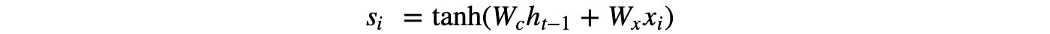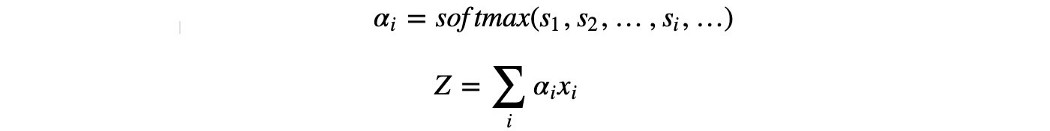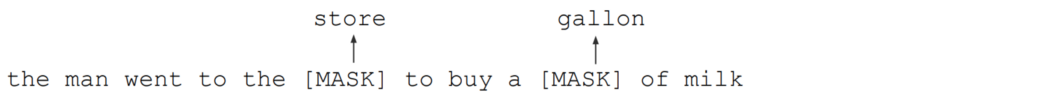|
谷歌发表了一篇文章“Understanding searches better than ever before”,将 BERT 定位为近年来搜索算法最重要的更新之一。 谷歌表示,15% 的谷歌查询以前从未见过。 但真正的问题不在于人们问什么。 这是一个问题可以被问多少种方式。 以前,谷歌搜索是基于关键字的。 但这远非理解或澄清人类语言中的歧义。 这就是谷歌在其搜索引擎中使用 BERT 的原因。 在下面的演示中,BERT 比基于关键字的搜索更好地响应了“你能为某人药店买药吗”这个查询。
在上一篇文章中,我们介绍了表示单词时的单词嵌入。 让我们继续 BERT 来表示一个句子。 严格来说,BERT 是一种训练策略,而不是一种新的架构设计。 要了解 BERT,我们需要先研究 Google Brain 的另一个提议。 那就是Transformer。 这个概念很复杂,需要一些时间来解释。 BERT 只需要 Transformer 的编码器部分。 但为了完整起见,我们也会介绍解码器,但可以根据你的兴趣随意跳过它。 让我们看一下 Transformer 的一个应用。 OpenAI GPT-2 是一个基于Transformer的模型,具有 15 亿个参数。 当我键入下面的段落时,灰色部分是使用 GPT-2 模型自动生成的。
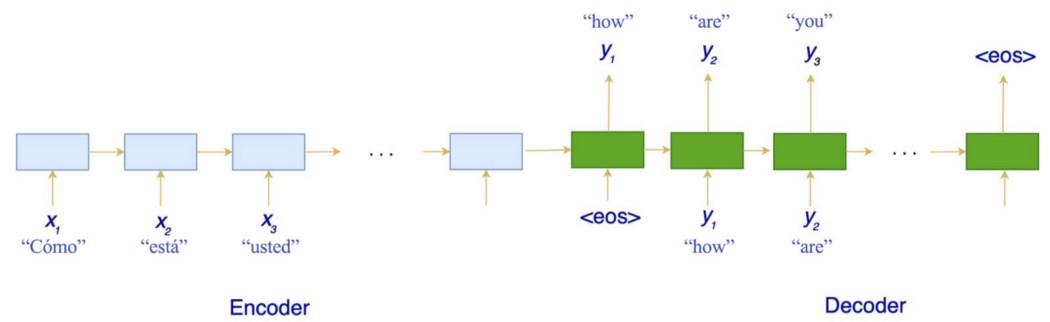
在 GPT-3 中,写作质量甚至可以达到作家的水平。 因此,OpenAI 不会发布模型参数,以免可能被滥用。 Encoder-Decoder & Sequence to Sequence 为了将输入序列映射到输出序列,我们经常使用编码器-解码器模型应用序列到序列的转换。 一个例子是使用 seq2seq 将句子从一种语言翻译成另一种语言。
我们假设你已经有这方面的基本背景。 所以我不会重复这些信息。 (如果你需要帮助,请稍后搜索“sequence to sequence”或“Seq2Seq”)。 多年来,seq2seq 模型使用 RNN、LSTM 或 GRU 来解析输入序列并生成输出序列。 但是这种方法遇到了一些挫折。 随着距离的增加,使用 RNN 学习远程上下文变得更加困难。
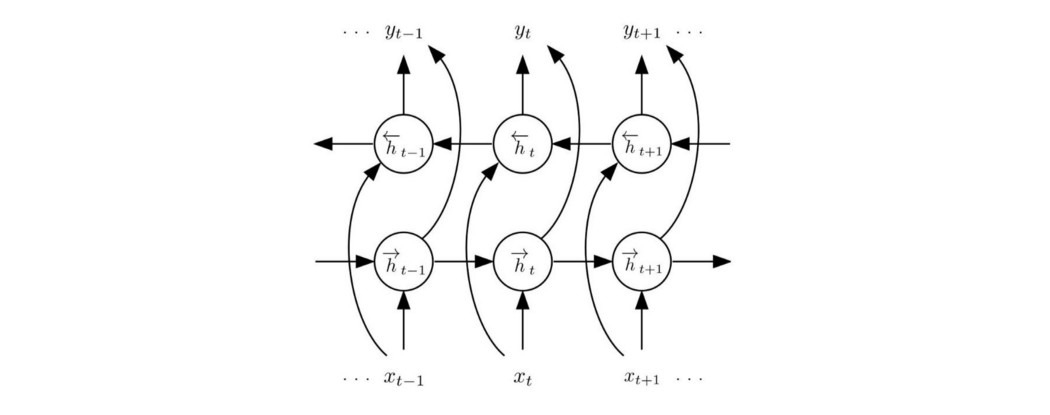
RNN 是定向的。 在下面的示例中,反向 RNN 可能有更好的机会正确猜测“赢”这个词。
为了避免做出错误的选择,
我们可以设计一个包含前向和后向 RNN 的模型(即双向 RNN),然后将两个结果相加。
我们还可以堆叠pyramidal双向 RNN 层以更好地探索上下文。
但是在某一时刻,我们可能会争辩说,为了理解下面“view”这个词的上下文,我们应该同时检查一段中的所有词。 即要知道下面的“view”可能指的是什么,我们应该将全连接(FC)层直接应用于段落中的所有单词。
