|
阅读代码是获得 TensorFlow (TF) 专业知识的一种有效方式。 在本文中,我们重用了 TensorFlow 教程中的示例,但我们保持它们的简洁性,并去掉了用于跟踪或演示目的的代码。 我们还将讨论保持在最低限度,以便您可以浏览尽可能多的示例以获得完整的图片。 如果你有问题,特别是在阅读了第一个示例之后,请先阅读本系列的文章。 然而,在大多数示例中,我们保留了示例所需的所有样板代码。 因此,如果需要,请跳过它们。 我们对代码使用照片的形式,因此你无法剪切和粘贴它们,因为可能会更改 TF API。 请参阅示例顶部的链接。 以下是使用 2020 年 12 月发布的 TF 2.4.0 测试的示例列表。
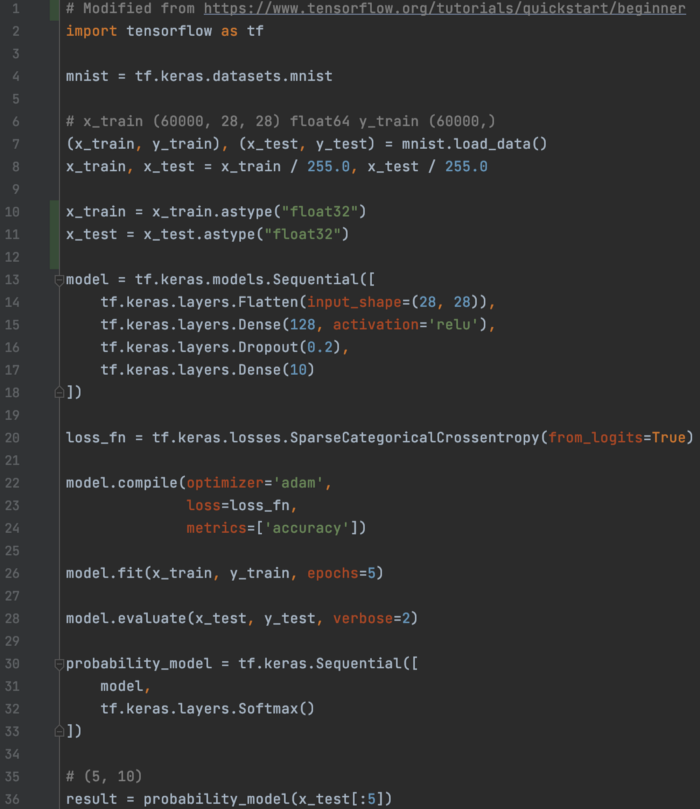
Keras MNIST 数据:使用dense层的序列模型 使用具有dense层的序列模型对 MNIST NumPy 数据进行分类。
模型概要:
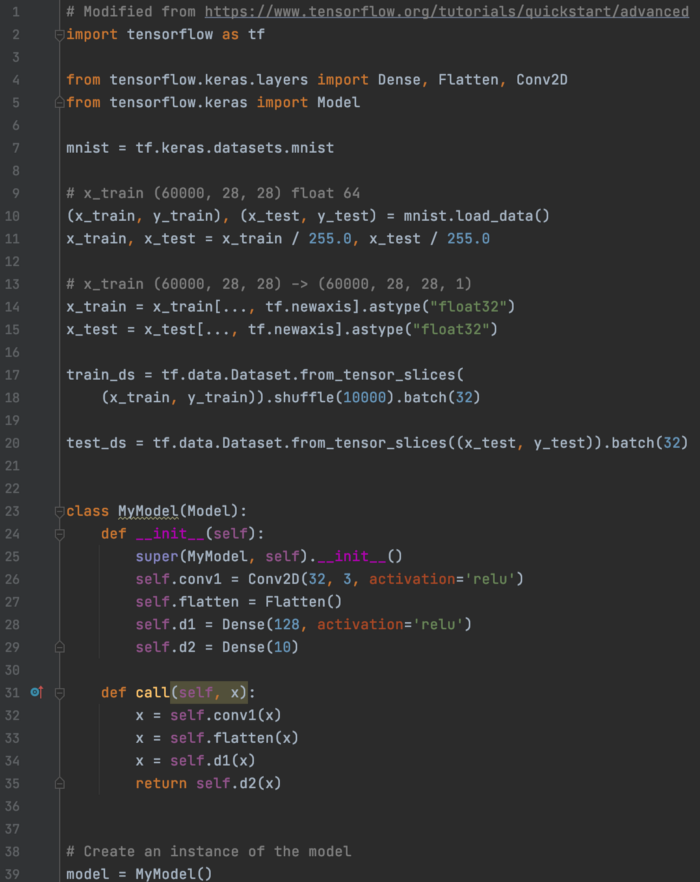
Keras MINST 数据:使用 GradientTape 和数据集训练的自定义 CNN 模型类 在这个例子中,
