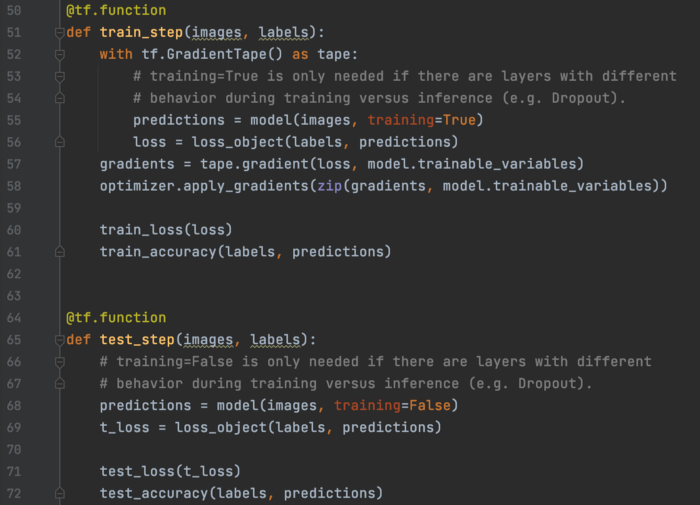
这是训练和测试步骤。 在训练中,我们进行预测并根据定义的损失函数计算损失。 接下来,它计算损失梯度 w.r.t. 所有可训练的weights。 model.trainable_variables 保存了一个可训练参数的列表,所以我们不需要自己做。 然后,我们应用我们选择的优化器来使用计算的梯度执行梯度下降。 最后,我们记录两个选定的指标(损失和准确性)。 在没有梯度下降优化的情况下,测试具有类似的步骤。
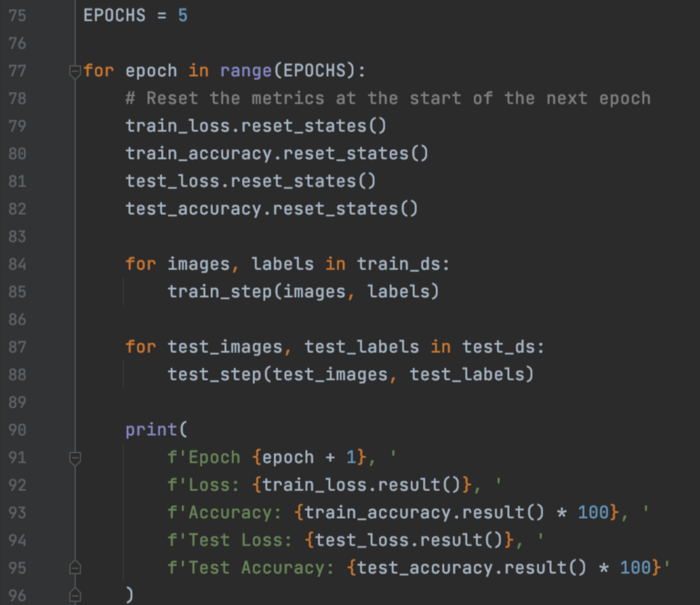
最后,我们运行训练,并在每个 epoch 开始时重置指标。
这是另一个版本。 它使用函数式 API 直接构建模型。 但它只使用dense层。 该代码还将部分训练数据集拆分为验证数据集。
训练迭代类似。 但我们改用 SGD 优化器。 此外,训练还包括一个额外的验证检查步骤。
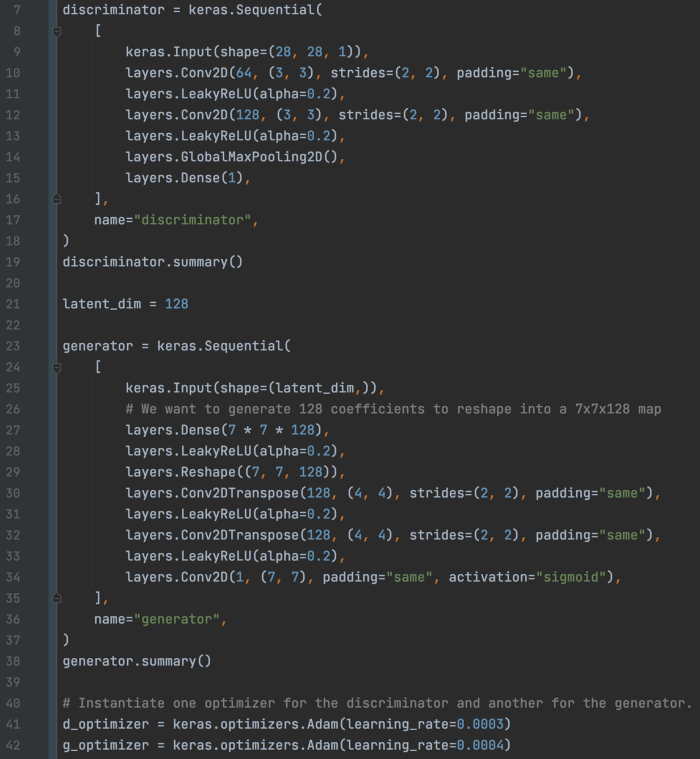
带有 GradientTape 的 GAN GAN 中经常使用自定义梯度下降。 下面的代码为 GAN 创建了一个鉴别器和一个生成器,其中生成器基于转置卷积(第 30 行)。
这是鉴别器和生成器的模型摘要。 如图所示, global_max_pooling2d 在其空间维度中找到最大值。
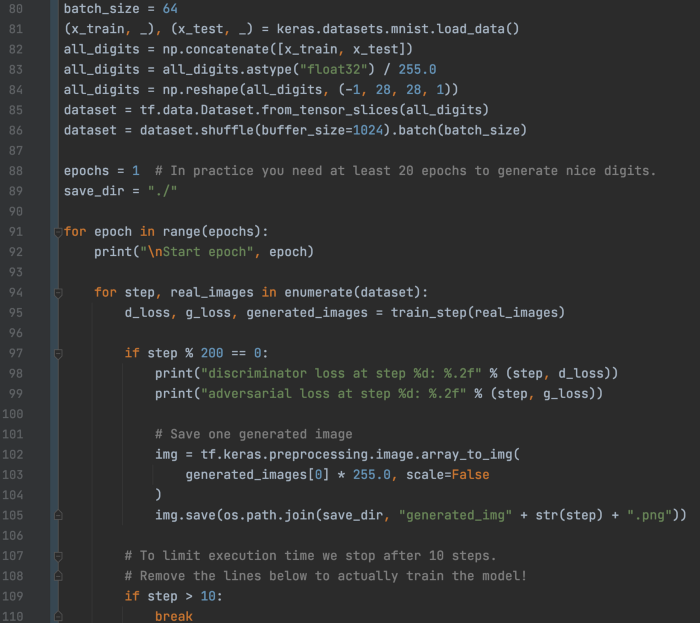
然后,我们从正态分布中采样潜在向量并从生成器生成图像(第 51 行)。 我们将生成图像和真实图像连接起来形成一个大的张量。 为了创建相应的标签,我们将生成图像的全 1 张量和真实图像的全零张量连接在一起(第 54 行)。 然后,我们计算判别器的交叉熵损失——我们期望判别器将真实图像分类为真实 (0),将生成的图像分类为假 (1)。