然而,这个问题涉及到高维向量,就像大海捞针一样。 但是人类如何解决这个问题呢? 答案可能落在“attention”上。 attention 事件下图包含约100万像素,我们的大部分注意力可能会落在蓝裙女孩身上。
在为我们的查询创建上下文时,我们不应该对我们获得的所有信息给予同等重视。 我们需要集中注意力! 我们应该根据查询创建一个我们感兴趣的上下文。 但是这个查询会随着时间的推移而改变。 例如,如果我们正在搜索渡轮,我们的注意力可能会集中在售票亭上。 那么我们如何将其概念化为方程和深度网络呢? 在 RNN 中,我们根据输入 xt 和之前的隐藏状态 h(t-1) 进行预测。
但是在基于注意力的系统中,输入 x 将被注意力取代。
我们可以将注意力过程概念化为保留当前重要的信息。
例如,对于每个输入特征 xᵢ,我们可以训练一个 FC 层来评分特征 i(或像素)在先前隐藏状态 h 的上下文中的重要性。
之后,我们使用 softmax 函数对分数进行归一化以形成注意力权重 α。
最后,替换输入 x 时的注意力 Z 将是基于注意力的输入特征的加权输出。 在我们介绍方程之前,让我们进一步发展这个概念。 查询、键、值(Q、K、V) 首先,我们将用 query、key 和 value 形式化注意力的概念。 那么什么是查询、键和值呢? 查询是我们正在寻找的内容的上下文。 在之前的方程中,我们使用之前的隐藏状态作为查询上下文。 我们想知道基于我们已经知道的下一步是什么。 但在搜索中,它可以只是用户提供的一个词。 值是输入特征或原始像素。 键只是“值”的编码表示。 但在某些情况下,“值”本身可以用作“键”。
为了创建attention,我们确定查询和键之间的相关性。 然后我们屏蔽掉与查询无关的关联值。 比如查询“轮渡”,关注的重点应该是排队等候的队伍和票号。
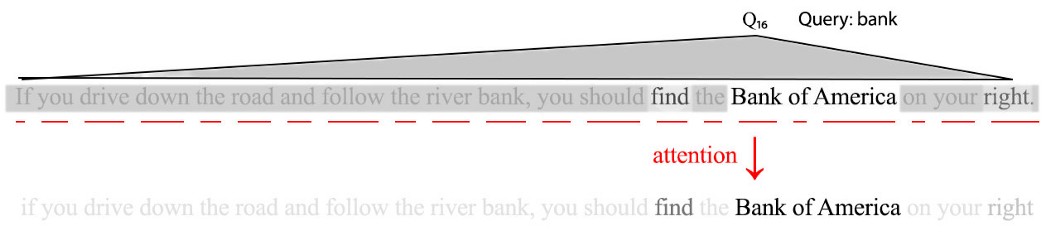
现在,让我们看看我们如何将注意力应用于 NLP 并开始我们的 Transformer 讨论。 但是Transformer相当复杂。 它是一种新颖的具有注意力的编码器-解码器模型。 Transformer 许多 DL 问题表示具有密集表示的输入。 这迫使模型提取有关输入的关键知识。 这些提取的特征通常称为潜在特征、隐藏变量或向量表示。 词嵌入创建了一个词的向量表示,我们可以使用线性代数对其进行操作。 但是,一个词在不同的上下文中可能有不同的含义。 在下面的示例中,词嵌入使用相同的向量来表示“bank”,即使它们在句子中具有不同的含义。
为了创建这个句子的密集表示,我们可以用 RNN 解析句子以形成嵌入向量。 在这个过程中,我们逐渐积累每个时间步的信息。 但有人可能会争辩说,当句子变长时,早期信息可能会被遗忘或覆盖。
也许,我们应该将句子转换为向量序列,即每个单词一个向量。 此外,在编码过程中还会考虑单词的上下文。 例如,下面的单词“bank”将根据上下文进行不同的处理和编码。
让我们使用查询、键和值将这个概念与注意力相结合。 我们将一个句子分解为单个单词。 每个单词既是一个值,又是它的键。