首先,我们创建数据集并定义自定义 CNN 模型。
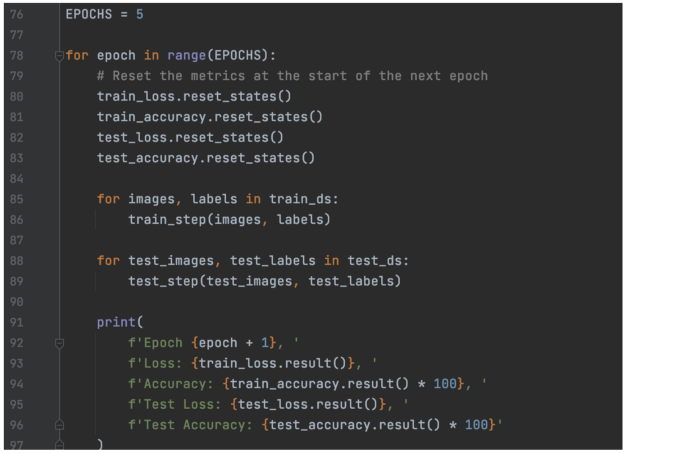
使用 GradientTape 和测试步骤进行自定义训练:
训练循环:
自定义层创建新模型参数 自定义层可以包含其他层和/或具有自己的层参数。 但是,在实例化时可能不知道输入形状。 一旦 TF 知道输入形状,例如通过第一次使用输入调用层,就会调用一个单独的方法“build”来创建参数。
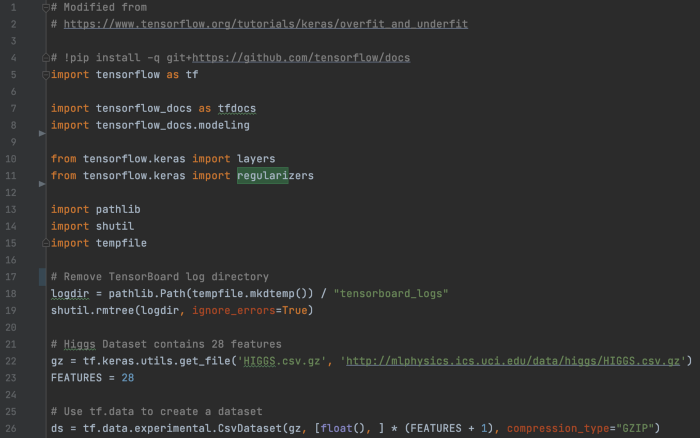
过拟合 在这个例子中:
希格斯玻色子粒子的检测证明了希格斯场的存在,它为基本粒子(夸克、轻子等)提供了质量。 此示例预测事件的类别——“信号”或“背景”。 “信号”表示 4 轻子事件是由涉及希格斯玻色子的衰变发生的。 否则,它是不涉及希格斯玻色子的衰变的“背景”。 首先,我们使用 tf.data 加载一个 CSV 数据集。 每行包含标签和 28 个特征——21 个是粒子探测器测量的运动学特性,7 个是从这些测量中得出的。
创建一个特征和标签分开的数据集——ds 是批处理的,因此映射在单个操作中完成,然后再取消批处理。