在第 66 行,我们再次生成潜在因子并将它们标记为 0。我们将这些因子通过生成器和第 72 行的判别器。再次,我们计算交叉熵,并期望判别器将这些图像误认为是真实的(标签 0 )。 判别和生成器的损失梯度将分别用于更新它们自己的参数(第 64 行和第 75 行)。 最后,下面的代码准备数据集和训练。
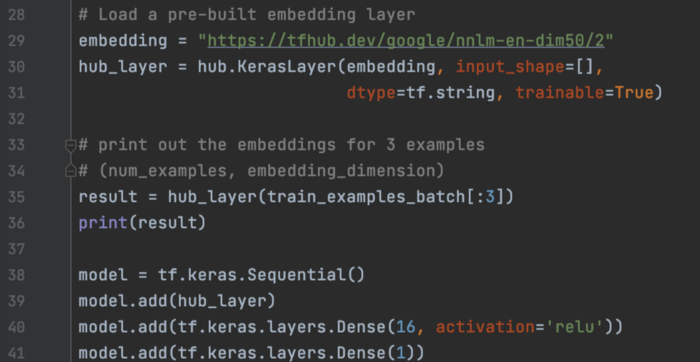
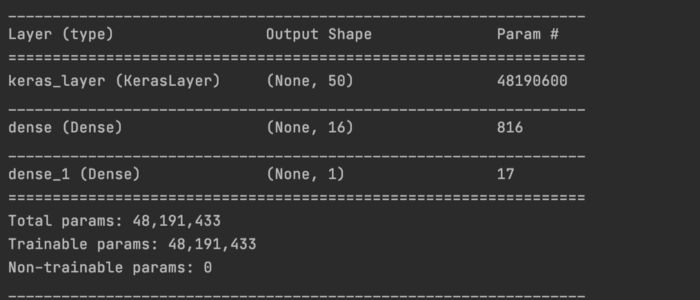
TensorFlow Hub TF Hub 提供预训练的模型和层。 例如,我们可以下载一个预先构建的嵌入层,将电影文本评论编码为 50 维向量。
这是构建的模型的summary。 我们将来自预训练嵌入层的 50 维向量输入 2 个dense层,以预测它是否是一个好的review。
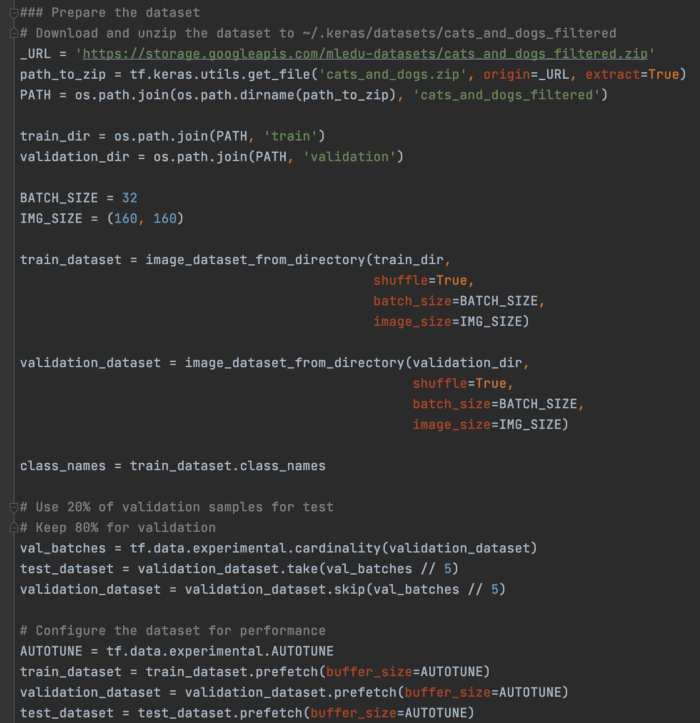
迁移学习 DL 模型很难训练。 因此,许多项目从带有迁移学习的预训练模型开始。 为了完整起见,这里是为包含狗或猫的图像准备数据集的代码。
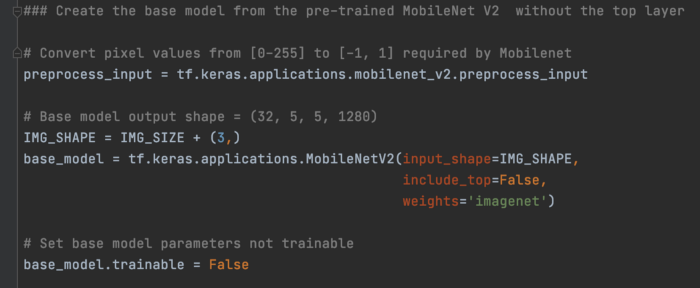
然后我们创建一个预训练的 Mobilenet V2 模型,并确定所有权重都不可训练。
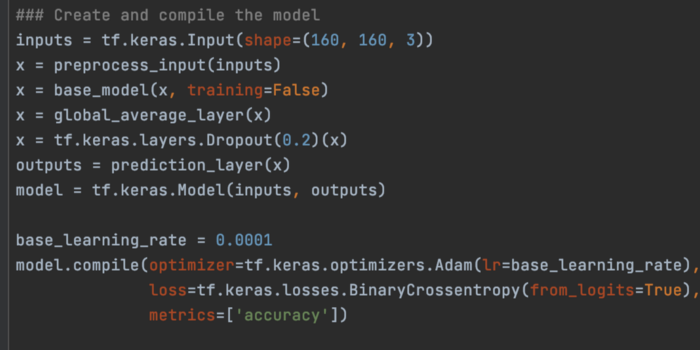
接下来,我们添加自己的分类头来预测图像是猫还是狗。
我们使用 base_model 和新头构建一个新模型。 它还包含一个 preprocess_input 层,用于将输入缩放到 [-1, 1] 的范围内。