为了编码整个句子,我们对每个单词执行查询。 因此,一个 21 个单词的句子会产生 21 个查询和 21 个向量。 这个 21 向量序列将代表句子。 那么,我们如何对第 16 个单词“bank”进行编码呢? 我们使用单词本身(“银行”)作为查询。 我们计算这个查询与句子中每个键的相关性。 这个词的表示只是根据相关性的值的加权和——注意力输出。 从概念上讲,我们将不相关的值“变灰”以形成注意力。
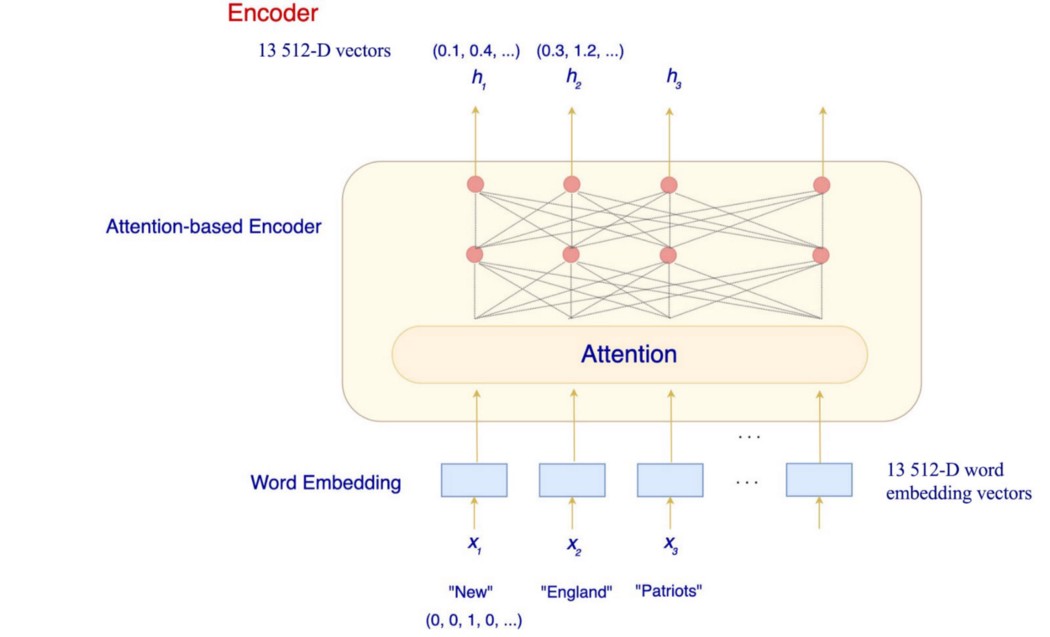
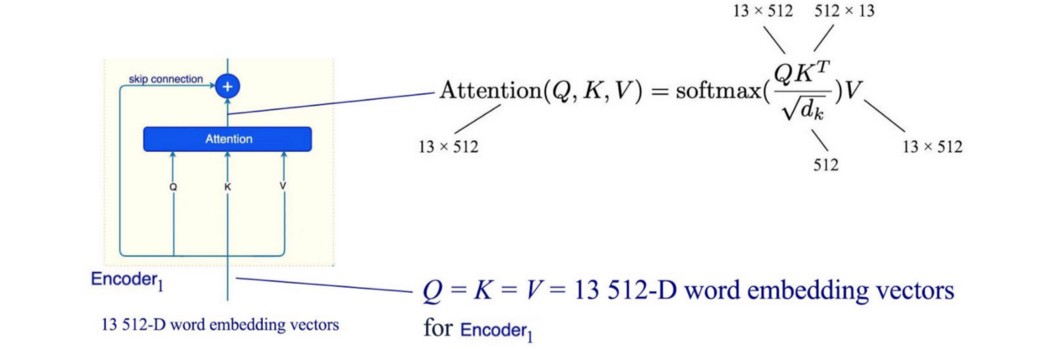
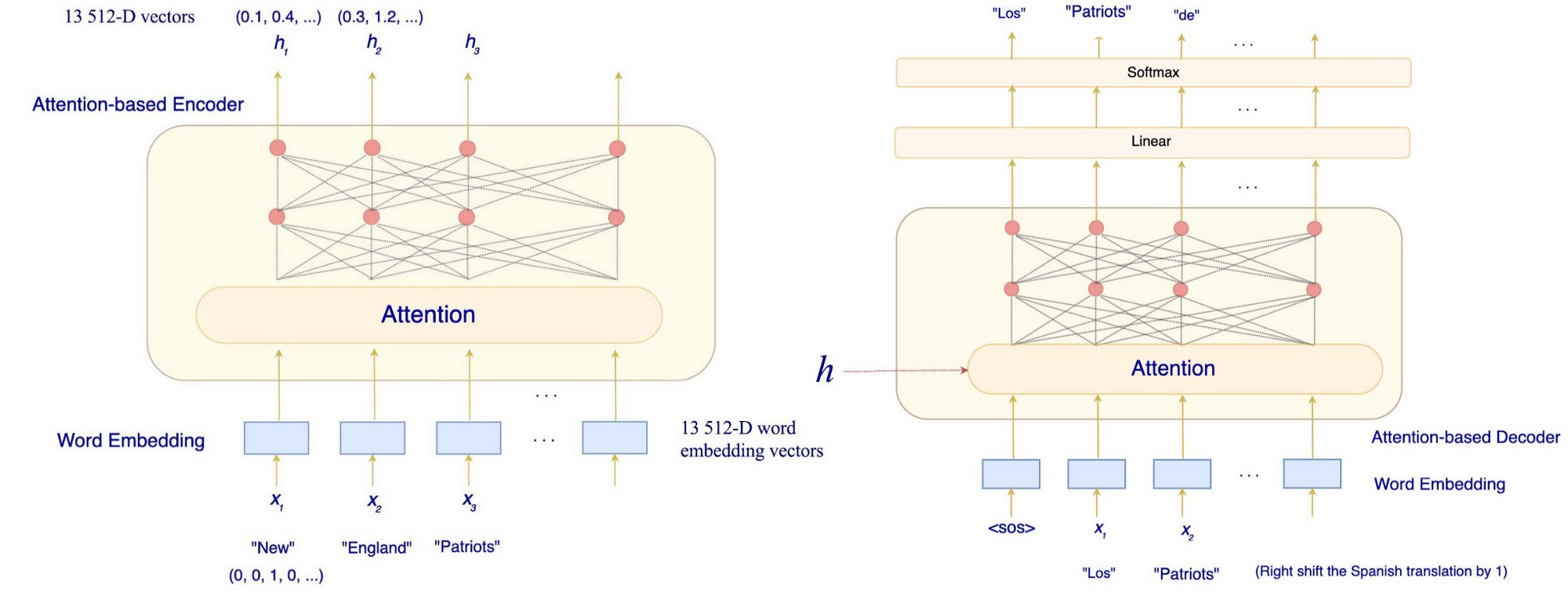
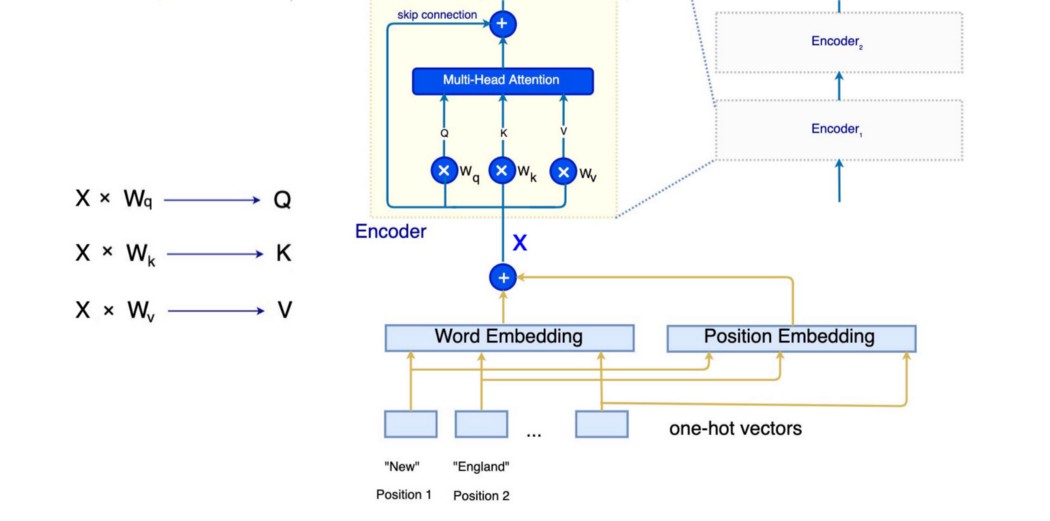
通过 Q₁ 到 Q₂₁,我们生成了一个代表句子的 21 个注意力(向量)序列。 Transformer Encoder 让我们了解更多细节。 但是在演示中,我们使用了下面的句子,它只包含 13 个单词。 New England Patriots win 14th straight regular-season game at home in Gillette stadium. 在编码步骤中,Transformer 使用学习的词嵌入将这 13 个词转换为 13 512-D 词嵌入向量。 然后它们被传递到基于注意力的编码器中,为每个单词生成上下文相关的表示。 每个词嵌入将有一个输出向量 hᵢ。 在我们在这里建立的模型中,hᵢ 是一个 512-D 向量。 它使用上下文对单词 xᵢ 进行编码。
让我们进一步放大这个基于注意力的编码器。 编码器实际上堆叠了 6 个编码器,每个编码器如下所示。 编码器的输出被馈送到上面的编码器。 此示例采用 13 512-D 向量并输出 13 512-D 向量。 对于第一个解码器(编码器₁),输入是 13 512-D 词嵌入向量。
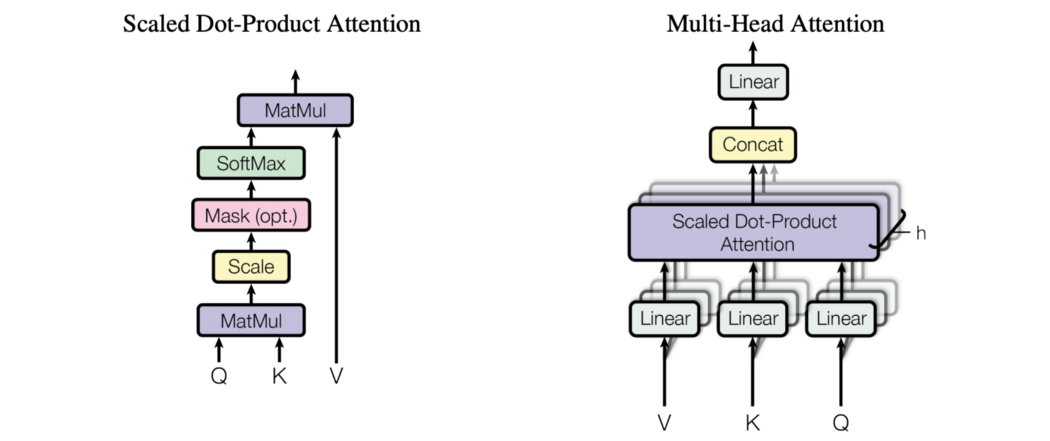
Scaled Dot-Product Attention 在每个编码器中,我们首先执行注意力。 在我们的示例中,我们有 13 个单词,因此有 13 个查询。 但我们不会单独计算他们的注意力。
相反,所有 13 个注意力都可以同时计算。我们将查询、键和值分别打包到矩阵 Q、K 和 V 中。每个矩阵的维度为 13 × 512 (d=512)。矩阵乘积 QKᵀ 将测量查询和键之间的相似性。 但是,当维度 d 很大时,我们会遇到点积 QKᵀ 的问题。假设这些矩阵中的每一行(q 和 k)包含均值为 0 和方差为 1 的独立随机变量。那么它们的点积 q·k 将具有均值 0 和方差 d(512)。这将推动一些点积值非常大。这可以将 softmax 输出移动到一个低梯度区域,这需要对点积进行较大的更改才能使 softmax 输出发生明显变化。这会影响训练进度。为了纠正这个问题,Transformer 用一个等于维度根的比例因子来划分点积。 Multi-Head Attention 在最后一节中,我们为每个查询生成一个注意力。
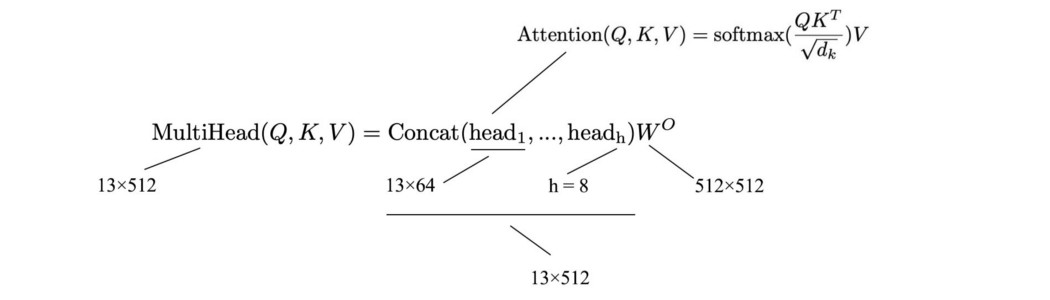
Multi-Head Attention 为每个查询生成 h 个注意力。 从概念上讲,我们只是将 h 缩放的点积注意力放在一起。
