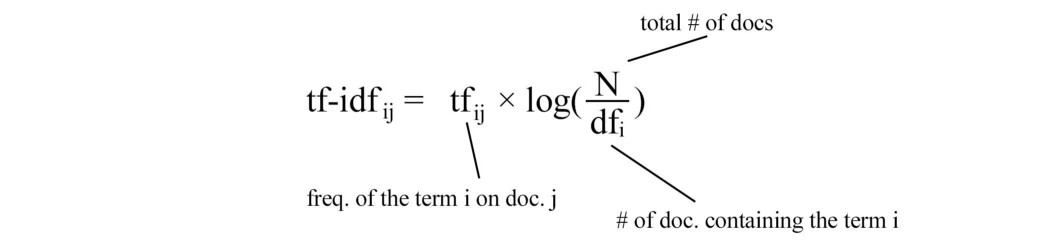|
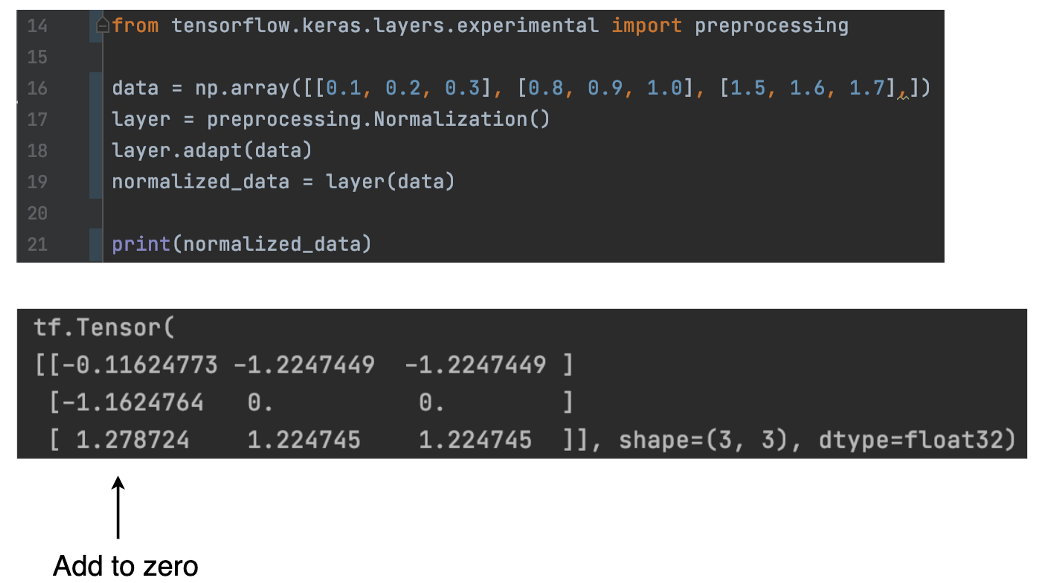
虽然 Keras 提供了深度学习层来创建模型,但它还提供了 API 来预处理数据。 例如, preprocessing.Normalization() 使用特征均值和训练数据集的方差对特征进行归一化。 这些参数不是可训练参数的一部分。 相反,在第 18 行,我们将归一化层“调整”到训练样本(“数据”)。 此方法将自动计算均值和方差。
在我们的第二个示例中,我们将 TextVectorization 层调整为语料库“数据”。 它创建一个词汇表并映射到整数词索引——词汇表中的第 i 个词将映射到整数 i。 这些映射将文本转换为整数单词索引序列。 “数据”包含 8 个样本,在经过 TextVectorization 层处理时将转换为 8 个整数向量。
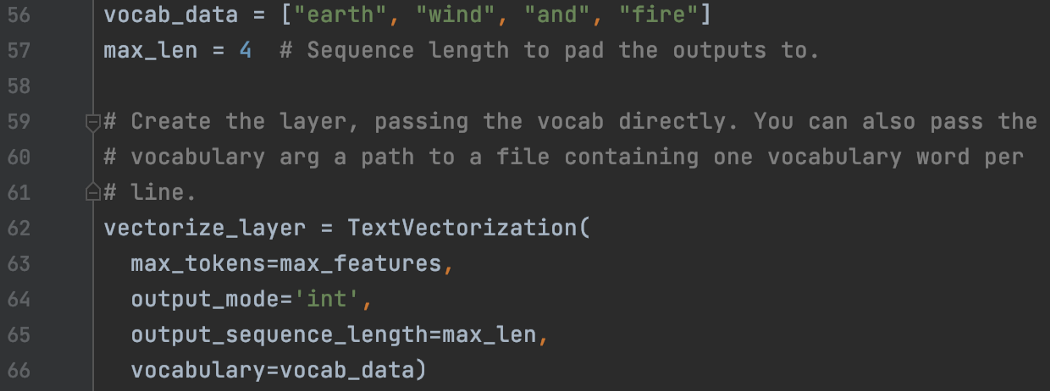
但有时,我们会绕过“adapt”调用。 相反,我们在预处理层实例化时直接传递词汇表。
例如,在训练期间,我们为训练样本调整了一个层。 然后,我们从层中提取所需的信息(比如词汇表)。 在生产过程中,我们重新加载此信息以在没有原始训练数据集的情况下重新创建相同的预处理层。 提供的预处理层 以下是不同的内置预处理层。 它们包括图像处理、图像数据增强和结构化数据预处理。
重新缩放和调整大小是预处理成像数据中的常见操作。 在下面的代码中,我们将这些预处理应用为模型内的 Keras 层。
模型层与 预处理数据集 实际上,Keras 预处理在应用数据转换时提供了两种不同的选项。
在选项 1 中,预处理层是模型的一部分。它是模型计算图的一部分,可以在 GPU 等设备上进行优化和执行。如果 GPU 可用,这是归一化层和所有图像预处理和数据增强层的最佳选择。 选项 2 使用 dataset.map 转换数据集中的数据。数据扩充将在 CPU 上异步发生并且是非阻塞的。它的重点是利用 CPU 中的多线程。使用 dataset.prefetch,预处理可以相互重叠,也可以与 GPU 上的模型训练重叠。尽管如此,预处理逻辑不会在 SavedModel 中导出。它必须在生产部署期间复制到服务器上。选项 2 适用于 TextVectorization、结构化数据预处理以及 GPU 不可用于图像预处理层的情况。 注意:dataset.map 以图形模式运行。它只是不是模型的一部分。这就是为什么当您在映射函数中放置断点时,它不会停止!