创建训练和验证数据集——它使用“take”和“skip”来划分原始训练样本。
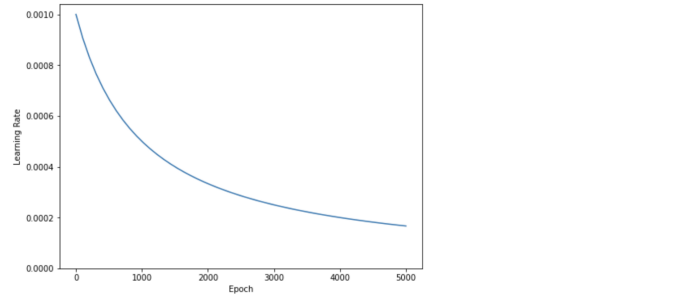
优化器将为优化器使用自定义学习率。
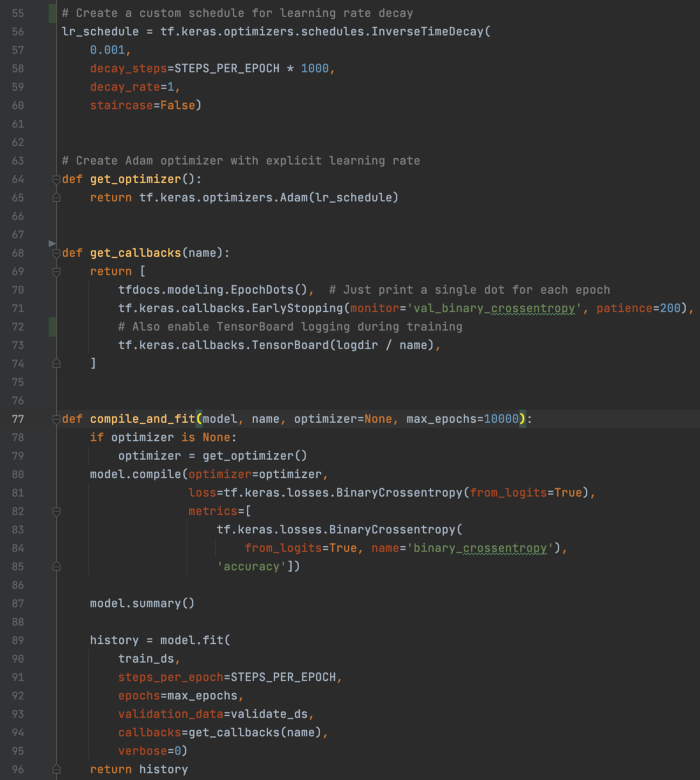
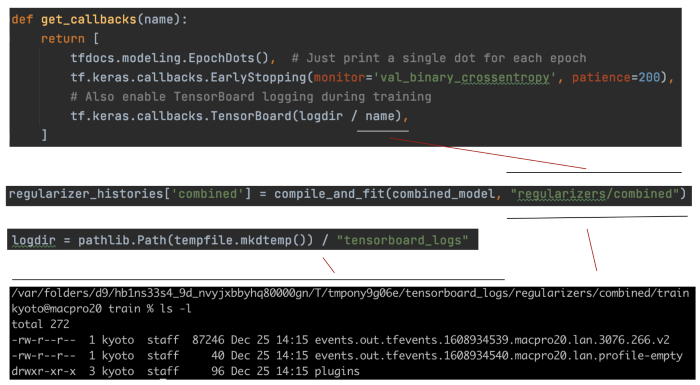
compile_and_fit 将配置训练并拟合模型。 我们还设置了回调来记录 TensorBoard 的数据。
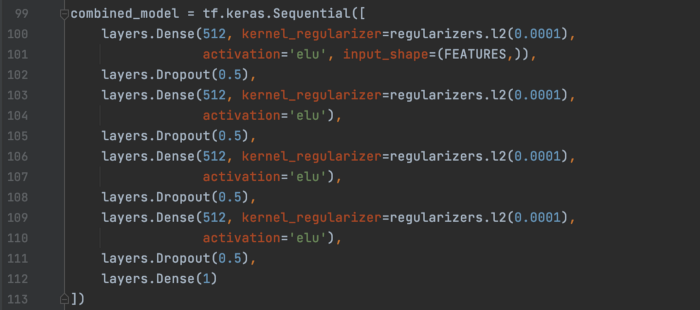
我们建立了一个带有正则化和 dropout 的“组合”模型,以避免过度拟合。
最后,我们训练模型。
我们将此训练和模型(称为组合)的 TensorBoard 数据存储在 $tmp/tensorboard_logs/regularizers/combined 下。 我们可以在不同的director下训练不同的模型,比如正则化器/other_model。
我们可以使用 TensorBoard 在“正则化器”下查看此训练和其他训练的数据。