例如,下图显示了两个注意力,一个是绿色的,另一个是黄色的。
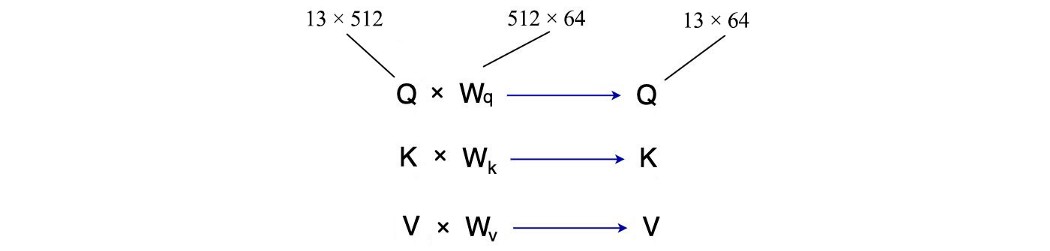
在 Transformer 中,我们每个查询使用 8 个注意力。 那么为什么我们需要 8 个注意力而不是 1 个注意力,因为每个注意力都可以覆盖多个区域? 在 Transformer 中,我们不直接将 Q、K 和 V 馈送到注意力模块。 我们首先用可训练矩阵 Wq、Wk、Wv 分别变换 Q、K 和 V。
如果我们使用 8 个注意力,我们将在上面有 8 组不同的预测。 这给了我们8个不同的“perspectives”。 这最终会提高整体准确度,至少在经验上是这样。 但是,我们希望保持计算复杂度相似。 因此,我们没有让转换后的 Q 具有 13 × 512 的维度,而是将其缩小到 13 × 64。但是现在,我们有 8 个注意力和 8 个转换后的 Q。
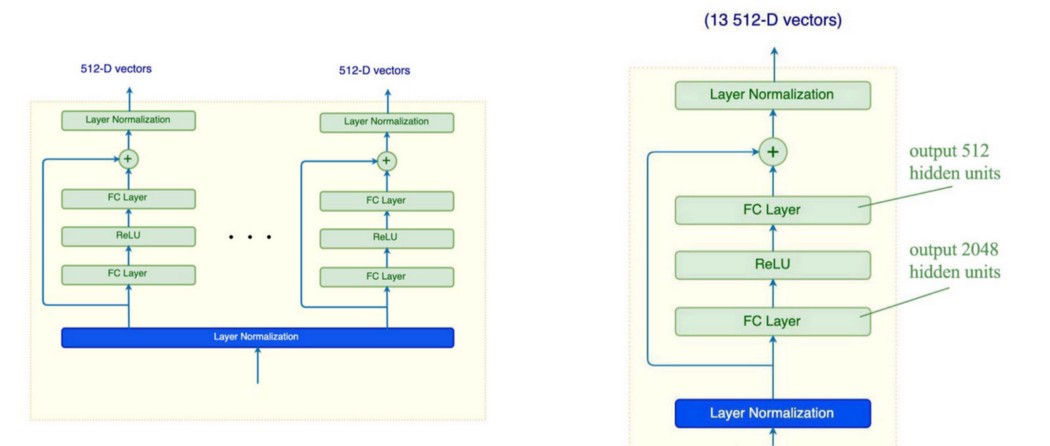
输出是所有 Scaled Dot-Product Attentions 的结果的串联。 最后,我们对与 W 的连接结果应用线性变换。注意,我们将模型描述为 8 个独立的头,但在编码中,我们将所有 8 个头打包成一个多维张量,并将它们作为一个单元进行操作。 Skip connection & Layer normalization 这是使用多头注意力的编码器。
如图所示,Transformer 将skip连接(ResNet 中的residual blocks)应用于多头注意力的输出,然后进行层归一化。 这两种技术都使训练更容易、更稳定。 在批量归一化中,我们根据从训练批次中收集的均值和方差对输出进行归一化。 在层归一化中,我们使用同一层中的值来执行归一化。 我们不会进一步详细说明它们,理解它们对于学习 Transformer 并不重要。 这只是一种使训练更稳定、更容易的常用技术。 Position-wise Feed-Forward Networks 接下来,我们将一个全连接层 (FC)、一个 ReLU 激活和另一个 FC 层应用于注意力结果。 此操作分别相同地应用于每个位置(共享相同的权重)。 这是一个位置前馈,因为第 i 个输出仅取决于注意力层的第 i 个注意力。
与注意力类似,Transformer 也使用了skip连接和层归一化。 Positional Encoding Politicians are above the law. 这听起来大错特错。 但它表明单词的位置或相对位置很重要。
卷积层使用有限大小的过滤器来提取局部信息。 因此,对于第一句话,“nice”将与“for you”而不是“requests”相关联。 然而,Transformer 一次用它的所有上下文对一个单词进行编码。 一开始,“you”在编码“nice”这个词时将被视为与“请求”类似。 我们只是希望模型最终能够提取和利用位置和排序信息。 如果失败,输入的行为就像一袋单词,并且上面的两个句子都将进行类似的编码。 一种可能的解决方案是提供位置信息作为词嵌入的一部分。