接下来,我们训练模型。 因为我们之前设置了base_model.trainable = False,所以只会训练添加的分类头。
完成 10 个 epoch 后,我们要对模型进行微调,包括 base_model 中的一些层。 首先,我们设置 base_model.trainable = True,然后将前 100 层设置为不再可训练。 每当更改训练配置或模型本身时,模型必须再次编译 (model.compile) 以使更改生效。 最后,我们再次拟合模型。 在model.fit中,我们将initial_epoch设置为11(history.epoch[-1])来重新开始训练。 这允许优化器以正确的学习率恢复训练。
接下来,我们评估新模型,做出一些预测,并将它们绘制出来。
前面有一行重要的代码可以使微调工作。
基本上,它指示模型即使在训练期间也使用推理模式。 在某些层中,推理模式下的执行与训练模式不同。 例如,当模型处于推理模式时,model.fit 将忽略 dropout 层。 它被跳过。 此设置与设置 layer.trainable 不同,后者仅指示是否应在反向传播中更新层的参数。 让我们在微调期间用批量归一化 (BN) 来演示它。 在 BN 中,training=False 指示层不要使用当前批次的均值和方差。 相反,它使用先前训练的均值和方差。 我们希望使用更大的数据集在从先前训练中收集的统计数据下对模型进行微调。 自定义层 Kersa 带有许多预定义的 NN 层。 但是我们也可以通过扩展layers.Layer来自己创建自定义层。 下面的代码实现了一个dense层。
作为参考,这里是自定义层的代码.
