|
让我们假设我们只有一个特征图检测右眼的脸。我们能用它来定位脸部吗?应该能。因为右眼应该在面部图片的左上角,所以我们可以很容易地用它来定位脸部。
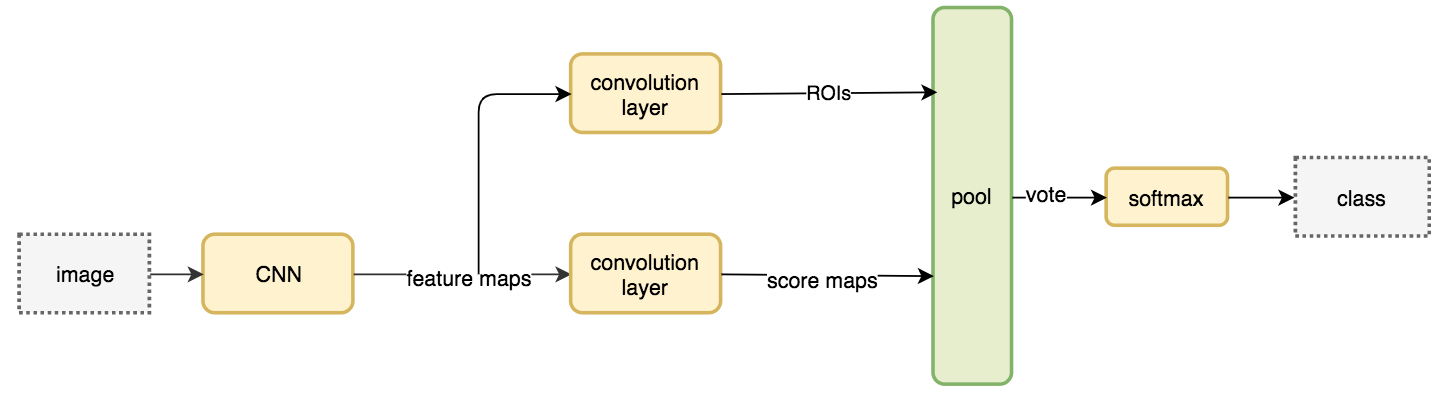
然而,特征图很少给出如此精确的答案。但是,如果我们有专门用于检测左眼、鼻子或嘴巴的其他特征图,我们就可以将信息组合在一起,从而使人脸检测更加容易和准确。为了推广这一解决方案,我们创建了9个基于区域的特征映射,每个映射分别检测左上角、中中、右上、左中、…。或者物体的右下角区域。通过对这些特征映射的投票进行组合,我们确定了物体的类别和位置。 Motivations 基于R-CNN的检测器,如fast R-CNN或faster R-CNN,分两个阶段进行目标检测.
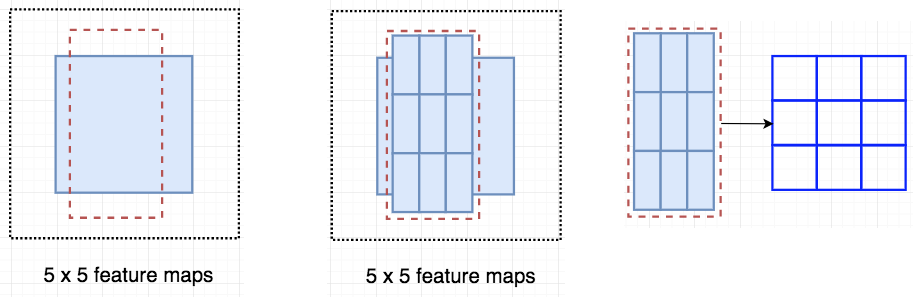
Fast R-CNN和Faster R-CNN流程概括如下: R-FCN 关于细节部分,假设一个5×5的特征映射M,里面有一个正方形的对象。我们将正方形物体等分为3×3区域。现在,我们从M创建一个新的特征映射,仅检测正方形的左上角(TL)。新的特征图看起来像下面右边的那张。只有黄色网格单元[2,2]被激活。
因为我们把正方形划分为9个部分(左上角tr,上中tm,右上tr,中左cf,…)。(右下角BR),我们创建了9个特征映射,每个特征映射检测对象的相应区域。这些特征映射被称为 position-sensitive score maps,因为每个map 检测对象的一个子区域(scores)。
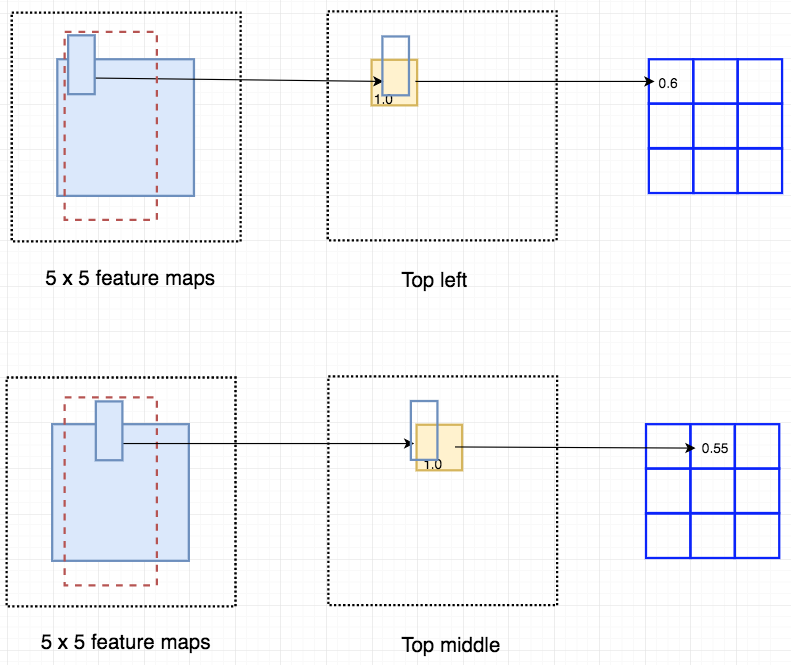
假设下面的红色矩形是ROI选出。我们将其划分为3×3区域,并询问每个区域包含对象的对应部分的可能性。例如,左上角ROI区域包含左眼的可能性有多大.我们将结果存储到右图中的3×3投票数组中。