导出模型 对于我们选择选项 2 进行训练的情况,我们仍然可以使用选项 1 在生产中部署解决方案。实际上,通过创建包括预处理层的新模型可以相对容易地完成。
训练后,我们创建这个新模型并将模型保存为 SavedModel。 保存的模型包含计算图,其中包括预处理层及其参数,如归一化层中的均值和方差。 通过将所有内容打包为一个单元,我们节省了在生产服务器上重新实现预处理逻辑的工作。 新模型可以直接获取原始文本而无需预处理。 这避免了生产过程中 preprocesing_layer 的配置丢失或不正确。 如果我们在生产中使用选项 2,我们需要使用训练使用的相同词汇来初始化 TextVectorization。 在一个 TextVectorization 层适配后,我们可以使用 layer.get_vocabulary 方法检索词汇并保存。
为了在生产中部署模型,我们使用相同的词汇表初始化一个新的 TextVectorization 层。 例如,在下面的第 66 行,我们应该使用已保存词汇的路径。
这是使用 set_vocabulary 配置 TextVectorization 的另一种方法,其中 vocab 是单词数组。
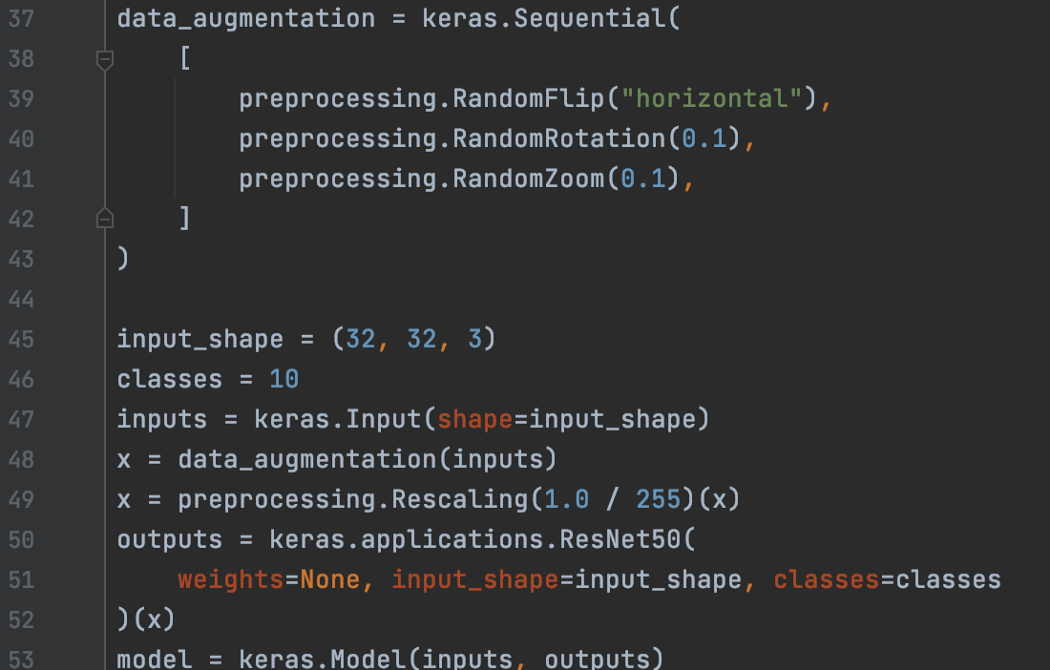
让我们通过一些示例来了解如何使用它们。 图像数据增强 Keras 的内置预处理层可用于增强图像数据。 在下面的代码中,我们随机翻转、旋转和缩放输入图像。 在此示例中,我们还应用了重新缩放层来重新缩放输入值。 因为这些层可以是计算图的一部分,所以预处理代码可以在 GPU 上运行。