那么,我们如何将位置 i 编码为 512-D 输入向量呢? 下面的等式用于固定位置嵌入。 这个位置嵌入向量有 512 个元素,与词嵌入相同。 偶数元素使用第一个方程,奇数元素使用第二个方程来计算位置值。 一旦计算出来,我们将位置嵌入与原始词嵌入相加,形成新的词嵌入。
下图将 512-D 嵌入中前 50 个位置的位置嵌入值着色。 右侧的颜色条表示值。 如下所示,位置嵌入中的早期元素将比后面的元素(深度)更频繁地重复其位置值。
对于单词 i 的 k 位置,其 PE 值将接近于 PEᵢ 和 k 的线性函数。 这允许模型发现和利用单词之间的相对位置来产生注意力。 即使没有固定位置嵌入,我们也可以认为模型权重最终会学习如何考虑相对位置。 也许,我们只是不希望相同的权重用于两个目的——发现上下文和相对位置。 所以在第二种方法中,我们重新制定了注意力公式并引入了两个参数(一个用于值,一个用于键),它们考虑了单词的相对位置。
在为第 i 个单词生成注意力 zᵢ 时,我们使用下面的 aᵢⱼ 调整第 j 个单词的贡献。 我们没有固定它们的值,而是让它们可训练。 (细节)
aᵢⱼ 对绝对位置建模——第 i 个和第 j 个单词。 也许,我们只关心相对距离。 我们应该将 a(3, 9) 视为与 a(5, 11) 相同。 因此,我们不是对 a(i, j) 建模,而是对 w(k) 建模,其中 k 是距离 j-i。 在上面的等式中,我们简单地将 a(i, j) 替换为 w(j-i)。 另外,我们剪辑距离。 任何离 k 更远的地方,我们将其剪裁为 w(k) 或 w(-k)。 因此,我们只需要学习 2×k + 1 组参数。 如果您想了解更多信息,请参阅原始研究论文。
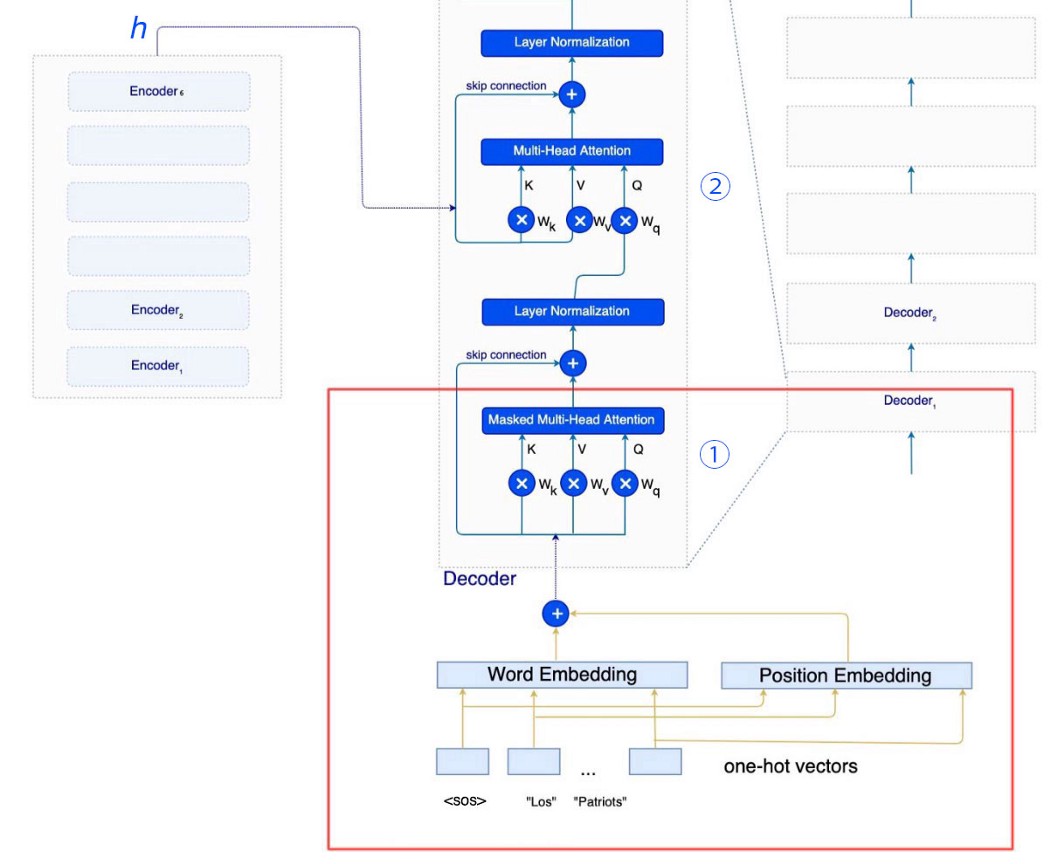
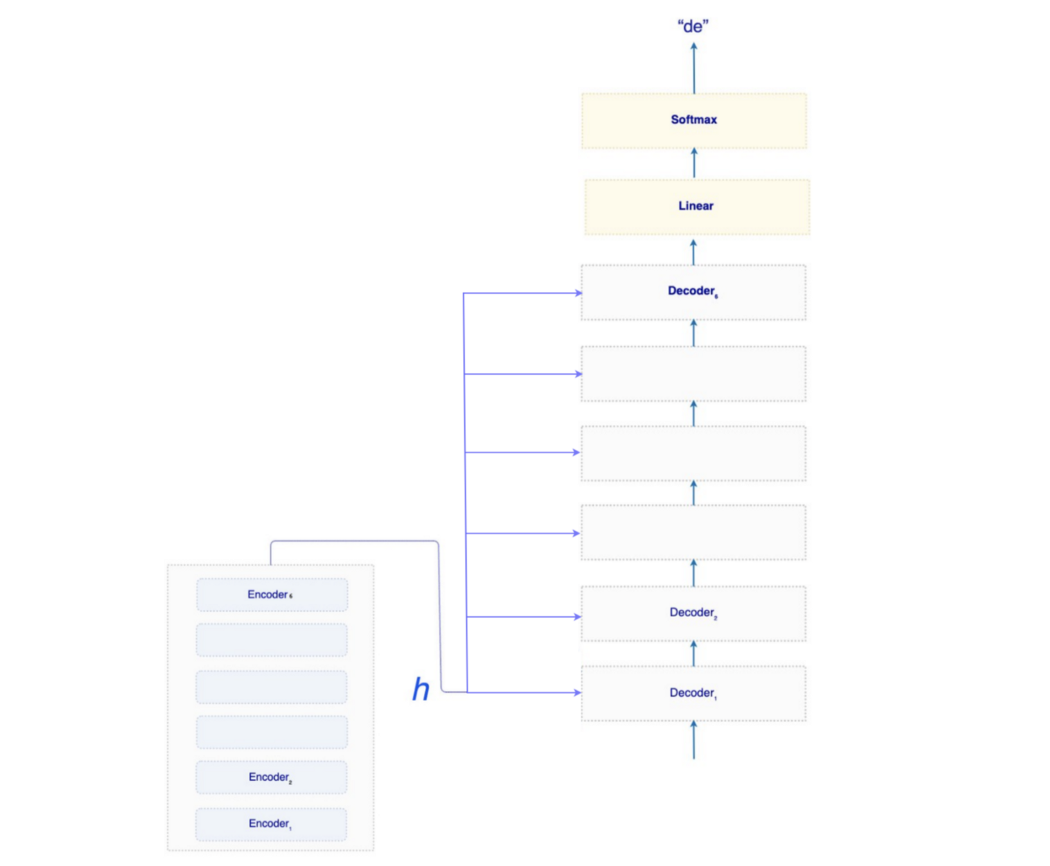
Transformer 使用固定位置嵌入,因为它具有与其他方法相似的性能,但它可以处理比训练的序列长度更长的序列长度。 这是编码器。 接下来,我们将讨论解码器。 不过,这部分是可选的,因为 BERT 仅使用编码器。 很高兴知道解码器。 但是比较长,也比较难理解。 Transformer Decoder 编码器生成向量表示 h 来表示输入句子。 该表示将在训练期间由解码器使用或在推理中解码序列。
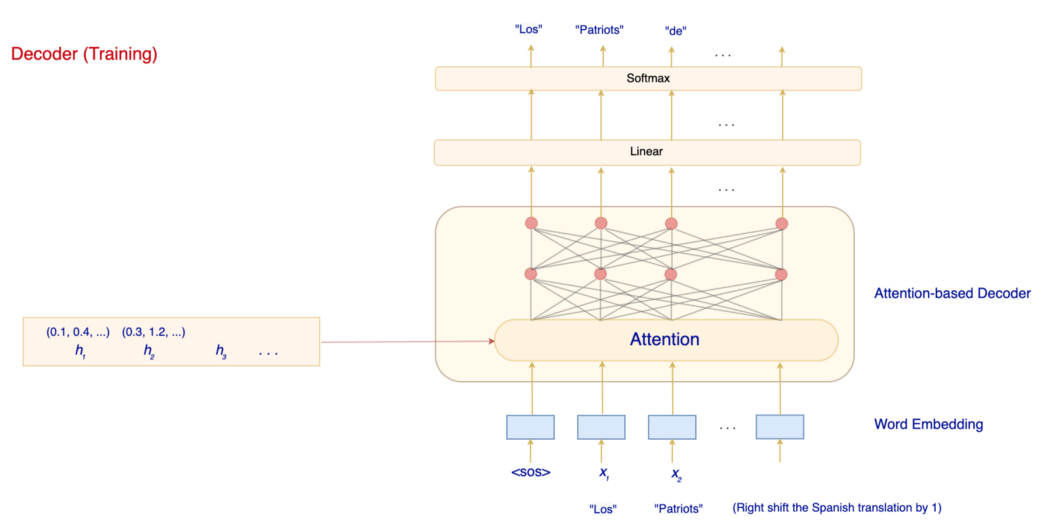
回想起来,注意力可以由查询、键和值组成。 对于解码器,向量表示 h 将用作基于注意力的解码器的键和值。 在训练中,解码器的第一个输入标记将是 <sos>(字符串的开头)。 输入的其余部分包含目标词,即 <sos>、Los、Patriots、de 等……但是让我们推迟对基于注意力的解码器的讨论,先介绍一些更容易的事情。
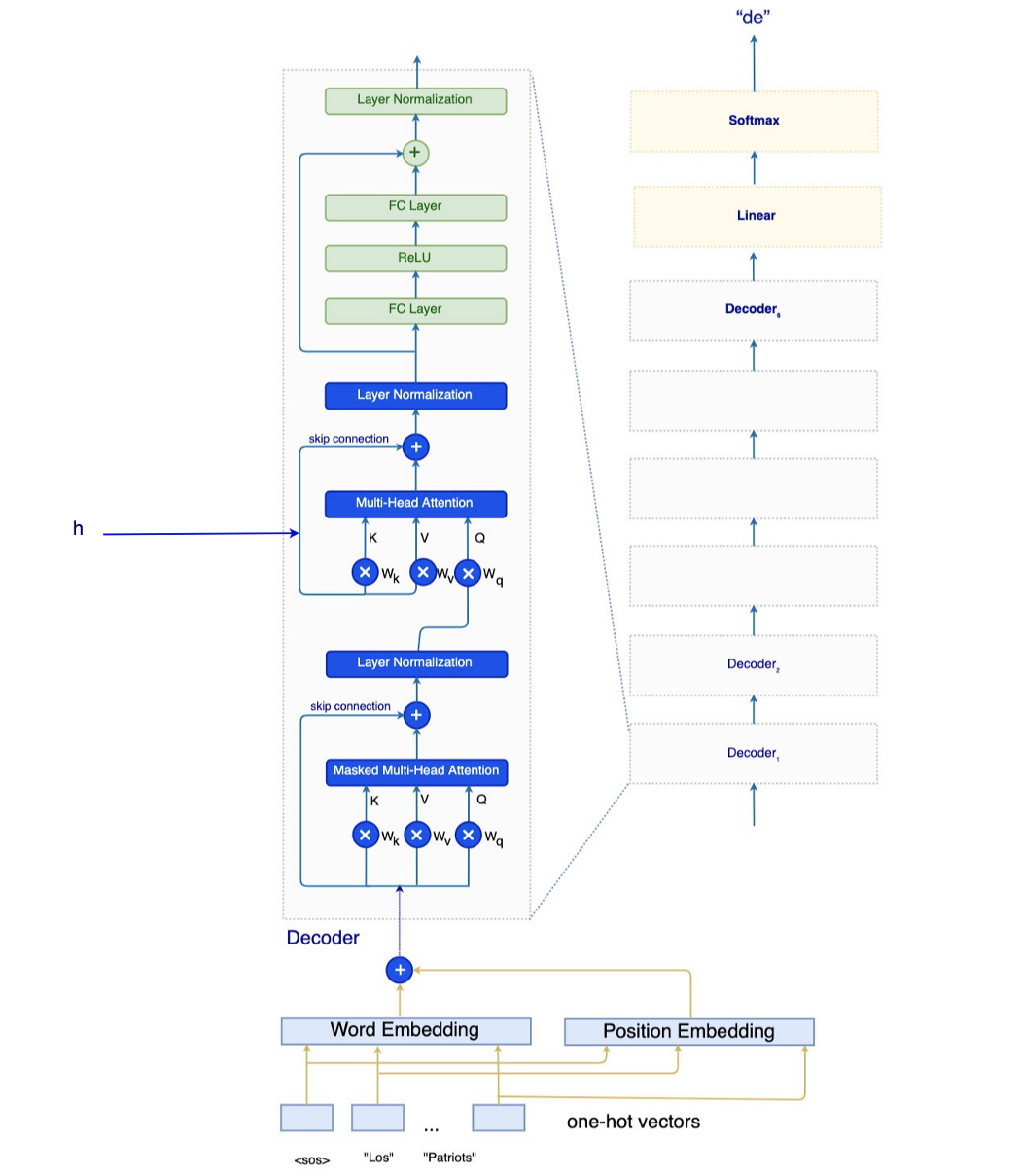
训练中的嵌入和 Softmax 我们将注意力解码器的输出拟合到线性层,然后使用 softmax 进行单词预测。 这个线性层实际上是嵌入层的反面。
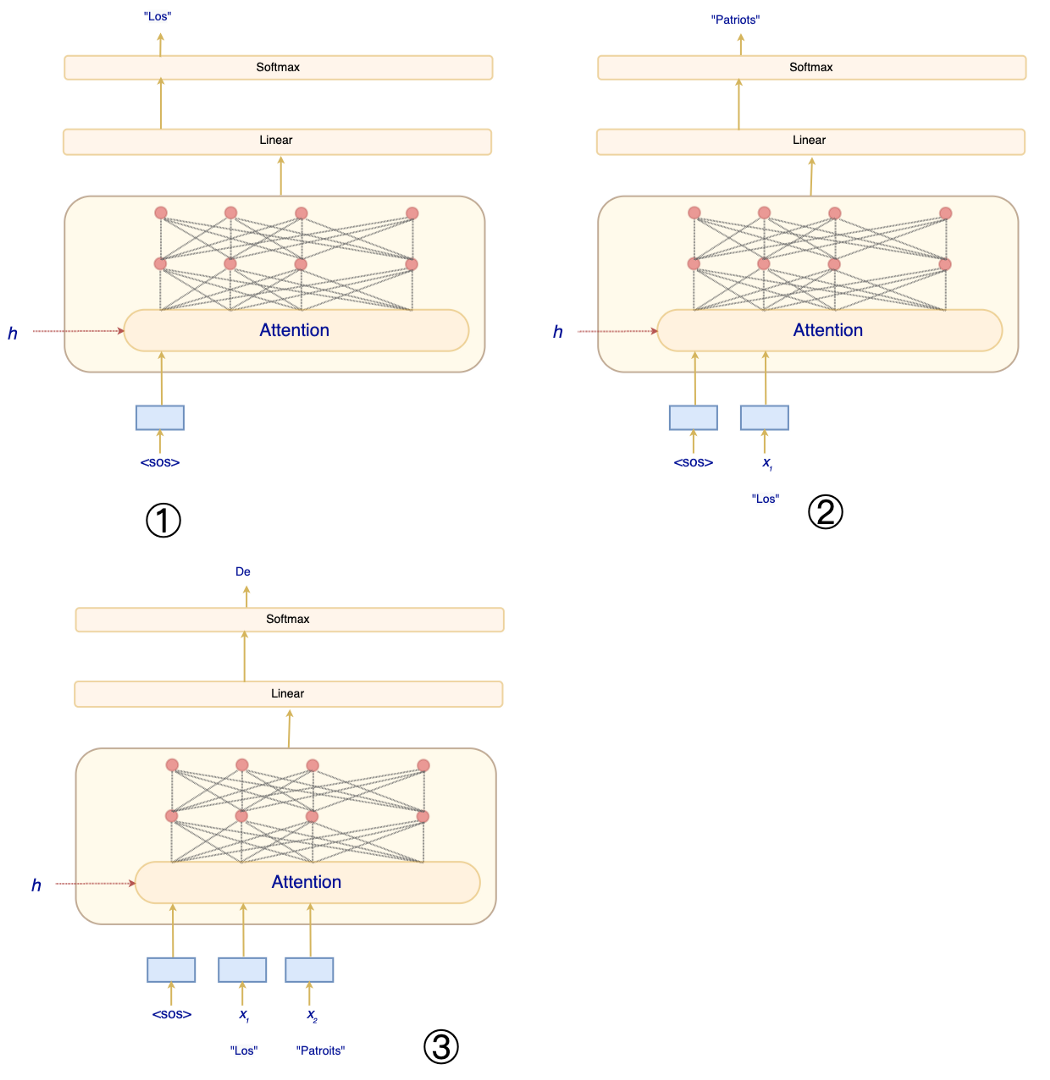