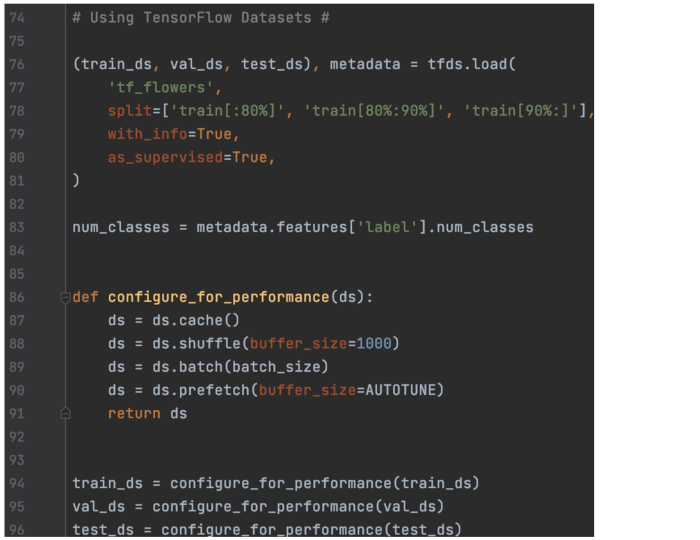
数据集Performance 为了提高数据集的性能,我们应该缓存和预取数据。 但是我们可能不需要洗牌验证或测试数据集。
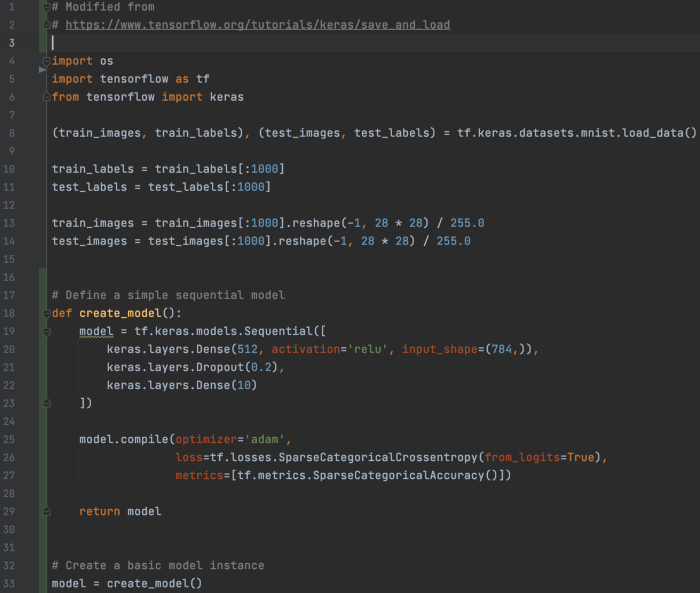
保存和加载 在这个例子中,我们保存和恢复一个模型。 首先,我们有加载 MNIST 数据并创建密集模型的样板代码。
接下来,我们为 model.fit 创建一个回调来保存模型。 对于这些检查点,我们只保存权重。
这是创建的checkpoint。
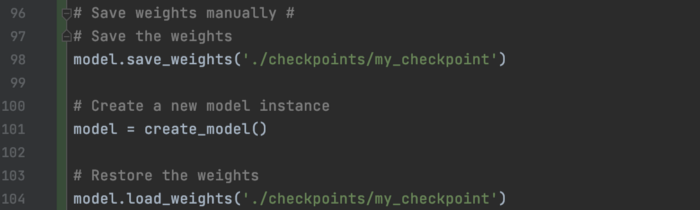
我们可以实例化一个新模型并重新加载权重。
我们可以添加 epoch 编号作为checkpoint文件名的一部分,并且我们可以更改checkpoint的频率(以下每 5 个 epoch)。
这是 50 个 epoch 后的checkpoint。
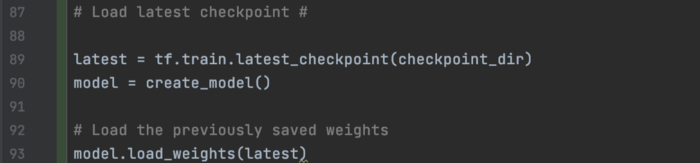
我们可以加载最新的checkpoint:
要手动保存权重:
或者保存整个模型。 在后一种情况下,我们不需要 Python 代码来恢复模型。
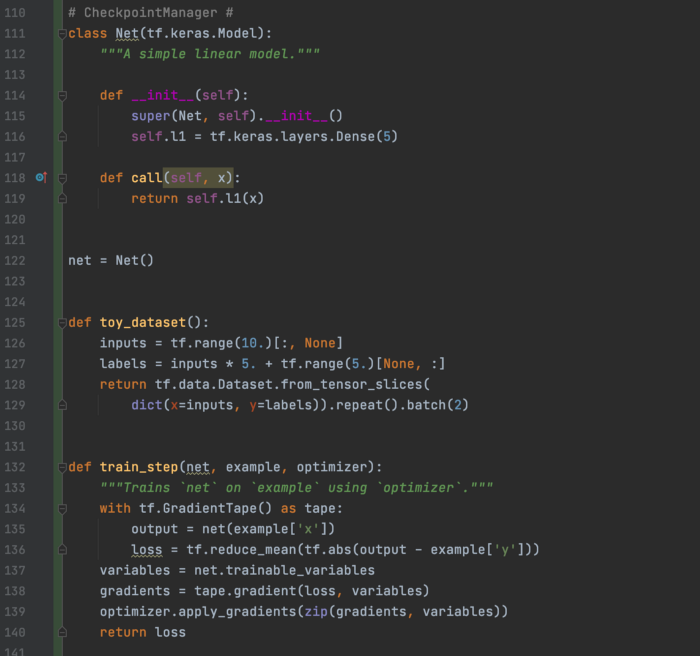
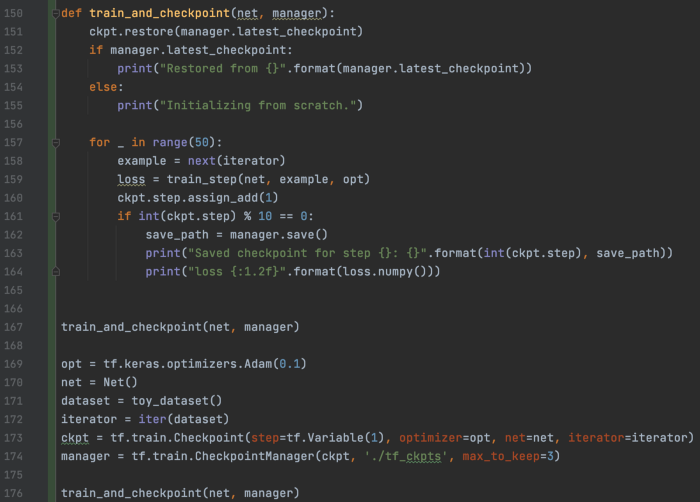
checkpoint管理器 如果我们可以访问优化器和数据迭代器,就像在 GradientTape 中一样,我们可以使用 CheckpointManager 来保存检查点。 这是样板代码。
然后,我们可以配置一个 CheckpointManager。
这包括仅保留 max_to_keep Checkpoint的选项。
我们可以使用它来保存和恢复模型。
使用数据增强层对花朵进行分类 在此示例中,我们使用数据增强来提高模型性能。 准备训练和验证数据集:
使用 Keras 预处理层构建和训练模型:
测试:
使用数据集映射通过数据增强对花朵进行分类 我们使用数据集流水线中的映射来执行数据扩充。 在此示例中,我们执行调整大小、重新缩放、翻转和旋转。 这是用于创建数据集和扩充层的样板代码。
然后,我们使用数据集映射进行数据扩充。
这就是模型和训练。
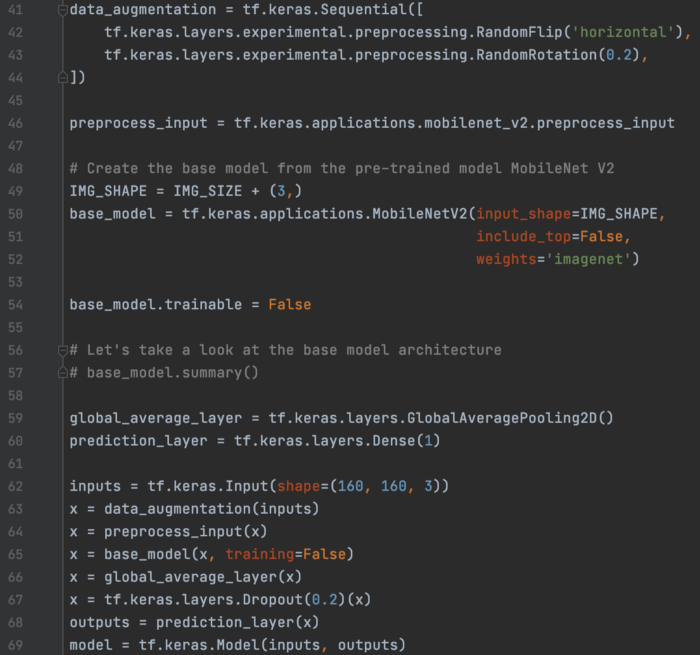