如果数据增强层集成到模型中(选项 1),则仅在训练期间在 model.fit 中完成。 对 model.evaluate 或 model.predict 的图像没有影响。 对于选项 2,我们将有一个没有数据增强的数据集,而另一个在它之上的具有增强映射的数据集。 在训练中使用第一个数据集,在推理中使用第二个数据集。
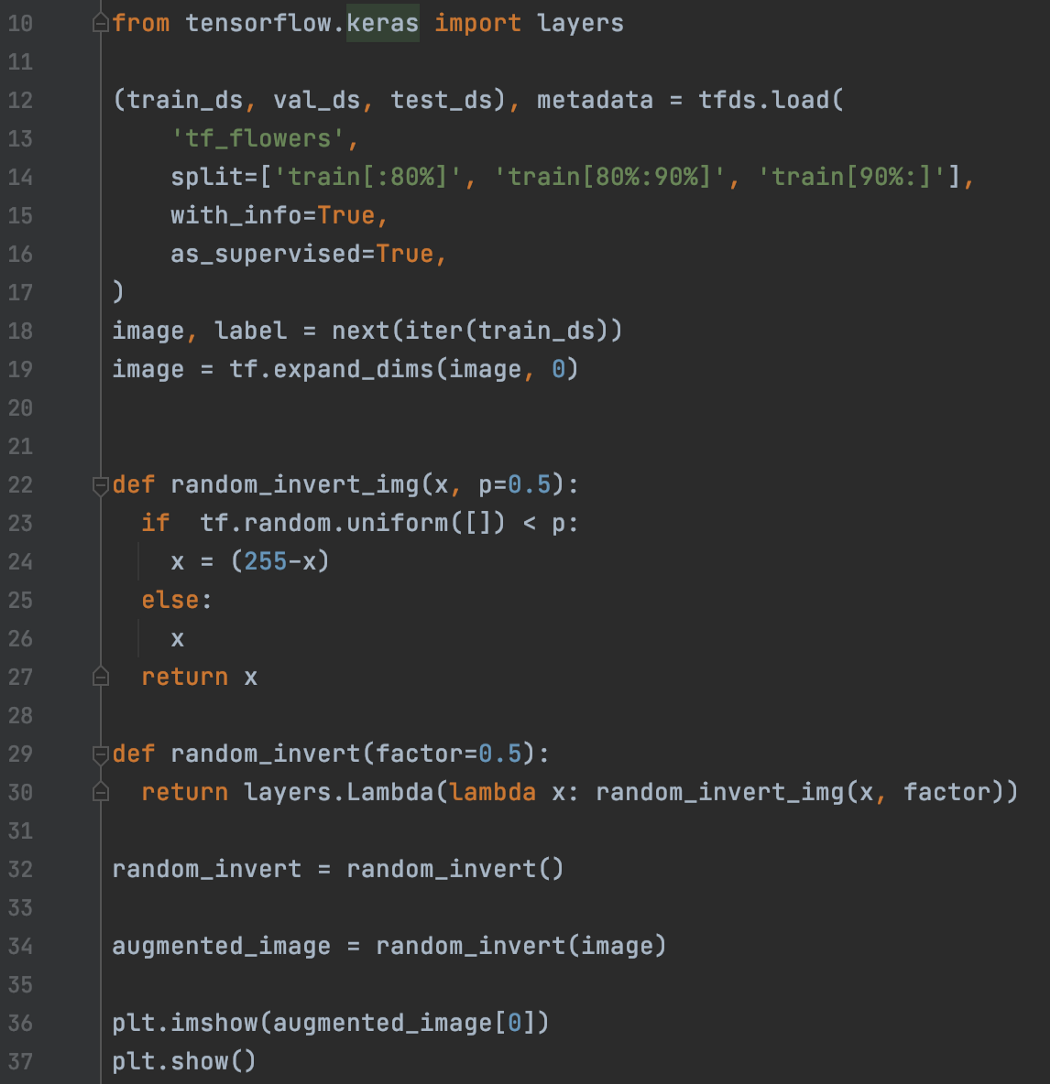
自定义数据增强 我们可以编写自己的数据增强层。 在下面的代码中,它随机反转图像并实现为 layers.Lamda 层。
或者我们可以通过继承 keras.layers.Layer 来实现它。
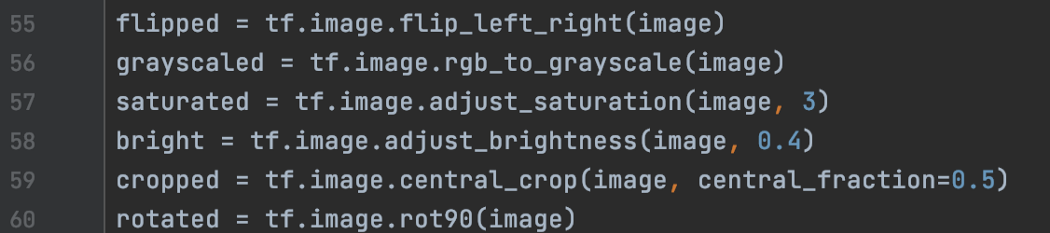
两种实现都可用于选项 1 和 2。 tf.image 我们还可以使用 tf.image 中的 API 来扩充图像。 例如,我们可以翻转、旋转、饱和等等……图像。
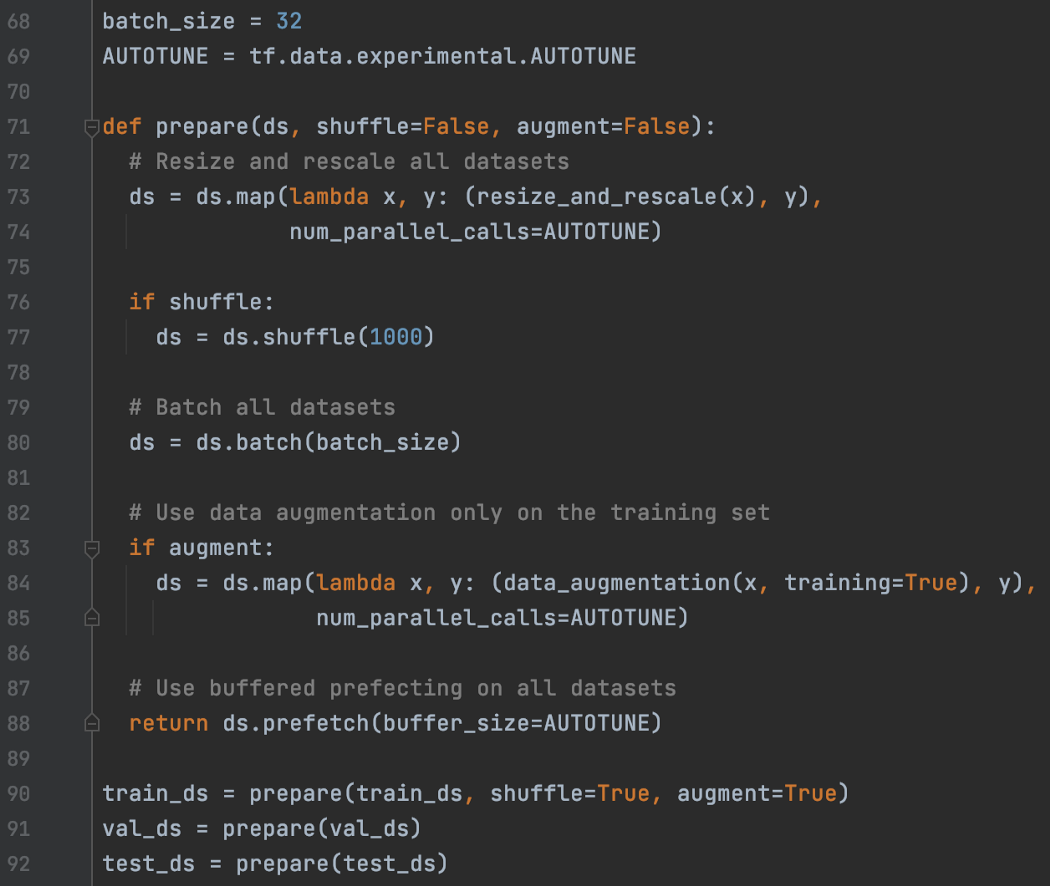
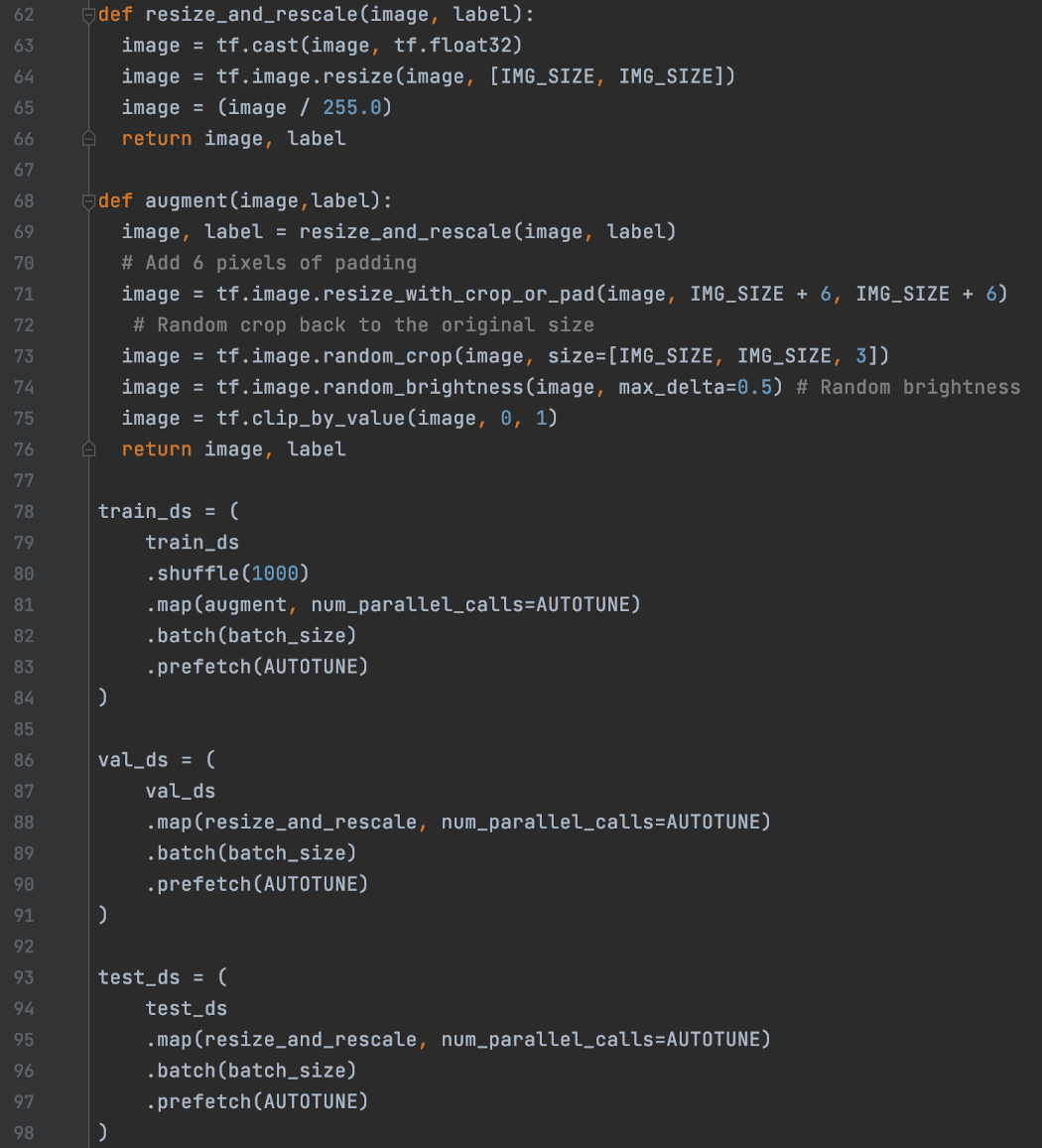
在下面的代码中,我们准备了 3 个数据集——训练、验证和测试。 对于训练数据集,我们使用 dataset.map 对数据集应用调整大小、重新缩放和扩充。 对于验证和测试数据集,我们只需对图像应用 resize 和 rescale。
Normalizing特征 在下面的代码中,我们加载 cifar10 数据集并展平张量。 第 57 行中 x_train 的形状现在变为 (50000, 3072)。 然后我们创建一个适应 x_train 的归一化层来生成均值和方差。 最后,从第 64 行到第 67 行,我们创建了一个带有归一化层的模型来归一化输入
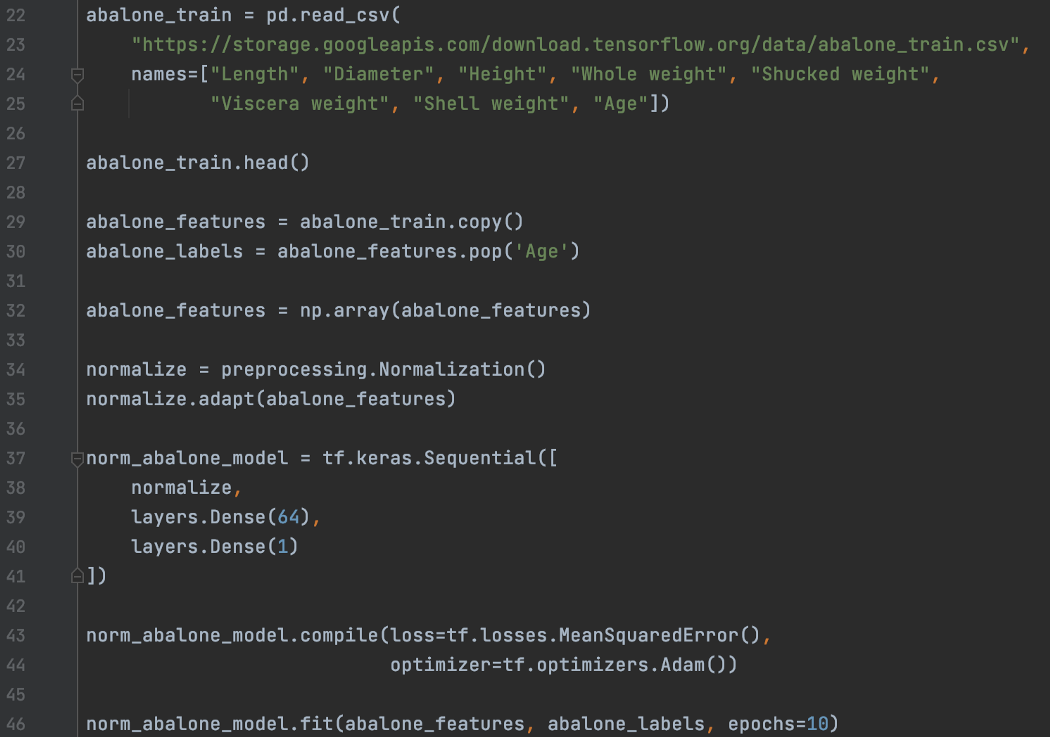