编码器-解码器模型包含两个词嵌入层——一个用于编码器,一个用于解码器。 两者都将使用相同的学习嵌入。 对于刚刚提到的线性层,我们将使用嵌入中的权重来推导它的权重(也就是它的逆)。 经验结果表明,当我们共享所有这些参数时,准确性会有所提高。 推理 在推理中,我们一次预测一个词。 在下一个时间步,我们收集所有先前的预测并将它们提供给解码器。 所以在下面的时间步③中,输入将是 <sos>, Los, Patriots。
Encoder-decoder attention(可选) 让我们回到编码器-解码器注意力的细节。 回想一下,在编码器中,我们应用线性变换分别从输入词嵌入 X 创建 Q、K 和 V。
对于 Transformer 解码器,注意力分两个阶段完成。
Stage①类似于编码器。 K、V 和 Q 来自输入嵌入。 这为Stage②所需的查询准备了向量表示。
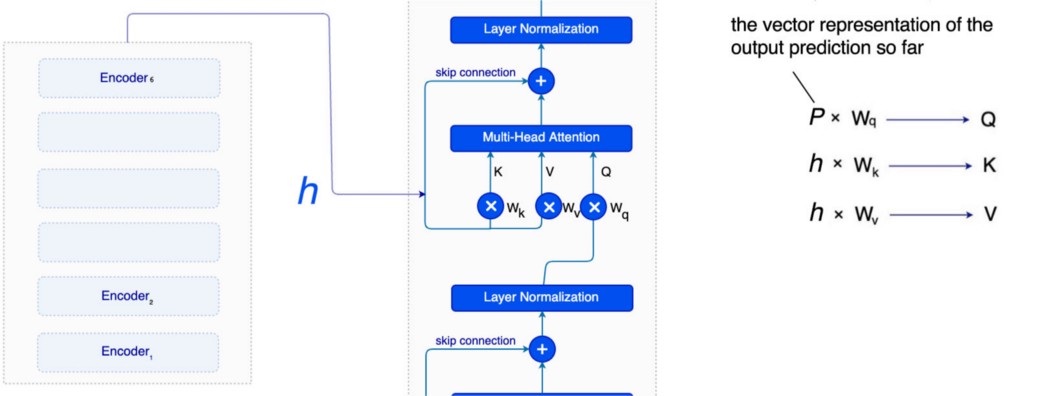
但是在Stage②,K和V是从h(来自编码器)推导出来的。
一旦计算出注意力,我们就将其传递给 Position-wise Feed-Forward Network。 注意力解码器将这 6 个解码器堆叠起来,最后一个输出通过一个线性层,然后是一个 softmax 来预测下一个单词。
并且 h 被馈送到每个解码器。
这是整个 Transformer 的示意图。
训练(可选) 在训练期间,我们确实知道基本事实。 注意模型不是时间序列模型。 因此,我们可以一次计算所有输出预测。
但是,对于位置 i 的预测,我们确保注意力只能看到从位置 1 到 i-1 的 ground truth 输出。 因此,我们在注意力中添加一个掩码,以在为位置 i 创建注意力时屏蔽来自位置 i 及其他位置的信息。
Soft Label (Optional) 为了避免过度拟合,训练还使用了 dropout 和标签平滑。 通常,我们希望地面实况标签的概率为 1。 但是将其推到一个也可能使模型过拟合。 标签平滑将地面实况标签的概率预测目标定为较低的值(例如 0.9),而非地面实况的概率预测要高于 0(例如 0.1)。 这样可以避免对特定数据过于自信。 简而言之,对数据点过度自信可能是过度拟合的迹象,并会伤害我们在推广解决方案时。 这都是关于transformer的。 NLP 任务 到目前为止,我们的讨论集中在序列到序列的学习上,比如语言翻译。 虽然这类问题涵盖了广泛的 NLP 任务,但还有其他类型的 NLP 任务。 例如,在问答 (QA) 中,我们希望在段落中找出有关所提问题的答案。
还有另一种类型的 NLP 任务,称为自然语言推理 (NLI)。 每个问题都包含一对句子:一个前提和一个假设。 给定一个前提,NLI 模型预测一个假设是真、假还是不确定。
下面的代码是 NLP 中的另外两个应用程序。 第一个决定了句子的情绪。 第二个在给定上下文的情况下回答一个问题。
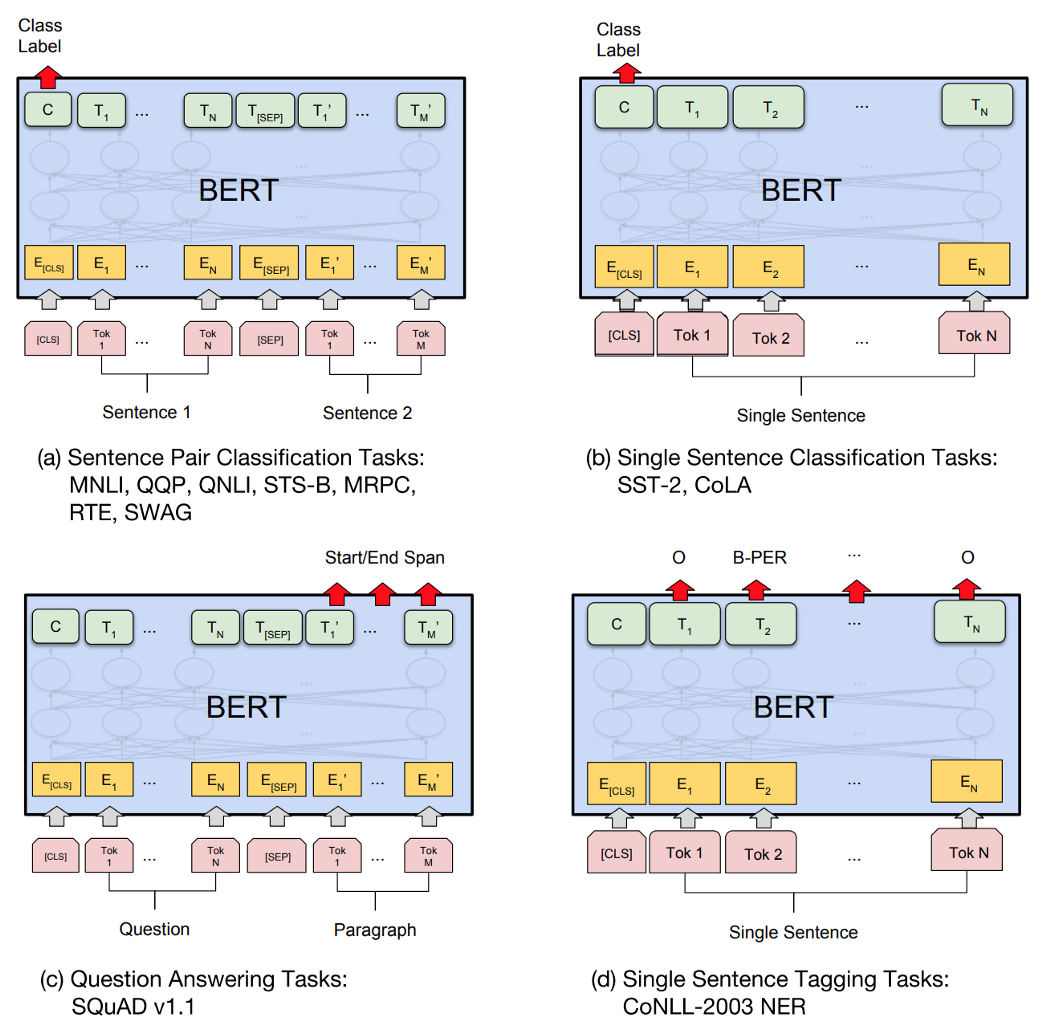