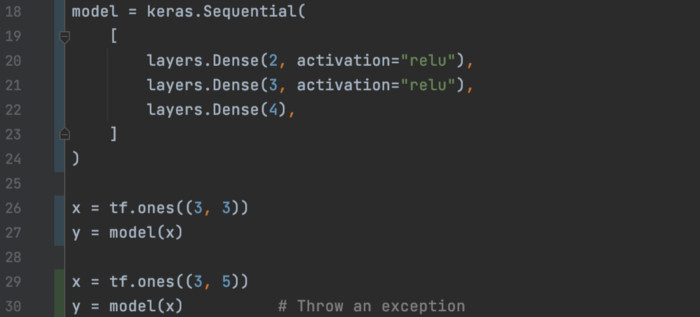
Build 在 TF 中,当层或模型被实例化时,不需要知道 input_shape(第 18 行)。
在 TF 中,当层或模型被实例化时,不需要知道 input_shape(第 18 行)。 但是没有这些信息,一个层就不能创建它的层权重。 TF 还没有知道权重shape的信息。 权重的shape可以是 (5, 2)、(50, 2) 或第一个dense层中的其他shape。 但是当模型第一次用第 27 行的输入调用时,TF 将调用“model.build”来实例化具有输入shape的模型参数(在我们的示例中为 (3, 3))。 但是如果后面用不同输入shape的参数调用模型,就会抛出异常。 或者,我们也可以使用输入shape显式调用 build 来实例化权重,而不是调用模型。 在下面的第 14 行中,实例化了 BatchNormalization 层。 但是由于没有提供输入shape,所以没有创建变量。 但是当使用输入shape调用“build”时,会创建 2 个可训练参数和 2 个不可训练参数(均值和方差)。
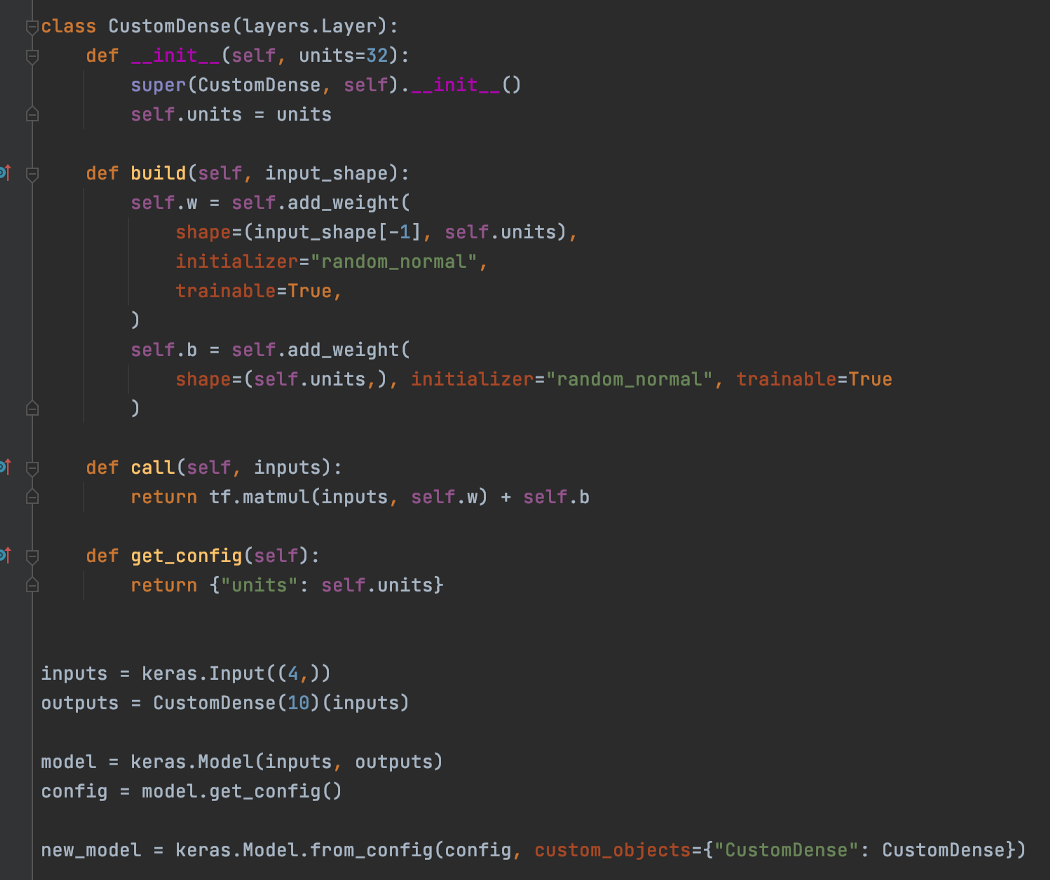