这是另一个示例,其中我们使用规范化来规范化 CSV 文件中的特征。
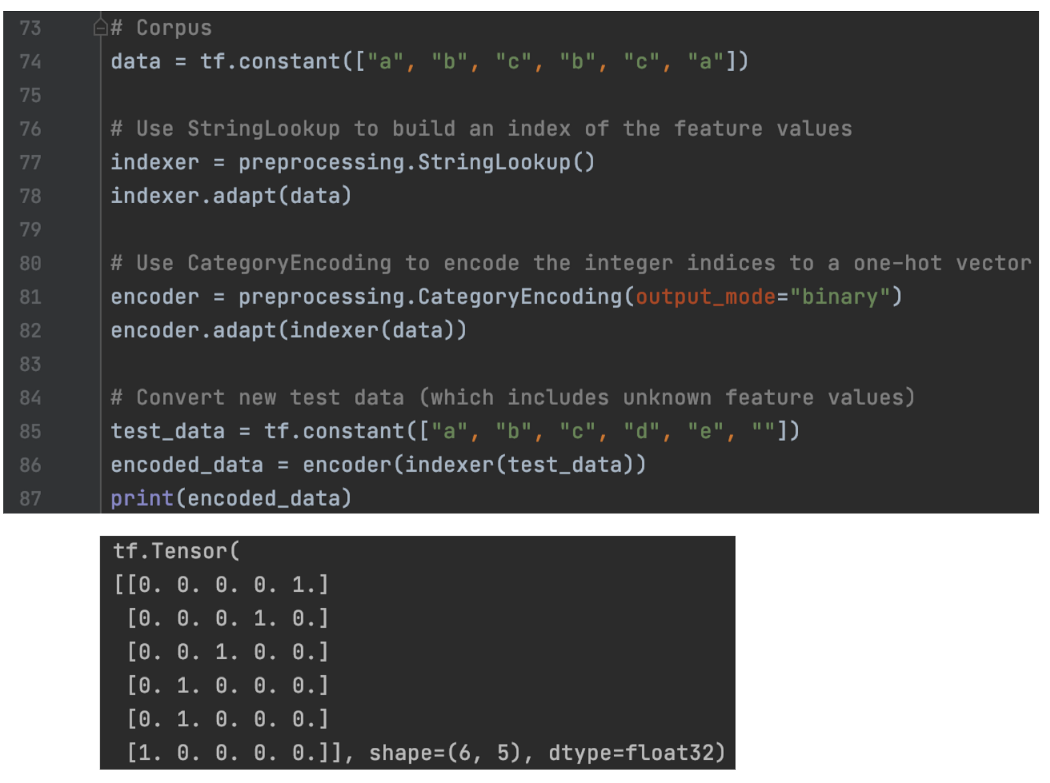
通过 one-hot 编码对分类特征进行编码 在此示例中,我们将分类特征转换为 one-hot 编码。 首先,我们将 StringLookup 改编为语料库,这样字符串(单词)可以表示为词汇表的索引,例如 4 表示“a”。 然后我们使用 CategoryEncoding 将索引转换为 one-hot 向量。 所以“a”变成了[0, 0, 0, 0, 1]。 “a”、“b”和“c”可以分别代表一个类别。 因此,构造层将类别特征转换为 one-hot 向量。
通过 one-hot 编码对整数分类特征进行编码 我们的下一个示例与之前的示例类似,它将输入转换为 one-hot 向量。 但是语料库包含数字而不是单词。
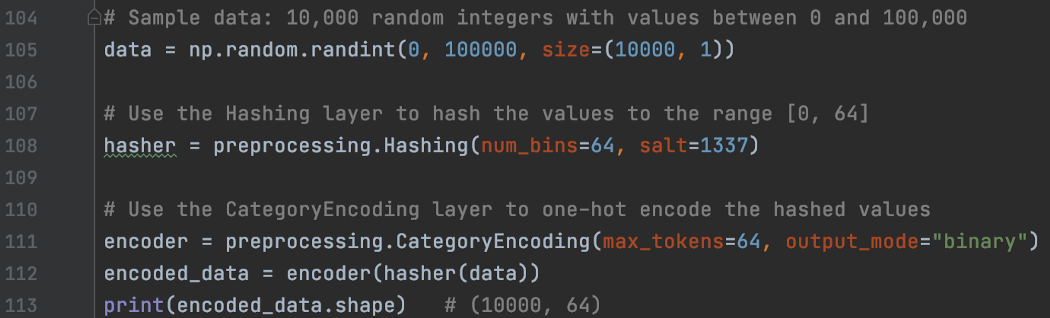
将散列应用于整数分类特征 对于可以取许多不同值(大约 10,000 或更高)并且每个值可能仅在训练数据中出现几次的输入分类特征,使用 one-hot-vector 对输入特征进行编码变得无效。 散列允许我们首先将这些特征映射到散列中的一个 bin。 然后,我们将 CategoryEncoding 应用于散列值以创建一个单热向量。 在下面的示例中,哈希层有 64 个 bin。 因此,在 CategoryEncoding 之后,每个样本将由一个 64 维的 one-hot 向量表示。
文本向量化 给定以下语料库“数据”的词汇表,我们可以使用词汇表的索引而不是字符串本身来表示单词。
例如,通过这个语料库,我们可以为每个单词生成一个索引,并使用该索引来表示一个单词。