我们将演示 BERT 如何解决这些问题。 BERT(来自 Transformers 的双向编码器表示) 通过词嵌入,我们创建了词的密集表示。但是在 Transformer 部分,我们发现词嵌入不能很好地探索相邻词的上下文。在 NLI 应用程序中,我们希望模型能够处理两个句子。此外,我们想要一个多用途的表示模型。 NLP训练很激烈!我们可以预先训练一个模型并将其重新用于其他应用程序,而无需再次构建新模型吗? 让我们快速总结一下 BERT。在 BERT 中,模型首先使用不需要人工标记的数据进行预训练。完成后,预训练模型会输出输入的密集表示。为了解决其他 NLP 任务,比如 QA,我们通过简单地添加一个连接到原始模型输出的浅层 DL 层来修改模型。然后,我们使用特定于端到端任务的数据和标签重新训练模型。 简而言之,有一个预训练阶段,我们在其中创建输入的密集表示(下图左)。第二阶段使用特定于任务的数据(如 MNLI 或 SQuAD)重新调整模型,以解决目标 NLP 问题。
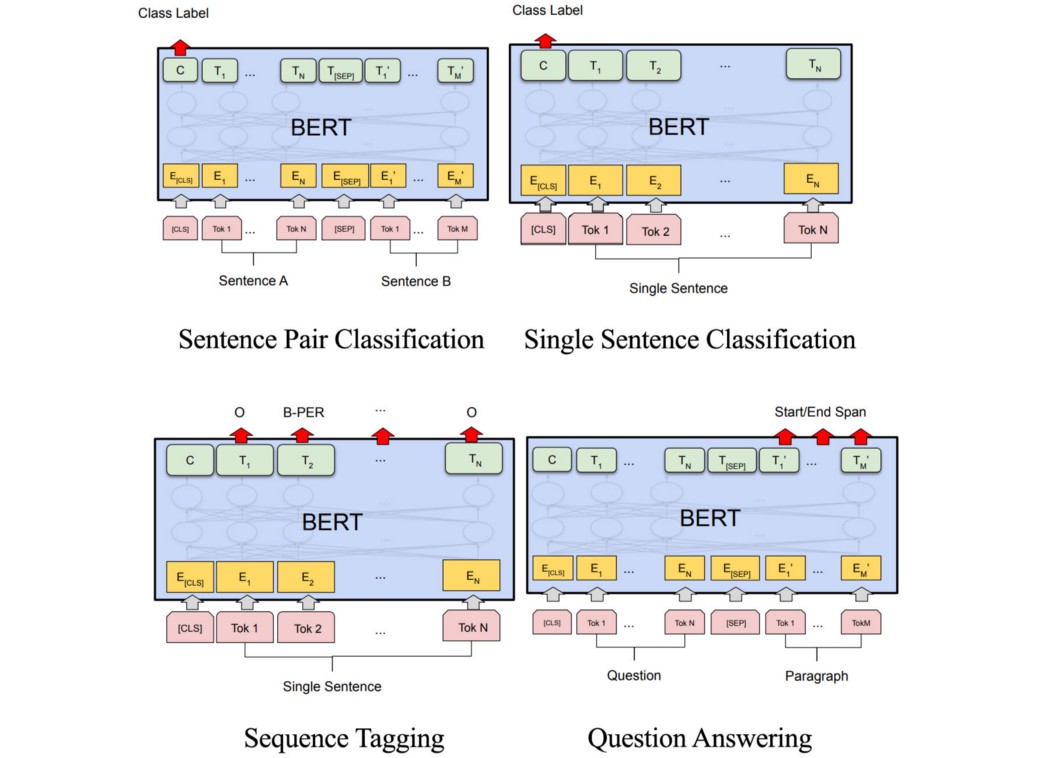
模型 BERT 使用我们讨论过的 Transformer 编码器来创建向量表示。 输入/输出表示 但首先,让我们定义输入的组合方式以及预训练模型的预期输出。 首先,模型需要采用一两个词序列来处理不同范围的 NLP 任务。
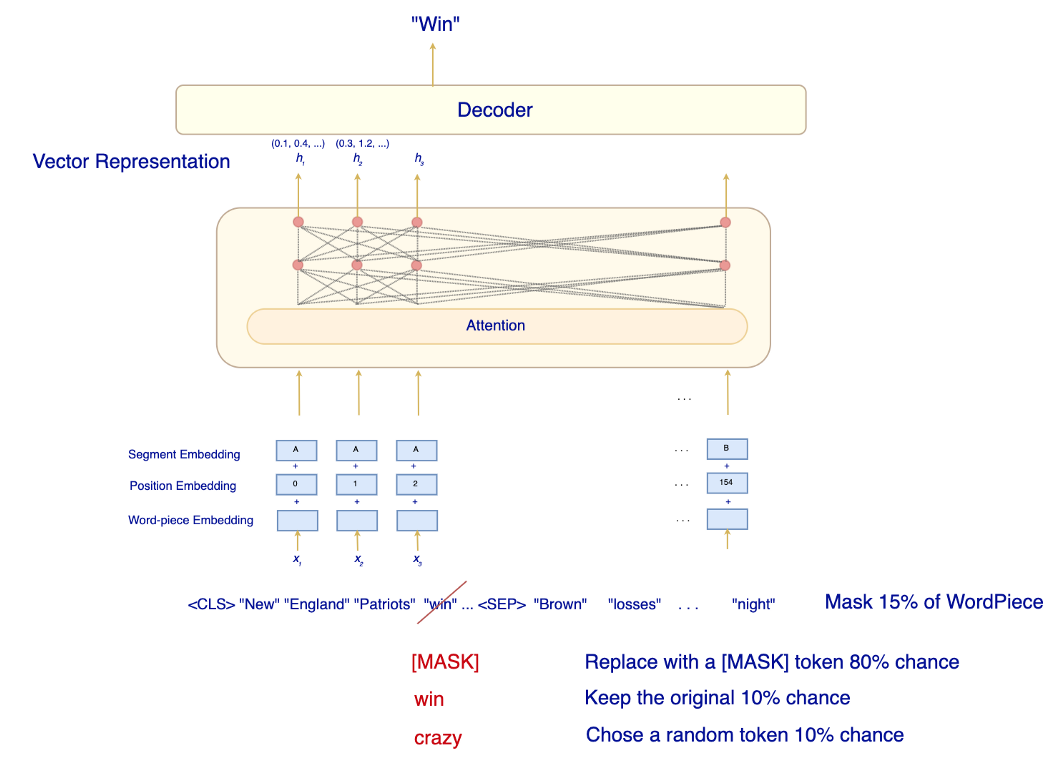
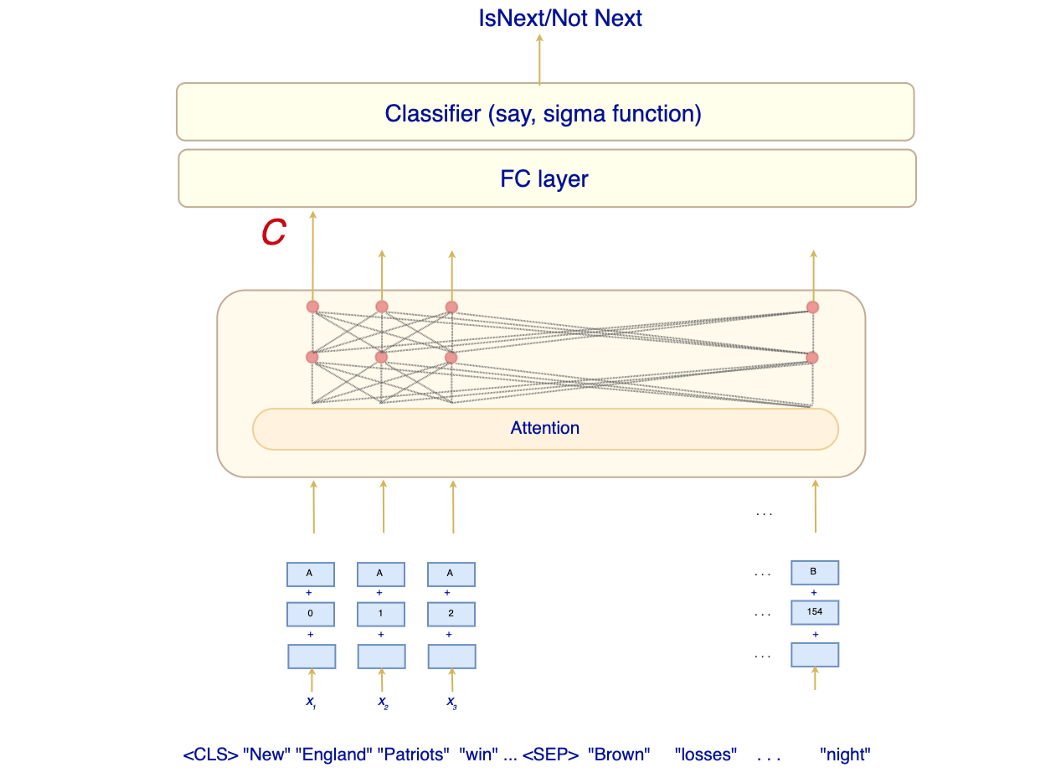
所有输入都将以特殊标记 [CLS](特殊分类标记)开头。 如果输入由两个序列组成,则 [SEP] 标记将放在序列 A 和序列 B 之间。 如果输入有 T 个标记,包括添加的标记,输出也将有 T 个输出。 输出的不同部分将用于对不同的 NLP 任务进行预测。 第一个输出是 C(或有时写为输出 [CLS] 标记)。 它是用于任何 NLP 分类任务的唯一输出。 对于只有一个序列的非分类任务,我们使用剩余的输出(没有 C)。
那么,我们如何组成输入嵌入呢? 在 BERT 中,输入嵌入由相同维度的词段嵌入、段嵌入和位置嵌入组成。 我们将它们加在一起形成最终的输入嵌入。
BERT 不是将每个单词都用作标记,而是将单词分解成单词片段以减少词汇量(30,000 个标记词汇)。例如,“helping”这个词被分解为“help”和“ing”。然后它应用嵌入矩阵 (V × H) 将用于“帮助”的 one-hot 向量 Rⱽ 转换为 Rᴴ。 段嵌入模型该标记属于哪个序列。令牌属于第一句还是第二句?所以它的词汇量为两个(段 A 或 B)。直观地说,它根据它是属于序列 A 还是 B 为嵌入添加一个常数偏移量。在数学上,我们应用嵌入矩阵 (2 × H) 将 R² 转换为 Rᴴ。最后一个嵌入是位置嵌入。它在 Transformer 中用于识别单词的绝对或相对位置的目的相同。 预训练 BERT 使用 2 个 NLP 任务预训练模型。 Masked LM 第一个是Masked LM(Masked Language Model)。我们使用 Transformer 解码器生成输入的向量表示,其中一些单词被屏蔽。
然后 BERT 应用浅深度解码器来重建单词序列,包括丢失的单词序列。