这是在“build”中初始化 FC 层参数的示例。 下面的代码还包含一个 get_config 方法,因此可以从另一个实例的模型配置中实例化模型。
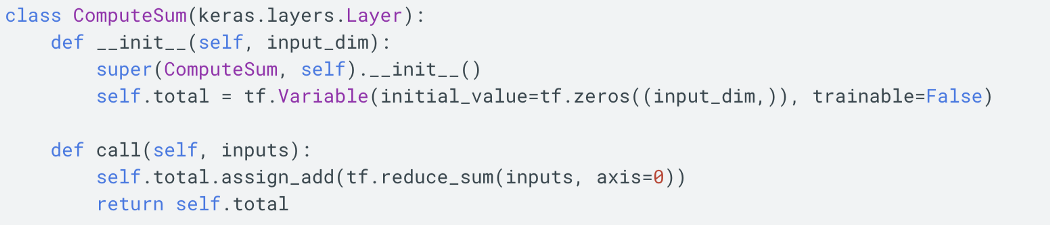
作为脚注,如果模型尚未构建,model.summary 将抛出异常。 以下示例展示了如何将不可训练的变量添加到summary输入的层。
sublayers 一个层可以由其他层组成。 最佳实践是在 __init__ 中实例化它们,以便在构建此层时构建它们。
add_loss(可选) 我们可以在 callable 中添加一个损失值。 要检索层及其子层的损失,调用 layer.losses。
我们还可以为模型添加损失。
这是向模型添加损失的另一个例子。
在下面的自定义优化代码中,我们检索所有损失以执行梯度下降。
如果使用model.fit来训练模型,所有增加的损失都会自动包含在梯度下降中。 不需要其他任何东西。 因此,我们可以简单地使用 model.fit 来训练模型。
add_metric(可选) 我们还可以在图层中添加一个metric。