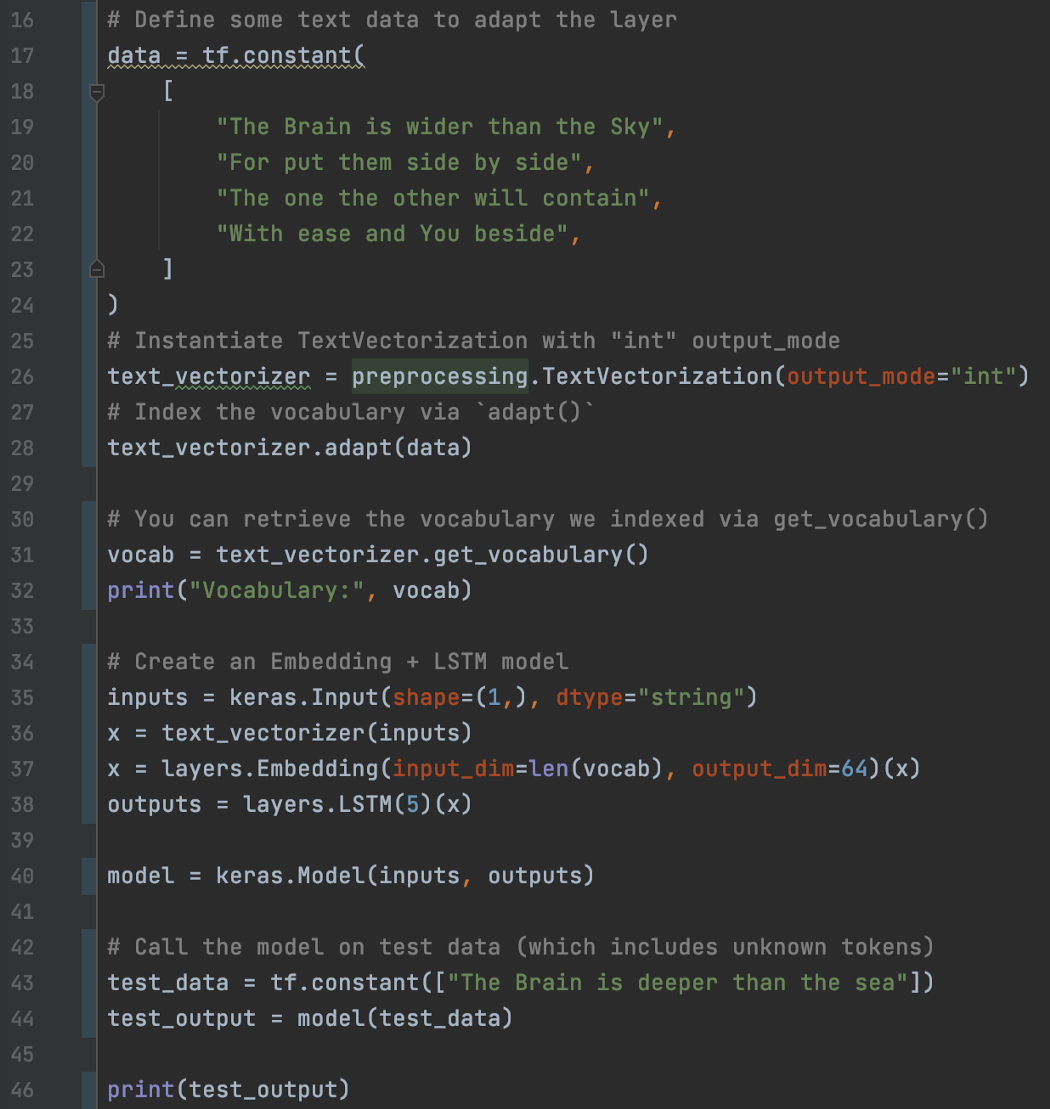
在此过程中,创建了两个特殊token。 0 用于填充将可变长度的时间序列输入转换为固定长度的输入。 1 表示词汇表外 (OOV) 单词的 [UNK]。 例如,在推理过程中,我们可能会遇到语料库中从未出现过的单词,因此我们将其标记为 [UNK]。 另一方面,我们可能会限制最大词汇量(在 TextVectorization 中使用 max_tokens),因此词汇表中的稀有词将被索引为 [UNK]。 在下面的示例中,我们使用 TextVectroization 将句子中的每个单词转换为词汇表的整数索引。 给定句子“大脑比海深”,TextVectroization 将其转换为包含 7 个整数索引的数组。
然后将其馈入嵌入层,该层为每个单词输出一个 64 维向量。 因此,我们的句子将具有 (7, 64) 的输出形状。 然后它连接到一个 LSTM,为这个句子输出一个 5 分量向量。 这是代码。
鉴于“The Brain is deeper than the sea”,整个句子被编码为一个 5 分量向量:
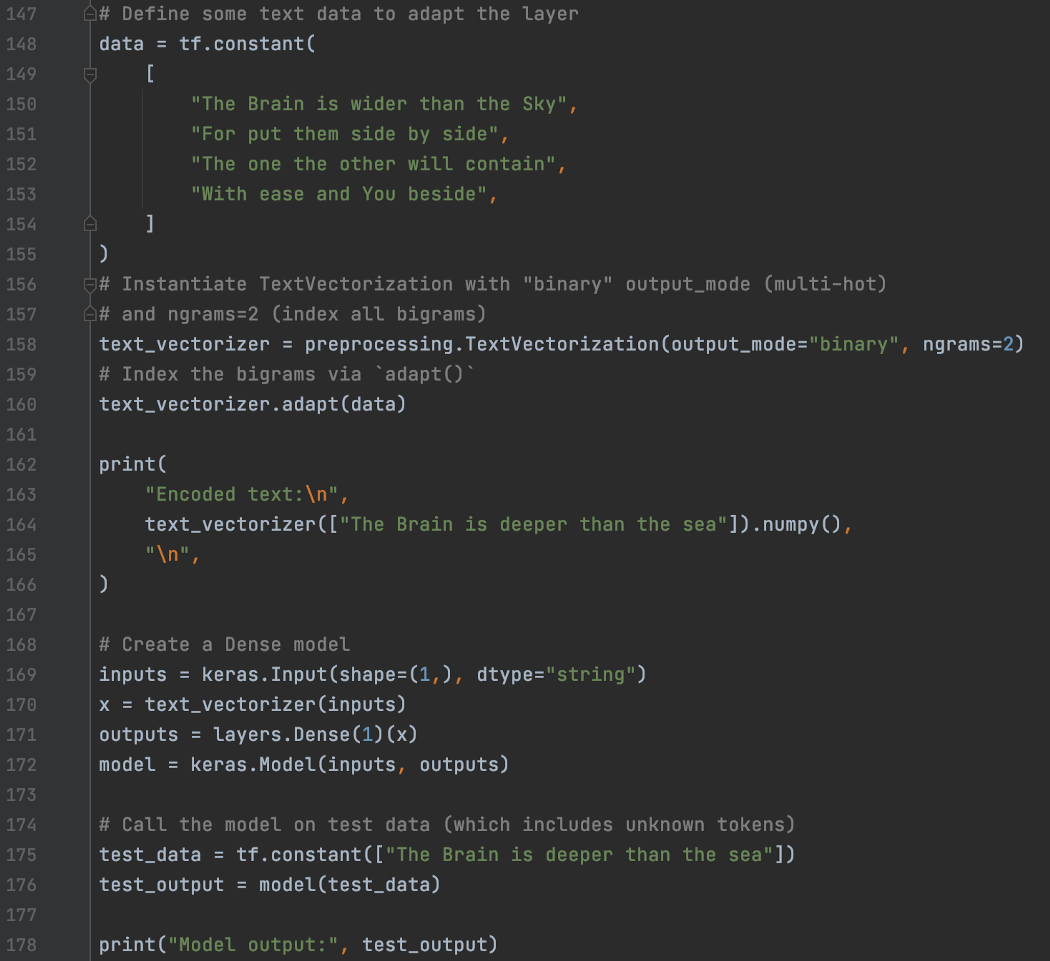
输出模式 默认情况下,TextVectorization 中的 output_mode 为“int”——使用词汇表的整数索引来表示每个单词。 但是还有其他配置。 当它是“二进制”时,它将输入句子编码为一个词袋,向量长度等于词汇表大小(或 max_tokens)。 每个相应的条目将标记输入中单词的存在 (1) 或不存在 (0)。
或者可以将 output_mode 设置为“count”,其中每个条目标记单词的词频 (tf)。