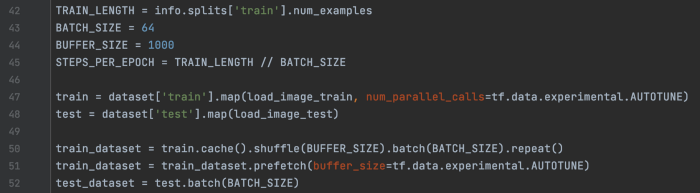
迁移学习 这是在创建数据集时加载猫和狗图片的样板代码。
然后,我们构建了一个模型,其中包含数据增强层、MobileNet v2 的预处理层、预训练的 MobileNet v2 和分类头。 在迁移学习的第一部分,我们冻结 MobileNet v2 层(第 54 行)并仅训练分类头。 我们还将 MobileNet v2(第 65 行)的训练设置为 False,以便它将在推理模式下运行:将不应用 dropout 层,它使用原始训练均值和方差进行批量标准化。
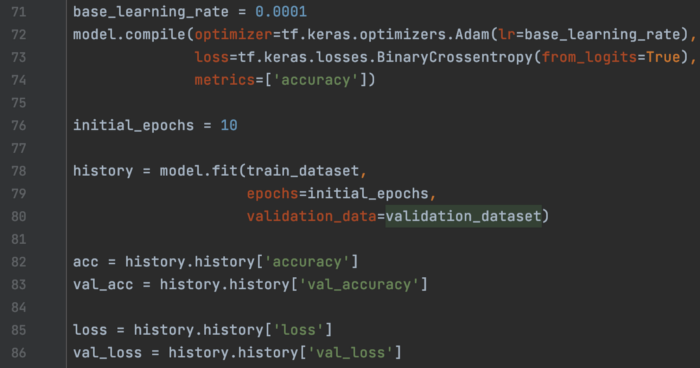
接下来,我们训练模型,
现在,我们进入训练的第二阶段。 我们只会冻结 MobileNet v2 的前 100 层,并再次微调模型的其余部分。
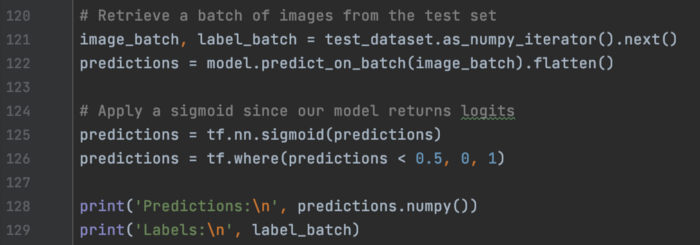
一旦它再次被训练,我们就用它来预测测试图像。
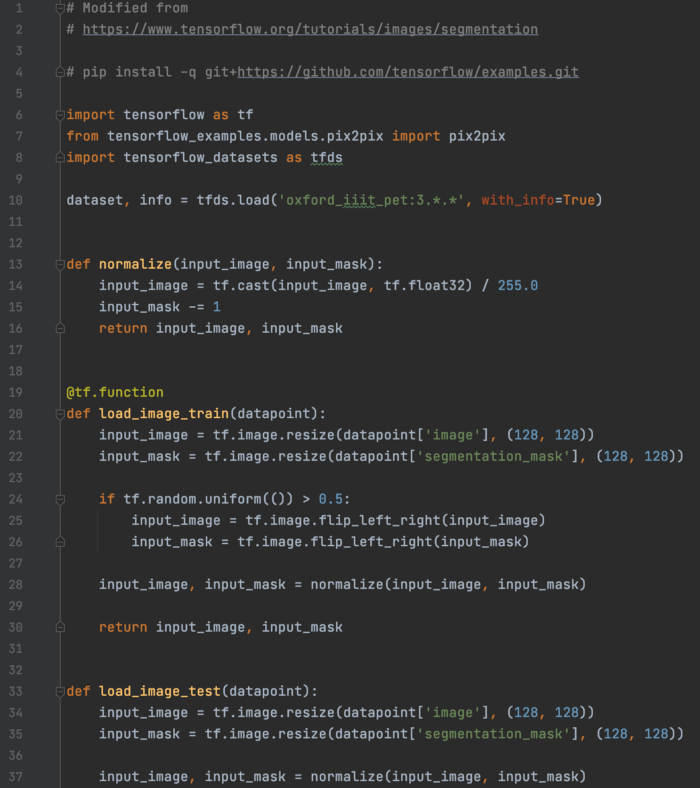
图像分割 图像分割创建一个mask来分割一个对象。