自定义模型 本节介绍如何创建自定义模型。 模型和层的 API 是相似的。 事实上,keras.Model 继承自 keras.Layer。 但是对于模型来说,会有额外的 API,如fit, evaluate, save等……
Autoencoder 我们把它们放在一起来构建一个自动编码器。
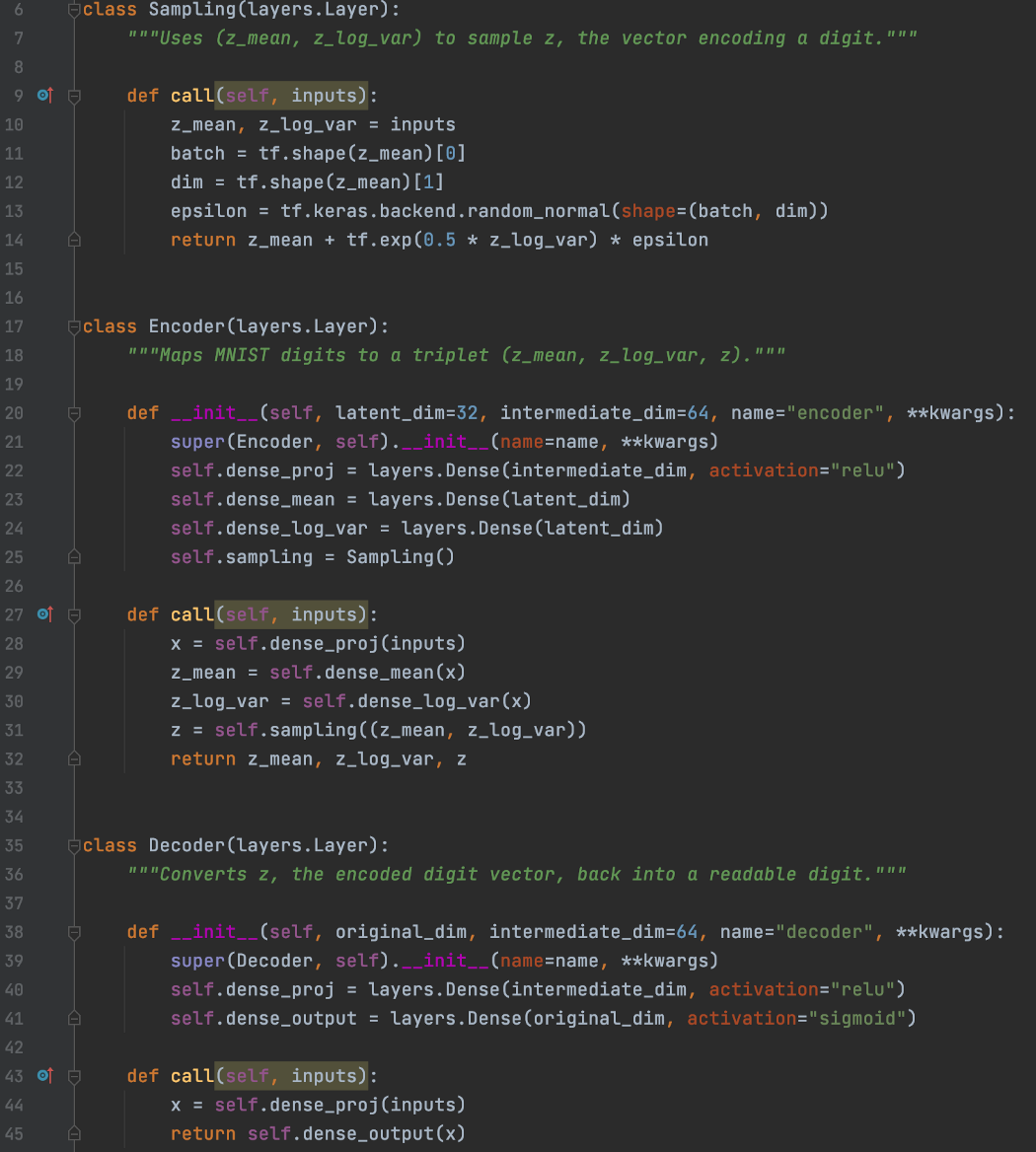
自编码器由 3 层类组成:编码器→采样(编码器的一部分)→解码器。
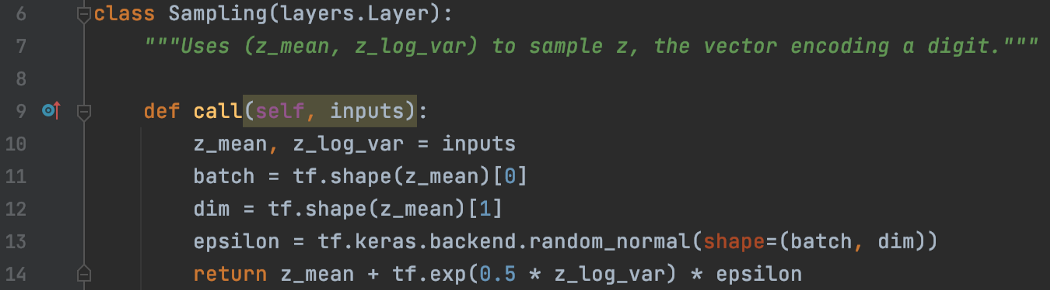
编码器的主要目标是创建一个由高斯分布的均值 (dense_mean) 和对数方差 (dense_log_var) 组成的 32 维潜在因子 z。
然后我们使用采样子层根据这个高斯分布对一个值进行采样。
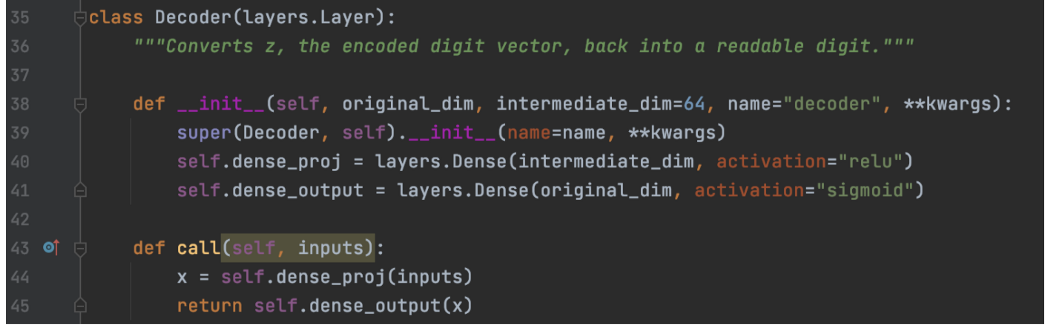
然后,我们使用解码器中的dense层使用此采样的潜在因子重新生成图像。
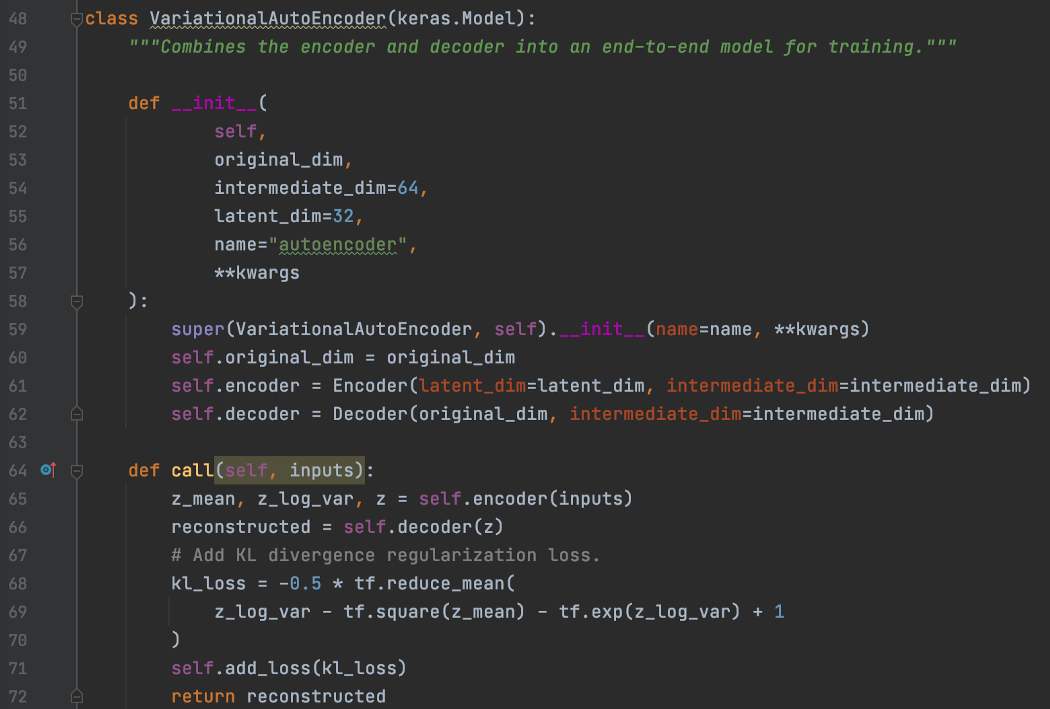
接下来,我们使用这些自定义层组成一个 VAE 模型。
这里没有证明,我们想最大化 log p(x)——图像的概率分布,公式如下。 (证明非常枯燥乏味,所以我们现在就用这个词。)它包括一个可以解释为分布 z 不会偏离用 KL 散度测量的标准正态分布的术语。