n-gram 在前面的例子中,我们的词汇表只包含一个单词(下面的第一行)。
n-gram 表示 n 个连续的单词。 bigram 表示两个连续单词的 2-gram。 当 TextVectorization 中的 ngrams=2 时,我们的词汇表将包含语料库的单个单词和双连词。 在 output_mode=”binary” 和 ngrams=2 的情况下,最终的词汇表(上面的第二行)将包含下面语料库的 41 个条目。
使用multi-hot编码将文本编码为 ngram 的密集矩阵 这是一个使用二元组构建词汇表并使用二进制输出(词袋)的示例。
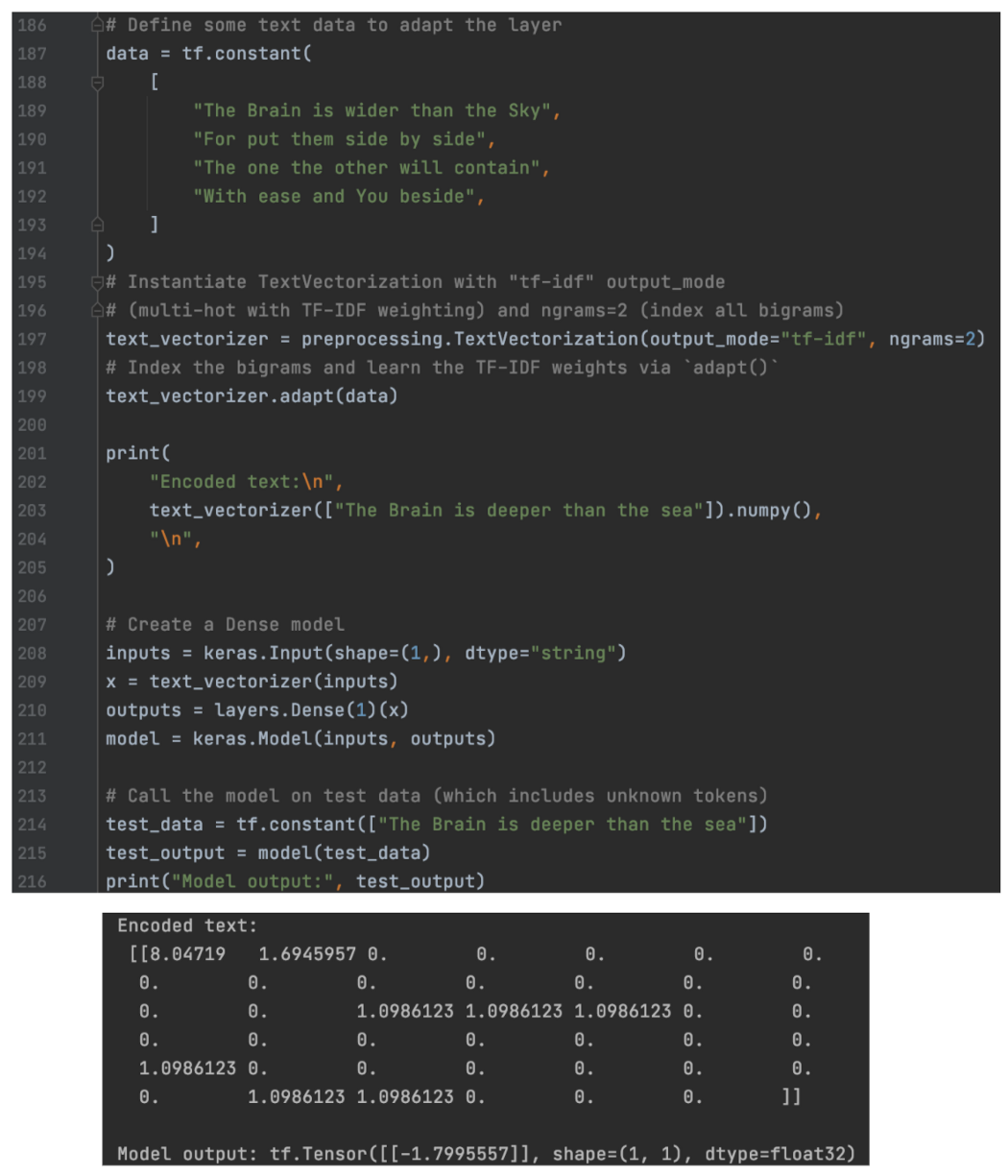
“The Brain is deeper than the sea”被转化为下面包含 0 或 1 的 41 维向量。
该模型使用密集模型将此表示转换为标量值(对于我们的句子示例为 0.7497798)。 使用 TF-IDF 加权将文本编码为 ngram 的密集矩阵 当 TextVectorization 中的 output_mode 为“二进制”时,输出表示一个词袋。 当它是“计数”时,每个条目都会计算词频。 对于 output_mode 等于“tf-idf”,该条目由以下术语频率逆文档频率计算。
这是使用 TextVectorization 和dense层中的 tf-idf 编码为句子构建标量表示的代码。
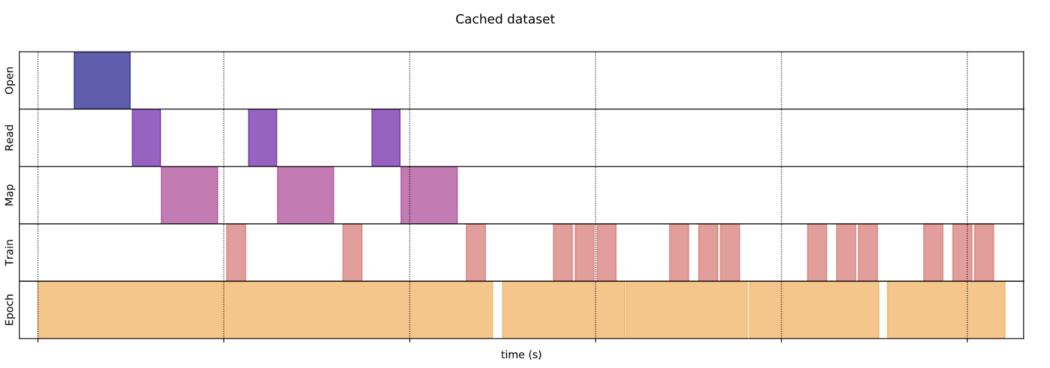
cache & prefetch 为了提高数据吞吐量,我们可以对数据集应用缓存和预取。 dataset.cache 允许将数据缓存在内存或本地存储中。
通过缓存,我们可以消除在第一个 epoch 之后潜在的数据打开和读取。