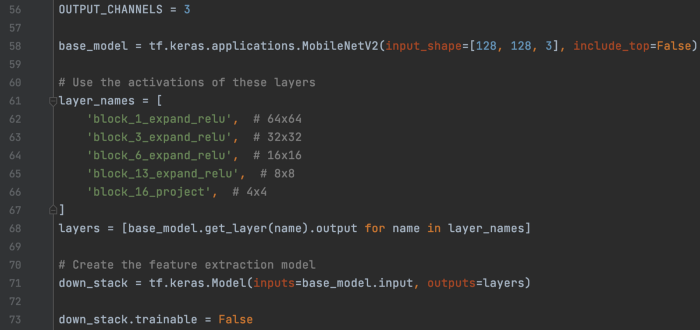
首先,我们加载数据集并创建预处理层。
然后,我们创建数据集。
图像分割模型包含下采样层,然后是上采样层。 这是下采样。
和上采样部分。
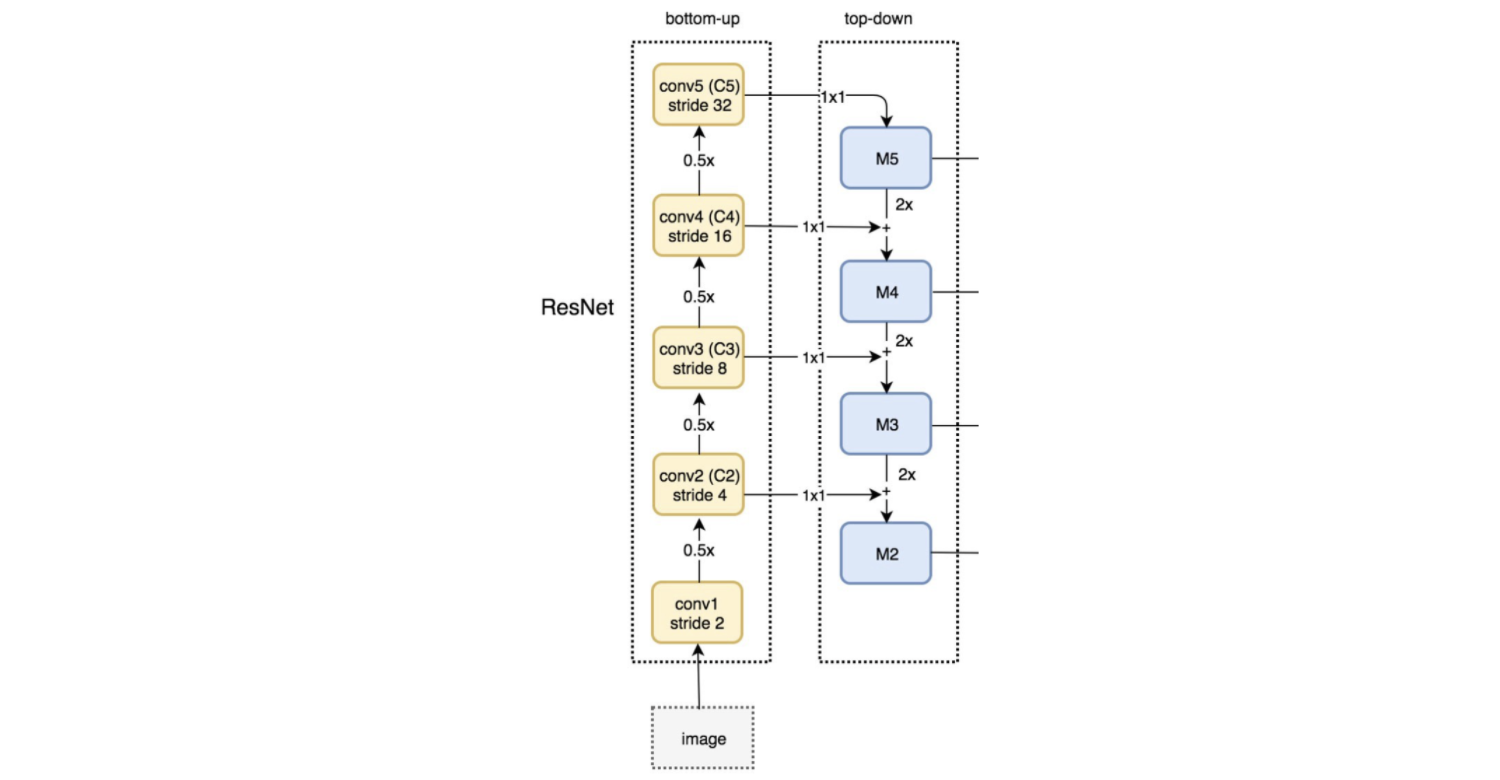
上面更复杂的逻辑处理下采样层和上采样层之间的跳过连接——下采样层和下面的上采样层之间的水平连接具有相同的空间分辨率。
这是更精确的图表。
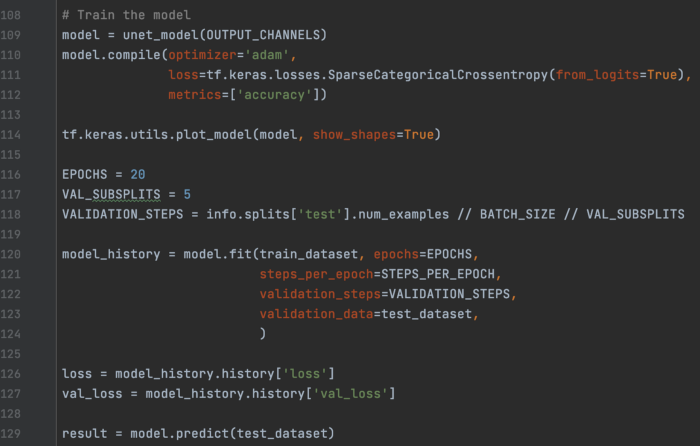
最后,我们训练模型并进行预测。
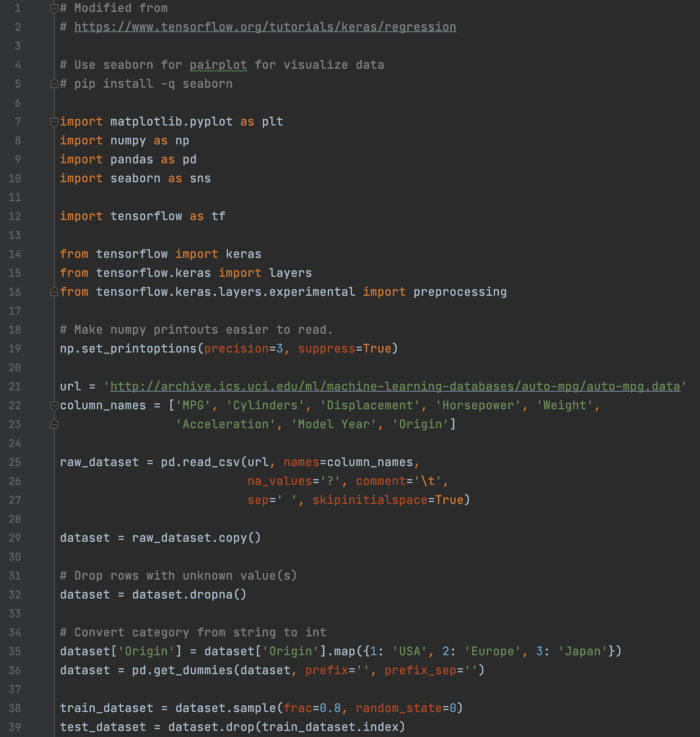
CSV 文件的回归:使用 Pandas 处理数据 此示例是一个简单的回归问题,用于根据 CSV 文件中包含的特征预测汽车的 MPG。 使用 Pandas 为 CSV 文件准备数据集:
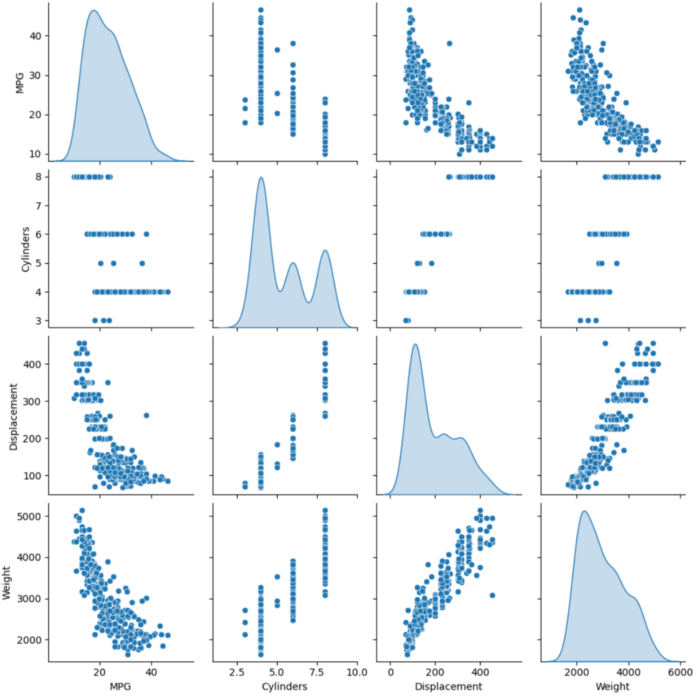
可视化特征相互关系。
创建 training/testing features/labels.