所以在 VariationalAutoEncoder.call 中,它增加了一个 KL 散度损失。
最后,这里是准备数据集和训练步骤的代码。
在第 100 行,我们为重建图像添加了 MSE 重建损失。 然后,我们将其与模型损失(KL 散度)相加。 实际上,我们没有对训练迭代做任何特殊的定制。 因此,我们可以简单地使用 model.compile 和 model.fit 来训练模型,并定义一个附加的 MSE 损失函数。
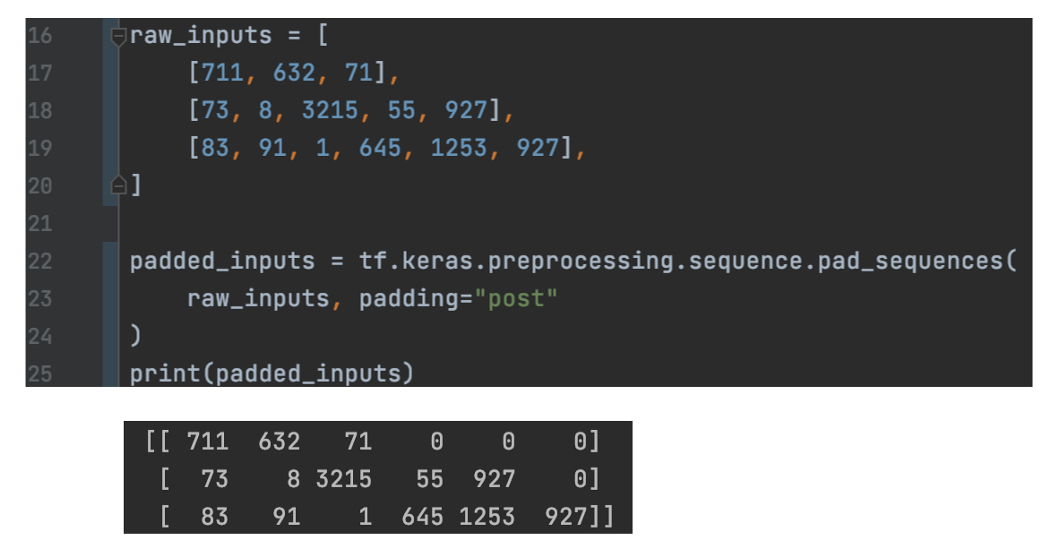
Mask 在训练期间,我们可以将可变长度的样本填充为固定长度,这样我们就可以将样本作为张量传递。 这在序列模型中是经常使用的。
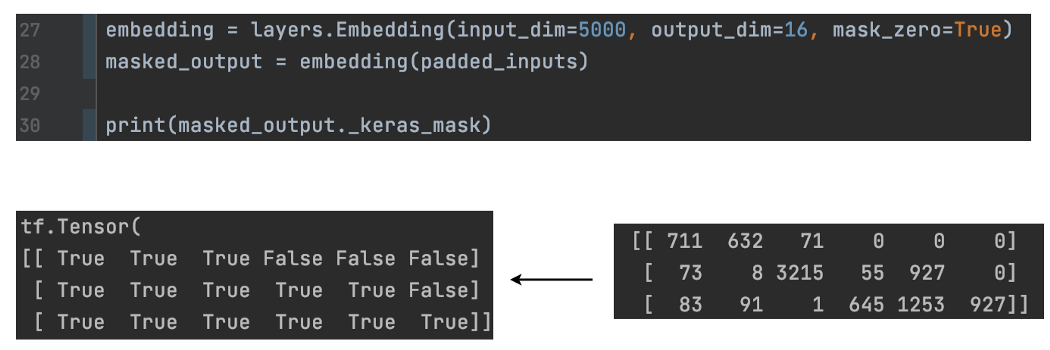
mask生成层 在像 Embedding 这样的掩码生成层中,当 mask_zero 设置为 True 时,层输出还将包括一个called _keras_mask 的属性。 它是一个掩码,可以传播到后续层以指示可以忽略其输入的哪一部分。