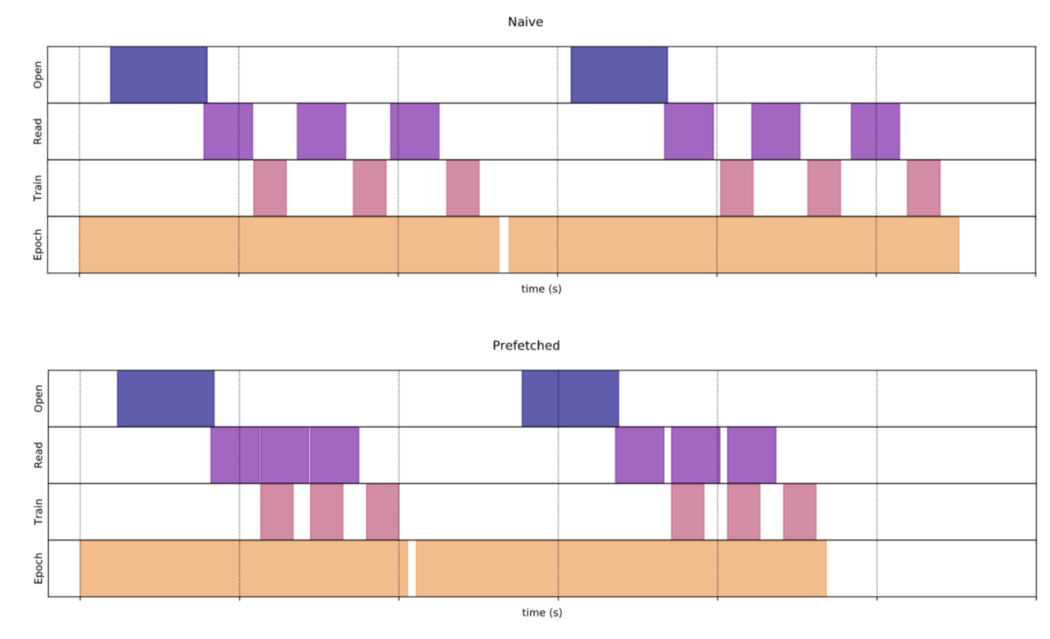
我们也可以通过预取来增加样本吞吐量。 在预取(下图第二张图)中,后台线程甚至在最后一个训练步骤完成之前就开始为下一个训练步骤预取数据。 如第二张图所示,训练和读取中的操作将重叠,以减少不必要的数据等待。
通过这种性能改进,通常的做法是准备具有缓存和预取的数据集。
这是链的顺序,包括随机播放和批处理。
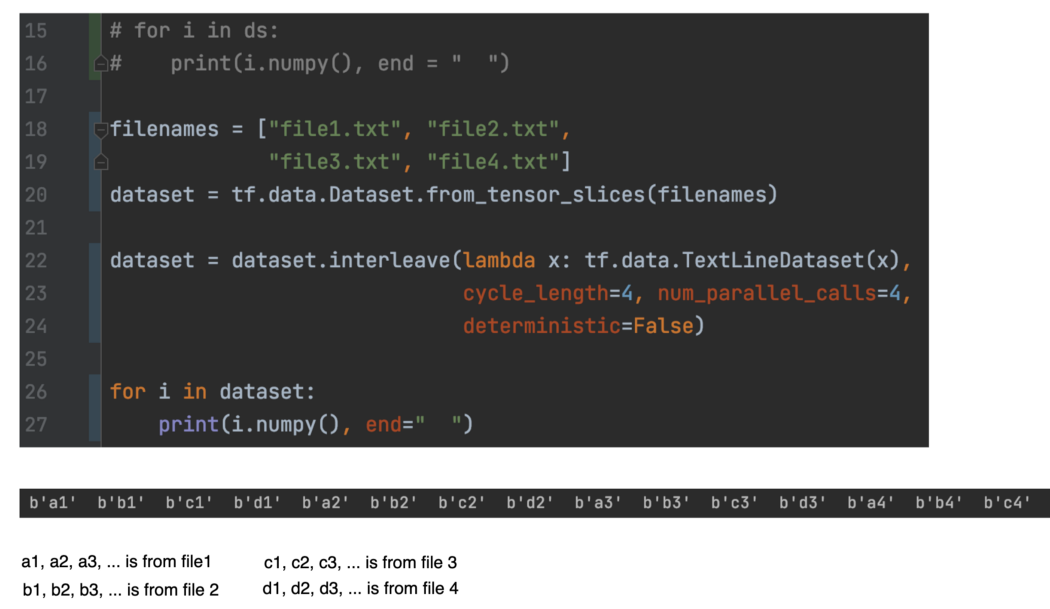
interleave(并行数据提取) dataset.interleave 并行化数据加载并交错数据集的内容(例如数据文件读取器)。 cycle_length 控制将同时处理的输入元素的数量。 通过将其设置为 4,我们允许使用 4 个数据集。 在下面的代码中,它创建了 4 个数据集,每个数据集负责一个文件。
如果我们将 cycle_length 减少到 2,将只有 2 个数据集。 在 file1 和 file2 完成之前,不会加载来自 file3 和 file4 的数据。
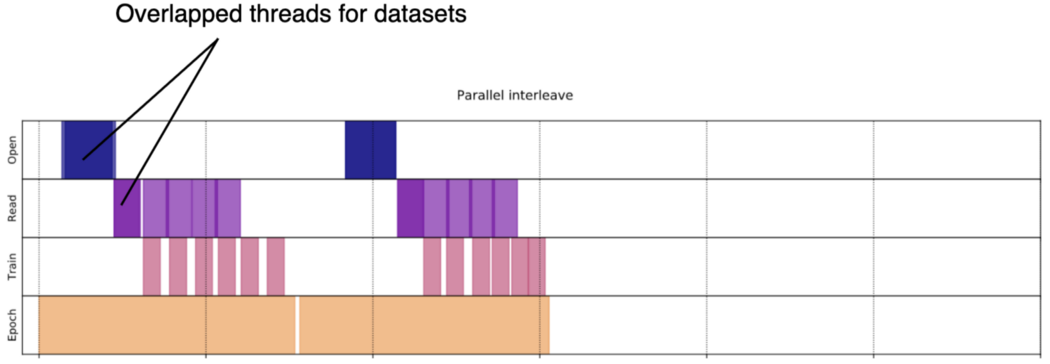
但真正的并行性来自 num_parallel_calls 设置。 它控制获取输入的线程数。 如果是一个,则 4 个数据集只是旋转并等待轮到它们加载数据。 通过将 num_parallel_calls 设置为 4,我们允许它们并行加载数据。 num_parallel_calls 也可以设置为 tf.data.AUTOUNE。 这允许 TF 根据 CPU 容量自动设置它。
下面是另一个使用 2 个数据集生成样本的示例。