在 Masked LM 中,BERT 掩盖了 15% 的 WordPiece。 80% 的掩码 WordPiece 将被替换为 [MASK] 标记,10% 为随机标记,10% 将保留原始单词。 损失定义为 BERT 预测丢失单词的能力,而不是整个序列的重构误差。
我们不会用 [MASK] token替换 100% 丢失的 WordPiece。 这鼓励模型预测缺失的单词,而不是为考虑上下文的序列创建向量表示的最终目标。 BERT 用随机标记替换 10%,用原始词替换 10%。 这鼓励模型了解缺失单词的正确或错误。 Next Sentence Prediction (NSP) 第二个预训练任务是 NSP。 关键目的是在输出 C 中创建一个表示,它将编码序列 A 和 B 之间的关系。为了准备训练输入,大约 50% 的时间,BERT 分别使用两个连续的句子作为序列 A 和 B。 BERT 期望模型预测“IsNext”,即序列 B 应该跟随序列 A。在剩下的 50% 的时间里,BERT 随机选择两个词序列并期望预测是“Not Next”。
在本次训练中,我们取输出 C,然后用浅分类器对其进行分类。
如前所述,对于这两个预训练任务,我们从没有任何人工标签的尸体中创建训练。 这两个训练任务帮助 BERT 训练一个或两个词序列的向量表示。 除了上下文,它还可能发现其他语言学信息,包括语义和coreference。 微调 BERT 一旦模型经过预训练,我们就可以为任何 NLP 任务或解码器添加浅层分类器,类似于我们在预训练步骤中讨论的内容。
然后,我们拟合与任务相关的数据和相应的标签,以端到端地细化所有模型参数。 这就是模型的训练和改进方式。 所以 BERT 更多的是在训练策略而不是模型架构上。 它的编码器就是 Transformer 编码器。 SQuAD Fine-tuning 问答问题的微调略有不同。 给定第一个句子是问题,第二个句子(段落)作为上下文,我们希望在第二个句子中找到回答问题的开始和结束位置。 例如,问题是奥巴马是谁,上下文是“Obama borned in Hawaii and he served as the President of the United States.”。 该模型将返回“President of the United States”的开始和结束位置。
在微调中,我们将引入另外两个可训练向量 S 和 E。下面的 Tᵢ 与上图中的 T'ᵢ 相同。 (T'是第二句位置对应的输出。)。 S、E 和 Tᵢ 是向量并且具有相同的维度。
点积 S Tᵢ 评分答案从位置 i 开始的可能性,点积 E Tᵢ 评分答案在位置 i 结束的可能性。 我们在计算概率时将它们传递给 softmax 函数。 有了上面的概率,我们计算了一个与地面实况相比较的损失函数,并训练 S、E 和所有其他参数。 模型 但 BERT 中的模型配置与 Transformer 论文不同。 以下是用于 BERT 中的 Transformer 编码器的示例配置。
例如,基本模型堆叠了 12 个解码器,而不是 6 个。每个输出向量有 768 维,注意力使用 12 个头。 Source Code 对于那些对 BERT 源代码感兴趣的人,这里是来自 Google 的源代码。 对于 Transformer,这里是源代码。 搜索 复制 |