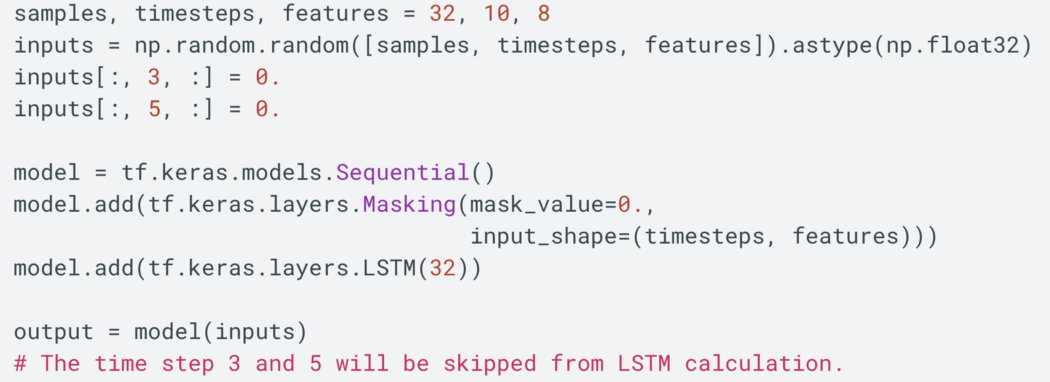
或者我们可以添加一个 keras.layers.Masking 层,这样后面的层,比如 LSTM 层,可以忽略某些时间步长。 考虑一个shape(batch_size、timesteps、features)的 NumPy ndarray。 我们将时间步长 3 和 5 设置为零以指示这些值缺失。 当 mask_value = 0 时,它将为后面的 LSTM 层创建一个掩码,这样它就可以跳过这些时间步长
隐式传递mask 当使用 Sequential 模型或函数式 API 时,mask将自动传播到能够使用它们的后续层。
mask生成自定义层 如果自定义层可以生成mask(如嵌入层),则它实现了 compute_mask 方法。
这是另一种可能的实现方式。
选择传递mask 默认情况下,自定义图层将破坏当前mask。 但是,要允许mask向前传播,请将 self.supports_masking 设置为 True。 任何后面的层也不会收到mask。
处理mask 如果层的输出依赖于mask,则可以在方法调用中添加mask参数。 在下面的示例中,在计算 softmax 值时将忽略来自skipped的所有分值。
|