当 num_parallel_calls 大于 1 时,多个线程同时读取多个数据集。
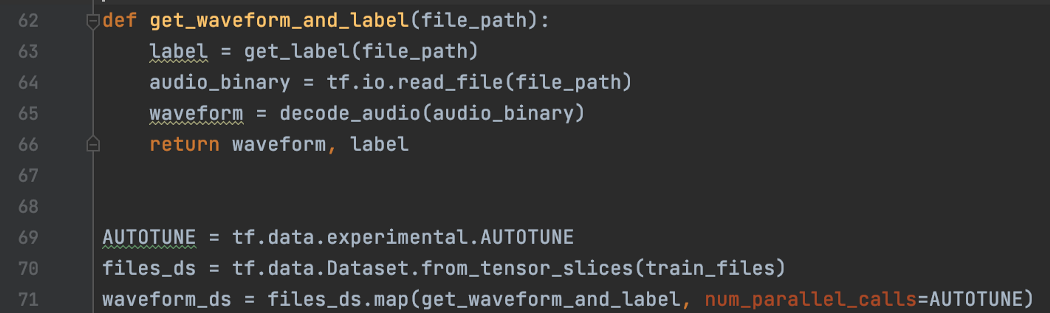
并行化数据转换 我们还可以在数据预处理中并行化数据映射。 在 dataset.map 中,我们将 num_parallel_calls 设置为 AUTOTUNE 以允许并行读取和解码音频文件。
矢量化映射 处理向量中的数据将比逐个处理标量更有效。 在下面的第一个示例中,我们先对样本进行预处理,然后再对其进行批处理。 但在第二个示例中,我们在映射之前将 256 个样本一起批处理。 并且映射将作为更有效的张量向量执行。 因此,即使两者都产生相同的样本,后者的速度也要快 10 倍。 所以要注意batch和map的顺序。
Map & Cache 一般来说,我们希望将缓存放在map之后以避免耗时的映射,除非“map”生成的数据太大。
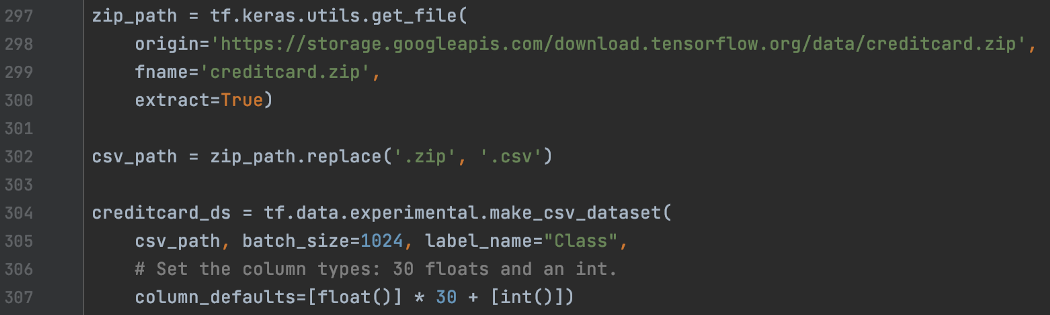
样本再平衡 班级不平衡会损害深度学习训练。 下面信用卡数据集的前 10 批有 99.57% 的样本属于 0 类。
为了重新平衡数据集,我们可以应用过滤器来创建两个单独的数据集,分别保存 0 类和 1 类样本。 然后我们通过将混合指定为 [0.5, 0.5] 来创建平衡数据集,即新数据集具有来自两个类的相同数量的样本。
拒绝重采样 但是,数据会加载两次——每个过滤器加载一次。 另一种解决方案是配置一个拒绝重采样器,指定目标类分布。 class_func 返回来自 creditcard_ds 的数据的类标签部分。 下面的重采样器(第 360 行)将使用它来平衡新数据集的样本。 创建重采样数据集后,我们将创建一个新的数据集,并去除重复的标签(第 369 行)。
|