创建具有Normalization层的模型以normalize每个特征。
fit、评估和预测:
保存并加载模型:
模型将保存为:
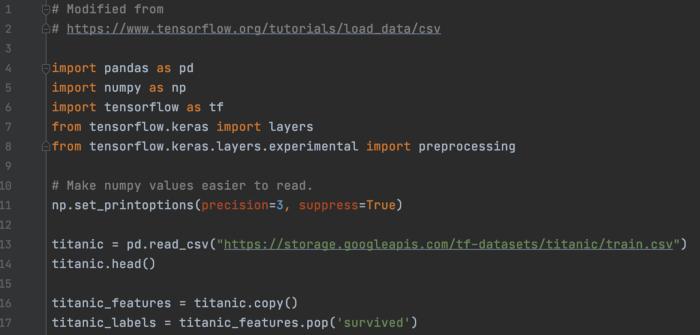
CSV 预处理 在这个例子中,我们将预测谁将在泰坦尼克号事故中幸存下来。 此示例演示如何预处理 CSV 数据。 首先,我们将从 CSV 文件加载数据。
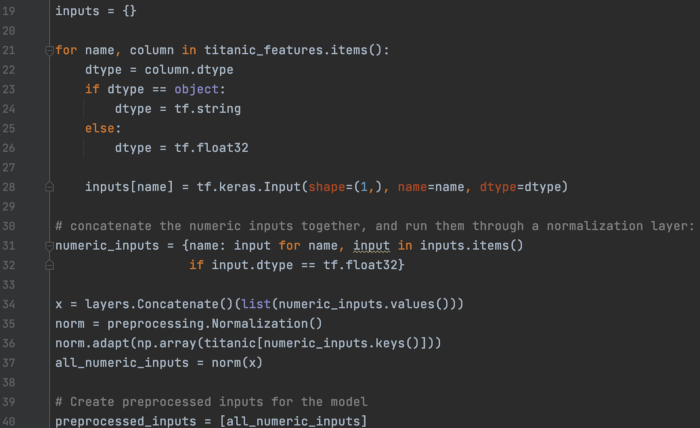
我们收集所有数字字段,对其进行规范化,并将它们放入 preprocessed_inputs。
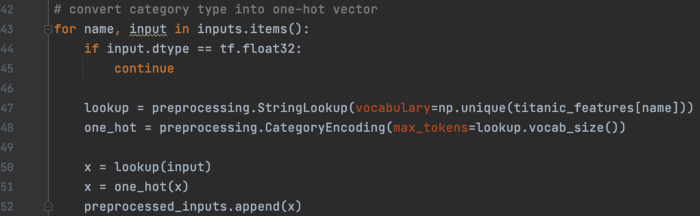
将所有类别字段转换为 one-hot 向量并将它们附加到 preprocessed_inputs 中。
Concatenate所有输入并创建预处理模型。
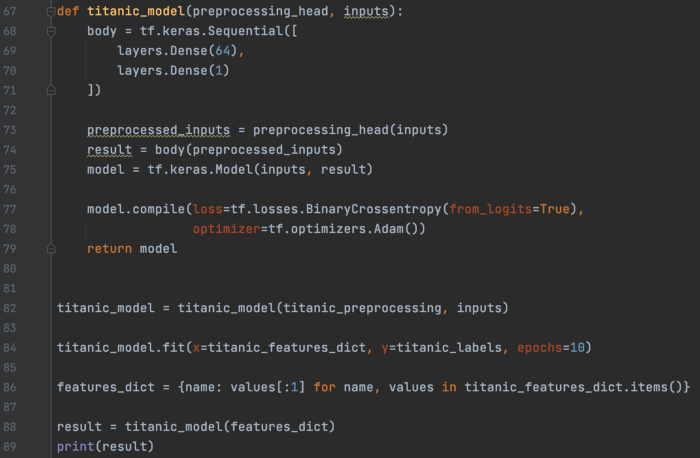
创建分类模型。 训练并做出预测。
|