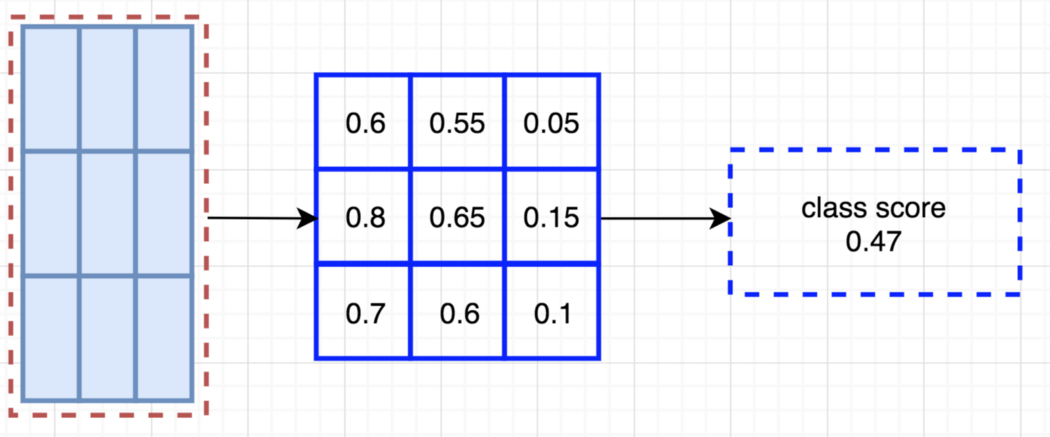
这种将分数映射和ROIS映射到投票数组的过程称为position-sensitive ROI-pool,这与Fast R-CNN中的ROI pool 非常相似。 下表如下: 我们取左上角ROI区域, 将其映射到左上角 score map上(上中图)。 我们计算由左上角ROI(蓝色矩形)为界的左上角得分图的平均分数。蓝色矩形内约40%有0激活,60%有100%激活,即平均0.6。所以我们检测到左上角物体的可能性是0.6。 我们将结果(0.6)存储到array[0][0]中。 我们用中上的ROI来重做,但是现在用中高分图。 计算结果为0.55,并存储在array[0][1]中。此值表示我们检测到顶部-中间对象的可能性。
让我们看看一个真实的例子。下面,我们有9个分数图来检测婴儿的左上角到右下角区域。在最上面的图表中,ROI与地面真相很好地一致。中间列中的黄色矩形表示对应于特定分数图的ROI子区域。在每一张地图的黄色实心框内,激活度都很高。因此,投票数组中的分数很高,并且检测到了一个婴儿。在第二个图表中,ROI不对齐。得分地图是相同的,但相应的位置的ROI子区域(实心黄色)被移动。整体激活是低的,我们不会分类这个ROI包含一个婴儿。
边界框回归 利用卷积建立k×k×(C+1)score图进行分类。要执行边界框回归,其机制几乎是相同的。我们使用另一个卷积从相同的特征映射创建一个4×k×k映射。我们应用基于位置的ROI pool来计算一个k×k数组,每个元素都包含一个边界框。最后的预测是这些元素的平均值。 结果 Faster R-CNN++和R-FCN都使用ResNet-101进行特征提取.(R-FCN采用多尺度训练。) R-FCN比Faster R-CNN快20倍
|